







本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍:https://blog.csdn.net/suiyingy/article/details/146983582。
1 大模型智能体构建步骤
在智能体的生命周期开始阶段,我们需要进行详细的需求分析。明确智能体的目标用户群体、应用场景、主要功能和性能指标等。例如,若要构建一个对话智能体,需要确定其服务的用户是普通消费者还是企业客户,应用场景是在线客服、智能助手还是娱乐互动等,主要功能包括回答问题、提供建议、完成特定操作等,同时还要确定响应时间、准确率等性能指标。通过与用户、利益相关者的沟通和调研,收集详细的需求信息,并对这些需求进行分析和整理,形成明确的需求规格说明书,为后续的设计和开发提供依据。
根据需求分析的结果,设计智能体的整体架构,包括选择合适的大模型,确定智能体的模块组成,如自然语言处理模块、决策模块、记忆模块、工具调用模块等,以及各模块之间的交互方式和数据流动路径。然后,我们需要设计智能体与用户的交互方式,包括对话界面、输入输出形式(如文本、语音、图像等)、对话流程和用户体验等。例如,确定对话智能体的回复风格是正式、友好还是幽默,设计合理的对话流程,使交互更加自然、流畅。
此外,设计时确定智能体所需的知识和数据来源,设计知识表示和存储方式。对于需要处理特定领域知识的智能体,如医疗智能体、金融智能体等,我们需要收集和整理相关领域的专业知识,并构建知识库。同时,确定数据的获取、清洗、预处理和存储方法,为智能体的训练和运行提供高质量的数据支持。
大模型类别众多,性能与功能各有侧重。根据智能体的需求和应用场景,开发需要选择合适的大模型,并且决定是都需要对大模型进行微调,使用特定领域的数据集对模型进行训练,使其适应特定的任务和场景。例如,医疗智能体使用医疗领域的病历、医学文献等数据对大模型进行微调,使其能够准确理解和处理医疗相关的问题。
当需求、架构、数据等确定以后,接下来需要开发各个模块。自然语言处理模块实现语言的理解和生成功能,决策模块根据输入信息和目标进行决策;记忆模块管理智能体的历史对话和状态信息;工具调用模块实现与外部工具和服务的交互等。
开发完成之后,各个模块需要集成到智能体中进行全面的测试。功能测试用于验证智能体是否满足需求规格说明书中的各项功能;性能测试用于检测智能体的响应时间、吞吐量、稳定性等性能指标;用户体验测试用于收集用户的反馈意见,优化智能体的交互体验。
最后,将开发完成并通过测试的智能体部署到实际的运行环境中,如服务器、云端平台等。根据部署环境的要求,程序需要进行相应的配置和优化,确保智能体能够稳定、高效地运行。同时,制定上线计划,进行上线前的准备工作,如数据迁移、用户通知等,确保智能体顺利上线并为用户提供服务。在智能体运行过程中,实时监控其运行状态和性能指标,如响应时间、错误率、用户满意度等。定期对智能体的性能进行评估,根据评估结果及时发现问题并进行调整和优化。智能体运行过程中需要重视安全和隐私保护问题。采取必要的安全措施,防止智能体受到攻击和恶意利用,保护用户的个人信息和数据安全。例如,对用户输入的敏感信息进行加密处理,限制智能体对敏感数据的访问和使用。
随着用户需求的变化、技术的发展和数据的积累,智能体需要进行持续的更新和迭代。更新内容包括大模型的升级、模块功能的增强、知识和数据的更新等。智能体通过不断迭代保持良好的性能和竞争力,更好地满足用户的需求。
2 基础智能体示例 - 对话智能体
对话智能体主要通过自然语言与用户进行交互,能够理解用户的意图,进行闲聊、回答问题、提供建议等。它具有较强的语言理解和生成能力,能够根据上下文进行连贯的对话,并且可以通过学习用户的偏好和历史对话,提供个性化的服务。
对话智能体广泛应用于在线客服、智能助手、聊天机器人等场景。例如,企业的在线客服智能体可以帮助用户解决常见问题,提高客户服务效率;个人智能助手可以帮助用户管理日程、设置提醒、查询信息等。
设计时需要考虑如下内容:
(1)大模型选择:选择适合对话任务的大模型,如 GPT 系列模型等。
(2)记忆管理:维护对话历史作为短期记忆,记录用户的每一轮对话内容,以便在后续对话中保持上下文连贯。同时,它可以存储用户的个人信息、偏好等作为长期记忆,用于提供个性化服务。
(3)对话状态管理:使用基于框架或上下文的方法表示对话状态,跟踪用户的意图、已获取的信息等。例如,在客服对话中,记录用户的问题类型、当前的解决方案进展等。对话状态也可以直接合并到记忆管理当,大模型可从历史记录中自动进行识别。
(4)提示工程:设计合适的提示,引导大模型生成自然、友好、准确的回答。例如,在对话开始时,使用欢迎提示引导用户表达需求;在用户提问时,根据问题类型生成相应的提示输入给大模型。
(5)知识库:知识库是指利用特定的资料库内容,通过技术手段将其引入问答系统,以实现更具针对性的定制化问答结果。当前主流的方法之一是 RAG(Retrieval-Augmented Generation)技术,它结合了信息检索和生成模型的优点。具体而言,系统会先从预先构建的知识库中检索出与用户问题最相关的文本片段,然后将这些内容与用户问题一同输入到生成模型中,生成准确且符合上下文的回答。这种方式不仅提升了回答的相关性和准确性,也使得问答系统能够处理更专业、更垂直领域的内容。
下面分别介绍各个模块实现方式。
2.1 大模型模块
大模型模块程序如下:
class LLM:
'''大语言模型集成模块'''
def __init__(self):
api_key = '<用户的 API Key>'
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
self.model = 'qwen-turbo-latest'
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url,
)
def generate_response(self, messages):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0.7,
max_tokens=2000
)
