






注:本文是从kaggle官方教程Titanic Data Science Solutions翻译过来的,原则上这并不是一篇翻译文章,因为我们并没有完全的忠实于原文,权当一份注解文档更为恰当。如果有不到之处,还望谅解。如有问题,请联系hzsong@outlook.com。
一般的工作流程
- 定义问题
- 获取训练和预测数据
- 清洗数据
- 分析、识别模式并探索数据
- 建立模型,预测数据,解决问题
- 可视化工作
- 提交答案
问题的定义
给你一组训练数据,里面包含性别、年龄、是否存活等特征,根据这组训练数据进行数据分析,建立模型,评估模型,选择一种模型来预测另一组测试数据(其中不包括是否存活特征)每个样本的存活特征是0还是1。详见Kaggle。
数据假设
从题目描述中得到的假设
- 女人的存活率比较高
- 儿童(age<
?)的存活率比较高- 上层阶级(Pclass=1)的存活率比较高
工作目标
Classifying:
分类,我们需要理解不同分类与我们的目标之间的关系。
Correlating:
相关度,我们需要了解每个特征对目标的贡献值,也就是相关度,要了解是否具有相关性,是正相关还是负相关或者其他。
Coverting:
转换,我们根据不同的模型需要可能需要把某特征的类型转变为合适的类型,比如将String类型转变为数值类型。
Completing:
补全,我们需要为某些特征的缺少值插入合适的值,以方便建模
Correcting:
修正,我们需要修正某些特征可能存在的一些不正确的值,比如年龄大于四百,这显然是不正确的
Creating:
创新,我们可以根据需要利用现存的一些特征勾勒出一个或几个全新的特征。
Charting:
图表,我们使用可视化的图表来揭示数据和目标之间的内涵。详见如何选择正确的图表。
分析数据
# data analysis and wrangling
import pandas as pd
import numpy as np
import random as rnd
# visualization
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# machine learning
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier获取数据
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
combine = [train_df, test_df]初步观察数据
# preview the data
train_df.head()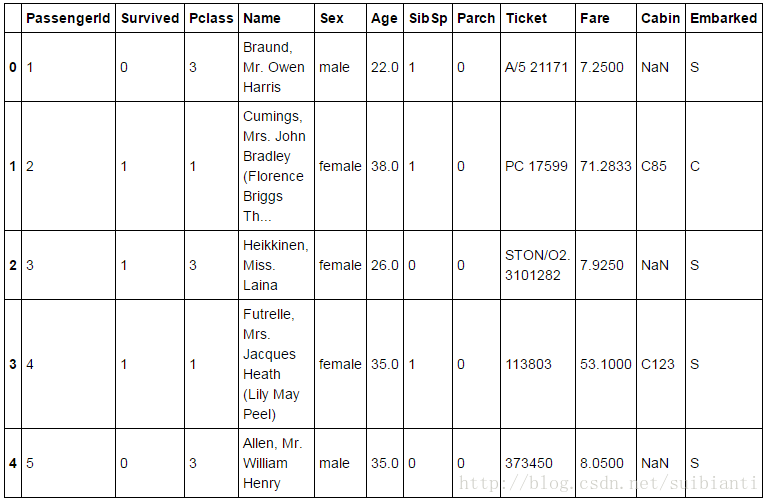
train_df.tail()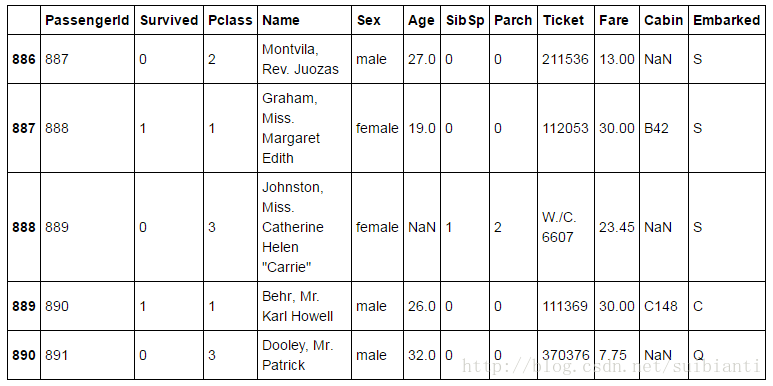
特征分类
Categorical
Categorical:Survived, Sex
Ordinal:Pclass
Numerical
Continue:Age
Discrete:SibSp,Parch
Mixed data types
Ticket is a mix of numeric and alphanumeric data types. Cabin is alphanumeric
Errors or typos
Name feature may contain errors or typos
总体特征观察
train_df.info()
print('_'*40)
test_df.info()–
缺失值
训练数据(891):Cabin(204),Age(714),Embarked(889)
测试数据(418):Cabin(91),Age(332)
