






 本文详细介绍了如何在PyTorch中构建和训练YOLOv4目标检测模型,包括网络结构实现、数据准备、损失函数选择、模型训练与评估,以及实际应用的过程。
本文详细介绍了如何在PyTorch中构建和训练YOLOv4目标检测模型,包括网络结构实现、数据准备、损失函数选择、模型训练与评估,以及实际应用的过程。
YOLOv4是一种高效的目标检测算法,具有快速、准确的特点,适用于各种场景的目标检测任务。通过本文的指导,将了解如何在PyTorch中搭建和训练一个YOLOv4模型,并将其应用于实际的图像识别任务中。
1. YOLOv4简介
YOLOv4(You Only Look Once,v4版)是YOLO系列目标检测算法的最新版本,它采用了一系列创新的设计和优化,包括特征金字塔网络、跨尺度特征融合等,使得模型在速度和准确度上都有了显著的提升。
2. 准备工作
在开始实现之前,进行一些准备工作:
安装PyTorch和相关的深度学习库。
下载YOLOv4的预训练权重和配置文件。
准备数据集,并进行标注和预处理。

3. 实现YOLOv4模型
搭建YOLOv4模型的网络结构。在PyTorch中,可以使用nn.Module来定义网络模型,并根据YOLOv4的结构实现相应的网络层和模块,包括卷积层、残差模块、池化层等。
4. 数据加载与预处理
实现数据加载器,并对数据进行预处理。可以使用PyTorch提供的Dataset和DataLoader来加载数据集,并编写相应的数据预处理代码,包括图像的缩放、裁剪、归一化等操作。

5. 损失函数与优化器
在训练模型之前,定义损失函数和优化器。YOLOv4通常使用的损失函数包括目标检测任务中常用的交叉熵损失、坐标损失、IOU损失等。
6. 模型训练与评估
一切就绪后,开始训练YOLOv4模型,运行get_map.py文件。通过迭代数据集,不断调整模型参数,直到模型收敛并达到满意的效果。训练过程中,可以使用验证集对模型进行评估,以便及时调整超参数和模型结构。
7.模型应用与部署
运行train.py文件:

8.模型结果
运行predict.py文件,测试模型是否可以目标检测,然后输入需要检测的图片路径(img文件目录下的图片),如输入./jpg/111.jpg,进行检测即可。
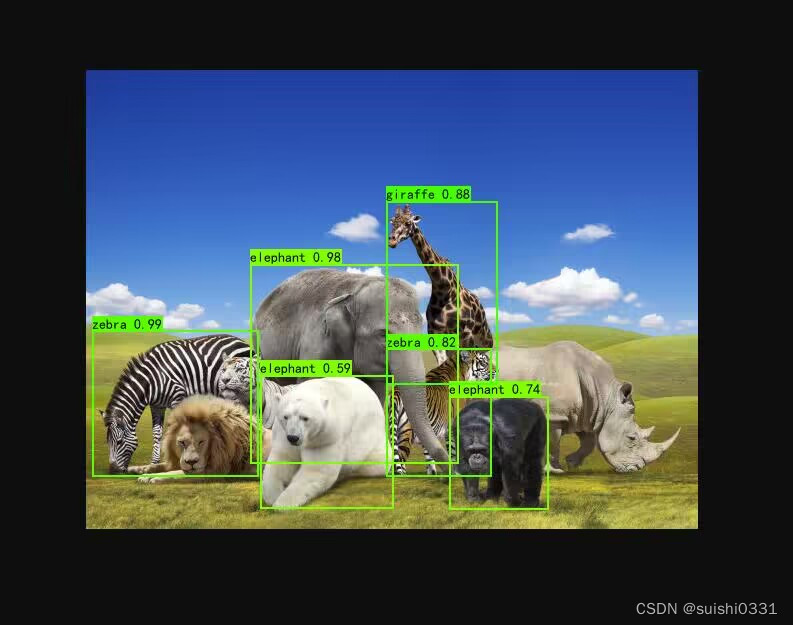
9.实验小结
使用PyTorch实现YOLOv4图像识别是一项挑战性的任务,但通过一系列步骤和技术,可以顺利完成。首先,我们需要了解YOLOv4的基本原理和网络结构,以及PyTorch框架的基本用法。接着,我们进行了准备工作,包括安装必要的库、下载预训练权重和配置文件,以及准备数据集并进行标注和预处理。
在实现YOLOv4模型时,我们利用PyTorch的nn.Module来定义网络结构,并根据YOLOv4的设计思想实现相应的网络层和模块,如卷积层、残差模块等。在数据加载与预处理阶段,我们使用PyTorch提供的Dataset和DataLoader来加载数据集,并编写预处理代码,如图像的缩放、裁剪、归一化等操作,以满足模型训练的需求。
定义损失函数和优化器是模型训练过程中的关键步骤。根据YOLOv4的特点,我们选择了适合目标检测任务的损失函数,如交叉熵损失、坐标损失、IOU损失等,并使用Adam或SGD等优化器进行参数优化。在模型训练与评估阶段,我们迭代数据集,不断调整模型参数,直到模型收敛并达到预期的效果。同时,通过验证集对模型进行评估,及时调整超参数和模型结构,以提高模型的泛化能力。
最后,我们可以将训练好的模型应用于实际的图像识别任务中。通过加载模型权重,并对图像进行推理,我们可以实现目标检测功能,并将其集成到应用程序或项目中,为用户提供便捷和高效的图像识别服务。















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