return response.choices[0].message.content.strip()
except Exception as e:
return f'生成响应时出错:{str(e)}'在类的初始化方法中,我们设置了大语言模型的 API 密钥、基础 URL 和模型名称。这里使用的是阿里云的 DashScope 平台,模型为 qwen-turbo-latest。同时,我们创建了一个 openai.OpenAI 客户端实例,用于与大模型进行通信。
generate_response 方法接受一个消息列表作为输入,该列表包含了对话的历史信息和当前用户的输入。通过调用 client.chat.completions.create 方法,我们向大语言模型发送请求,并获取生成的响应。同时,我们设置了 temperature 参数为 0.7,用于控制生成文本的随机性,max_tokens 参数为 2000,用于限制生成文本的最大长度。如果在生成响应过程中出现异常,我们将返回错误信息。
大模型模块测试程序如下,用于测试大语言模型的回复功能。我们创建了一个 LLM 类的实例,并构造了一个包含用户输入的消息列表。然后,我们调用 generate_response 方法生成响应并打印结果。
# 大模型回复测试
def llm_test():
llm = LLM()
messages = [{'role': 'user', 'content': '你好'}]
print(llm.generate_response(messages))运行测试函数结果如下:
你好!有什么我可以帮助你的?2.2 记忆管理模块
记忆管理模块程序如下:
class MemoryManager:
'''记忆管理模块'''
def __init__(self, max_history=5):
self.history = deque(maxlen=max_history)
def add_history(self, role, content):
self.history.append({'role': role, 'content': content})
def get_history(self):
return list(self.history)在类的初始化方法中,我们使用collections.deque创建了一个双端队列history,并设置了其最大长度为max_history。这样可以确保对话历史记录的长度不会超过指定的最大值,避免内存占用过多。
add_history 方法用于向对话历史记录中添加一条新的记录。每条记录是一个字典,包含 role(角色,如 system、user 或 assistant)和 content(内容)两个键值对。get_history 方法用于将历史记录转换为列表,以与 messages 类型保持一致。
记忆管理模块测试程序如下,用于测试记忆管理模块的功能。我们创建了一个 MemoryManager 类的实例,并设置最大历史记录长度为 4。然后,我们循环添加 4 条用户输入和助手回复的记录,并在每次添加后打印对话历史记录。
# 记忆管理测试
def memory_test():
mm = MemoryManager(max_history=4)
print(mm.get_history())
for i in range(4):
mm.add_history('user', f'user {i}')
mm.add_history('assistant', f'assistant {i}')
print(mm.get_history())运行测试函数结果如下:
[]
[{'role': 'user', 'content': 'user 0'}, {'role': 'assistant', 'content': 'assistant 0'}]
[{'role': 'user', 'content': 'user 0'}, {'role': 'assistant', 'content': 'assistant 0'}, {'role': 'user', 'content': 'user 1'}, {'role': 'assistant', 'content': 'assistant 1'}]
[{'role': 'user', 'content': 'user 1'}, {'role': 'assistant', 'content': 'assistant 1'}, {'role': 'user', 'content': 'user 2'}, {'role': 'assistant', 'content': 'assistant 2'}]
[{'role': 'user', 'content': 'user 2'}, {'role': 'assistant', 'content': 'assistant 2'}, {'role': 'user', 'content': 'user 3'}, {'role': 'assistant', 'content': 'assistant 3'}]2.3 简化版知识库模块
知识库模块程序如下:
class SimpleKnowledgeBase:
'''简化版知识库模块'''
def __init__(self):
# 硬编码知识条目(内容,关键词)
self.entries = [
('Python使用动态类型,运行时确定变量类型', ['python', '动态类型', '变量']),
('RAG结合检索和生成,减少模型幻觉', ['RAG', '检索', '生成', '幻觉']),
('HTTP状态码200表示成功,404未找到', ['HTTP', '状态码', '200', '404'])
]
def retrieve(self, query):
'''关键词匹配搜索'''
matches = []
for content, keywords in self.entries:
# 计算共同关键词数量
common = len(set(query) & set(''.join(keywords)))
if common > 2:
matches.append(content)