特征类型
训练数据:7个特征,5个特征类型为String
测试数据:6个特征,5个特征类型为String
查看数据分布
数值类型数据分布
train_df.describe()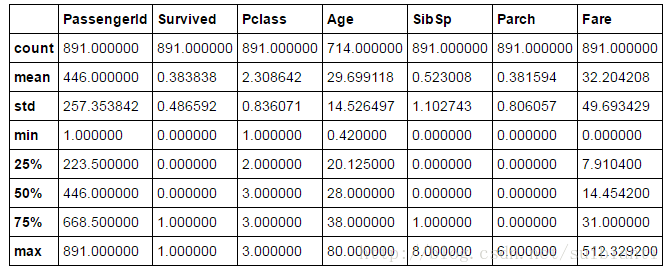
-
结论
- a. 不到1%的乘客的年龄在65-80。(Age)
- b. 大多数乘客(>75%)没有携带家属。(SibSp,Parch)
- c. 票价差异很大,只有不到1%的乘客购买了512$的票(Fare)
离散类型数据分布
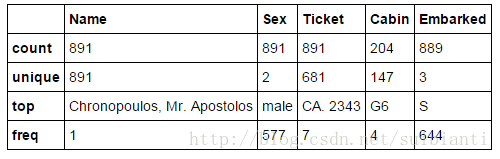
train_df.describe(include=['O'])- a. Name特征的取值是唯一的。(count=unique=891)
- b. Sex特征只有两个取值,其中65%为male。(top=male, freq=577/count=891)
- c. Tickect特征办含有22%的数据冗余。(count=891,unique=681)
- d. Cabin特征的取值有一些冗余值。(count=204,unique=147)
- e. Embarked特征的取值只有三个,出现最多的是‘S’
 结论
结论
通过图表进行数据分析
各个离散型特征和Survived的相关性
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)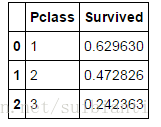
train_df[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)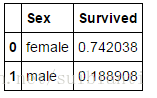
train_df[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)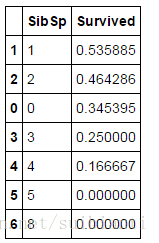
train_df[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)- Pclass,我们观察到Pclass=1和Suvived具有相当大的关联度(>0.5),因此我们使用这个特征来建模。
- Sex,我们观察Sex=female存活的概率高达74%。因此我们使用这个特征来建模。
- Sib Sp 和 Parch,我们观察到这两个特征和Survived关联度不大,因此我们可能需要利用其创建一个新的特征Family。
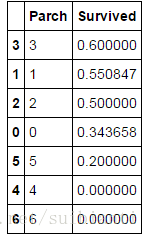 结论
结论
连续型特征和Survived的相关性
Age与Survived特征的相关性
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)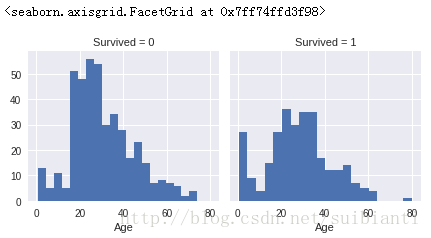
-
观察
- a. 婴儿(age<4)具有较大的存活率
- b. 年长者(age=80)可以存活。
-
c. 大量的青年(15<
age<25)没有存活。 - d. 乘客的大部分年龄为15-35 结论
- a. 我们应该使用Age特征来进行建模
- b. 我们应该根据年龄进行分组
Numerical,Ordinal 特征和Survived的相关性
Pclass, Age和Survived特征的相关性
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();- a. Pclass=3的乘客最多,但是大部分都没有存活
- b. Pclass=2和Pclass=3的婴儿大部分多存活