# 返回前2条匹配记录
return '\n'.join(matches[:2]) if matches else '无相关信息'在类的初始化方法中,我们定义了一个知识条目列表 entries,每个条目是一个元组,包含知识内容和相关的关键词列表。这里的知识条目是硬编码的,实际应用中可以从数据库或文件中加载。
Retrieve 方法用于根据用户输入的查询关键词进行知识检索。首先,我们遍历知识库中的所有条目,计算查询关键词与每个条目的关键词列表的共同元素数量。如果共同元素数量大于 2,则将该条目的知识内容添加到匹配列表中。最后,我们返回匹配列表中的前 2 条记录,如果没有匹配记录,则返回无相关信息。
该模块是简化后的知识库模块,而当前通用做法是结合 RAG 技术。它是一种将信息检索与文本生成相结合的技术。其基本原理是在生成模型回答问题或生成文本时,首先通过检索数据库中的相关信息来增强模型的输入,从而提高生成的质量和准确性。在 RAG 过程中,模型会向一个向量数据库查询相关文档或数据,这些文档被编码为高维向量,并存储在数据库中。用户查询内容也需要进行向量化,然后向量数据库利用相似度搜索算法快速查找与用户查询最相关的向量,并返回对应的文字内容。生成模型将这些信息作为上下文,结合自身的语言生成能力,生成更加精准和信息丰富的答案。这种方法尤其适用于处理大规模知识库,能够弥补传统生成模型的知识盲点,使其在面对专业性问题时更为高效和可靠。
知识库模块测试程序如下,用于测试知识库模块的功能。我们创建了一个SimpleKnowledgeBase 类的实例,并使用不同的查询关键词调用 retrieve 方法,打印检索结果。
# 知识库测试
def knowledge_base_test():
kb = SimpleKnowledgeBase()
print(kb.retrieve('动态类型'))
print(kb.retrieve('你好'))
print(kb.retrieve('检索'))
print(kb.retrieve('HTTP 404'))
print(kb.retrieve('HTTP 200'))
print(kb.retrieve('HTTP 200 404'))
print(kb.retrieve('HTTP 200404 500'))运行测试函数结果如下:
Python使用动态类型,运行时确定变量类型
无相关信息
无相关信息
HTTP状态码200表示成功,404未找到
HTTP状态码200表示成功,404未找到
HTTP状态码200表示成功,404未找到
HTTP状态码200表示成功,404未找到2.4 对话智能体模块
对话智能体模块程序如下:
class ConversationAgent:
'''集成大模型的对话智能体'''
def __init__(self):
self.llm = LLM()
self.memory = MemoryManager()
self.knowledge_base = SimpleKnowledgeBase()
self.system_prompt = {'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}
def _build_messages(self, knowledge, history, prompt):
if knowledge != '无相关信息':
prompt = f'{prompt}\n\n以下为知识库上下文\n[Context]\n{knowledge}\n[/Context]'
history.append({'role': 'user', 'content': prompt})
messages = [self.system_prompt] + history
print('messages: ', messages)
return messages
def process_input(self, user_input):
# 知识检索
knowledge = self.knowledge_base.retrieve(user_input)
# 记忆检索
history = self.memory.get_history()
messages = self._build_messages(knowledge, history, user_input)
# 生成响应
response = self.llm.generate_response(messages)
# 更新记忆
self.memory.add_history('user', user_input)
self.memory.add_history('assistant', response)
return response在类的初始化方法中,我们创建了大语言模型集成模块、记忆管理模块和知识库模块的实例,并设置了系统提示词信息。系统提示词信息用于向大语言模型传达对话的上下文和要求。
_build_messages 方法用于构建向大语言模型发送的消息列表。如果知识库中存在与用户查询相关的知识,我们将知识内容添加到用户输入的提示信息中。然后,我们将用户输入的提示信息添加到对话历史记录中,并将系统提示信息和对话历史记录组合成一个消息列表。
process_input 方法是对话智能体的核心方法,用于处理用户输入。首先,我们调用知识库模块的 retrieve 方法进行知识检索,获取与用户查询相关的知识内容。然后,我们获取对话历史记录,并调用 _build_messages 方法构建消息列表。接着,我们调用大语言模型集成模块的 generate_response 方法生成响应。最后,我们将用户输入和生成的响应添加到对话历史记录中,并返回响应结果。
对话智能体模块测试程序(主函数)如下,用于测试对话智能体的整体功能。我们创建了一个 ConversationAgent 类的实例,并定义了一个查询列表。然后,我们遍历查询列表,依次处理每个查询,并打印用户输入和助手回复。
def main():
agent = ConversationAgent()
# 对话示例
queries = [
'请解释Python的动态类型系统',
'请介绍 React Agent?',
'RAG技术的主要优势是什么?',
'我之前问过关于Python的问题吗?'