- c. Pclass=1的多部分乘客都存活下来了
- d. 乘客的Pclass特征对应不同的Age特征分布 结论
- 我们应该考虑Pclass特征进行建模
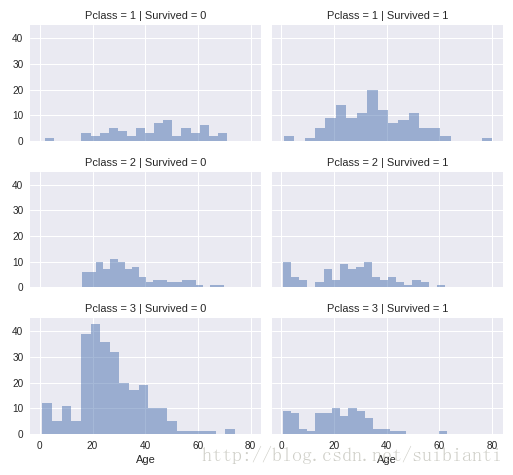 观察
观察
所有离散型特征和Survived的相关性
Embarked, Pclass, Sex和Survived特征的相关性
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()- a. 女性乘客的存活率高于男性
- b. 除了Embarked=C中男性高于女性的存活率,但是这可能是与Pclass和Embarked特征相关,而不是Embarked与Survived有直接相关性。
- c.在C和Q港口,Pclass=3的男性存活于比Pclass=2的高
- d. 登陆港口的存活率读对应Pclass=3的男性乘客 结论
- a. 增加Sex特征进行模型训练
- b. 补全Embarked特征来进行模型训练
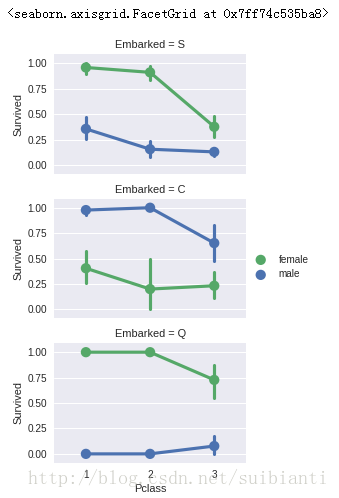 观察
观察
离散型特征,连续型特征和Survived的相关性
Embarked, Sex, Fare和Survived特征的相关性
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()- a. 船票价比较高的存活率比较高
- b. 登陆口与Survived有相关性 结论
- a. 考虑对Fare进行分组
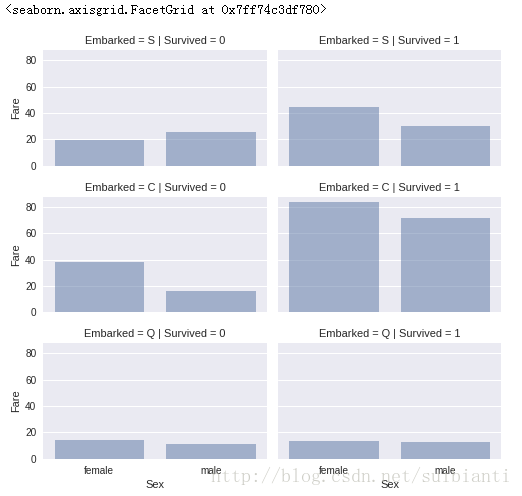 观察
观察
数据分析结论
Correlating:
我们了解每个特征或者几个特征组合与Survived特征的相关度
Coverting:
我们需要将Sex,Embarked特征的类型转变为Ordinal类型。
Completing:
- 我们应该补全Age特征的取值
- 我们应该补全Embarked特征的取值
Correcting:
- 我们应该去除Ticket特征,因为其冗余度很大,而且与Survived特征没有很大的关联
- 我们应该去除Cabin特征,因为在训练集和测试集中其都存在着大量缺失值
- 我们应该去除PassengerId特征,因为它和Survived特征没有关联
- 我们应该去除Name特征,因为其相对来说数据不够规范,而且与Suvived特征没有直接关系。
Creating:
- 我们应该根据Parch和SibSp特征创建Family特征,来表示每个人所属的家庭的成员总数
- 我们应该从Name特征提取Title来创建一种新的特征
- 我们应该创建新特征来表示Age分组
- 我们应该创建新特征来表示Fare分组
特征处理
删除冗余特征
删除Ticket和Cabin特征
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]创建新的特征
创建Title特征
提取Title信息,并进行观察
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])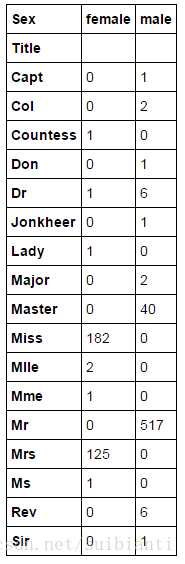
调整Title取值
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()- a. 大部分的titles都可以聚集成祖
- b. Title特征和Survived相关
- c. 特定的titles存活下来了(Mme, Lady, Sir) 结论
- a. 我们采用Title特征来进行模型训练
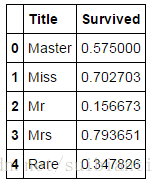 观察
观察
将Titles特征的类型转化为Ordinal
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
创建IsAlone特征
提取Family 特征
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)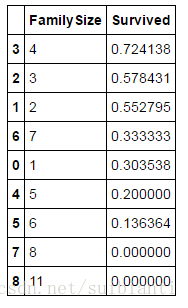
Family Size特征和Survived相关度不大,那么我们重新生成一个新的特征IsALone
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()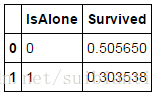
删除Parch,SibSp和FamilySize特征
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()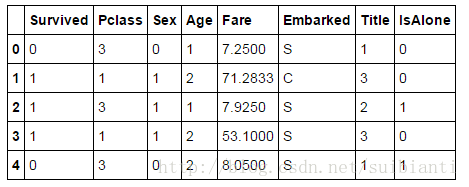
创建Pclass*Age特征
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)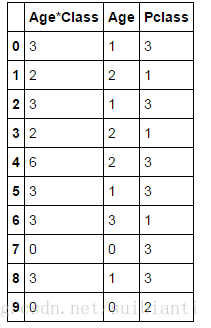
填补缺失值
补全Age特征值
-
连续型特征值补全方法一般有一下三种:
- a. 使用平均值和均方差之间的随机数
- b. 利用相关特征获取特征的中位数,比如要补全Age的值,可以使用Pclass=1和Gender=0,Pclass=2和Gender=1,…Age的中位数来补全。
- c. 结合a和b方法,使用用Pclass和Gender组合特征的Age特征介于平均值和均方差之间的随机数来填补
我们采用第二种方法,因为其他方法都会引来随机干扰。
guess_ages = np.zeros((2,3))
guess_ages
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
# Convert random age float to nearest .5 age
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()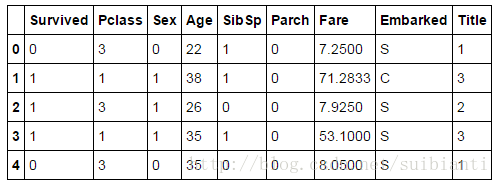
我们为Age特征创建分组
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)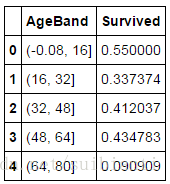
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train_df.head()
最后删除AgeBand特征即可
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()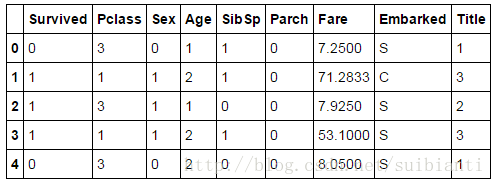
补全Embarked特征
使用出现最频繁的登陆口来补全Embarked特征
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)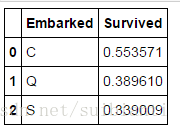
将Embarked特征值转变为Odinal
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()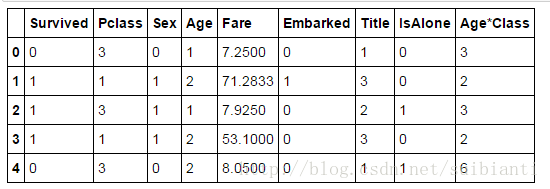
补全Fare特征
使用中值补全测试集的Fare特征
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()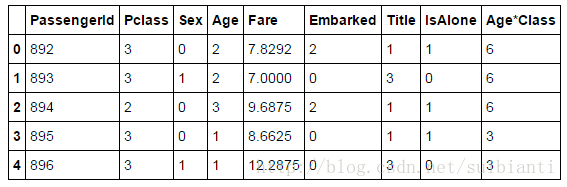
我们为Fare创建分组
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)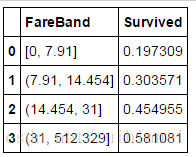
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]最终结果
训练集
train_df.head(10)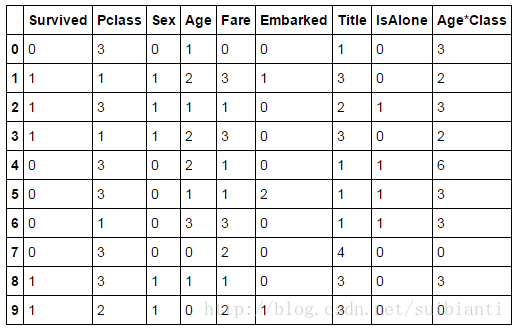
测试集
test_df.head(10)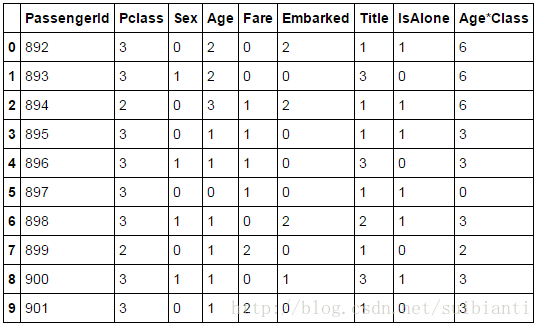
创建模型,预测并解决问题
数据准备
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()各个模型训练
模型如下:
- Logistic Regression
- KNN or k-Nearest Neighbors
- Support Vector Machines
- Naive Bayes classifier
- Decision Tree
- Random Forrest
- Perceptron
- Artificial neural network
- RVM or Relevance Vector Machine
# Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
# k-Nearest Neighbors
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
# Gaussian Naive Bayes
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
# Linear SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
# Stochastic Gradient Descent
sgd = SGDClassifier()
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
# Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
# Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest模型评价
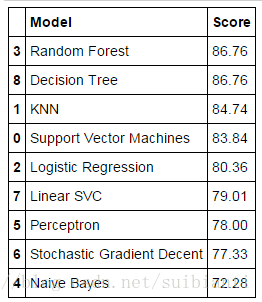
models = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree'],
'Score': [acc_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_linear_svc, acc_decision_tree]})
models.sort_values(by='Score', ascending=False)- 我们使用Random Forest模型作为最终的模型
 结论
结论
提交答案
最终,我们可以提交答案了
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('submission.csv', index=False)













 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