]
for query in queries:
print(f'[用户] {query}')
response = agent.process_input(query)
print(f"[助手] {response}\n{'-'*60}")运行主函数结果如下:
[用户] 请解释Python的动态类型系统
messages: [{'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}, {'role': 'user', 'content': '请解释Python的动态类型系统\n\n以下为知识库上下文\n[Context]\nPython使用动态类型,运行时确定变量类型\n[/Context]'}]
[助手] Python的动态类型系统指变量类型在运行时确定,无需提前声明,可随时改变。
------------------------------------------------------------
[用户] 请介绍 React Agent?
messages: [{'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}, {'role': 'user', 'content': '请解释Python的动态类型系统'}, {'role': 'assistant', 'content': 'Python的动态类型系统指变量类型在运行时确定,无需提前声明,可随时改变。'}, {'role': 'user', 'content': '请介绍 React Agent?'}]
[助手] React Agent 是一种用于构建反应性系统的框架,支持事件驱动和状态管理,常用于复杂交互场景。
------------------------------------------------------------
[用户] RAG技术的主要优势是什么?
messages: [{'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}, {'role': 'user', 'content': '请解释Python的动态类型系统'}, {'role': 'assistant', 'content': 'Python的动态类型系统指变量类型在运行时确定,无需提前声明,可随时改变。'}, {'role': 'user', 'content': '请介绍 React Agent?'}, {'role': 'assistant', 'content': 'React Agent 是一种用于构建反应性系统的框架,支持事件驱动和状态管理,常用于复杂交互场景。'}, {'role': 'user', 'content': 'RAG技术的主要优势是什么?\n\n以下为知识库上下文\n[Context]\nRAG结合检索和生成,减少模型幻觉\n[/Context]'}]
[助手] RAG技术的主要优势是结合检索与生成,有效减少模型幻觉,提高信息准确性。
------------------------------------------------------------
[用户] 我之前问过关于Python的问题吗?
messages: [{'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}, {'role': 'assistant', 'content': 'Python的动态类型系统指变量类型在运行时确定,无需提前声明,可随时改变。'}, {'role': 'user', 'content': '请介绍 React Agent?'}, {'role': 'assistant', 'content': 'React Agent 是一种用于构建反应性系统的框架,支持事件驱动和状态管理,常用于复杂交互场景。'}, {'role': 'user', 'content': 'RAG技术的主要优势是什么?'}, {'role': 'assistant', 'content': 'RAG技术的主要优势是结合检索与生成,有效减少模型幻觉,提高信息准确性。'}, {'role': 'user', 'content': '我之前问过关于Python的问题吗?\n\n以下为知识库上下文\n[Context]\nPython使用动态类型,运行时确定变量类型\n[/Context]'}]
[助手] 是的,您之前问过关于Python的问题,提到其动态类型系统。
------------------------------------------------------------对话智能体完整程序如下:
import openai
from collections import deque
class LLM:
'''大语言模型集成模块'''
def __init__(self):
api_key = '<用户的 API Key>'
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
self.model = 'qwen-turbo-latest'
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url,
)
def generate_response(self, messages):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0.7,
max_tokens=2000
)
return response.choices[0].message.content.strip()
except Exception as e:
return f'生成响应时出错:{str(e)}'
class MemoryManager:
'''记忆管理模块'''
def __init__(self, max_history=5):
self.history = deque(maxlen=max_history)
def add_history(self, role, content):
self.history.append({'role': role, 'content': content})
def get_history(self):
return list(self.history)
class SimpleKnowledgeBase:
'''简化版知识库模块'''
def __init__(self):
# 硬编码知识条目(内容,关键词)
self.entries = [
('Python使用动态类型,运行时确定变量类型', ['python', '动态类型', '变量']),
('RAG结合检索和生成,减少模型幻觉', ['RAG', '检索', '生成', '幻觉']),
('HTTP状态码200表示成功,404未找到', ['HTTP', '状态码', '200', '404'])
]
def retrieve(self, query):
'''关键词匹配搜索'''
matches = []
for content, keywords in self.entries:
# 计算共同关键词数量
common = len(set(query) & set(''.join(keywords)))
if common > 2:
matches.append(content)
# 返回前2条匹配记录
return '\n'.join(matches[:2]) if matches else '无相关信息'
class ConversationAgent:
'''集成大模型的对话智能体'''
def __init__(self):
self.llm = LLM()
self.memory = MemoryManager()
self.knowledge_base = SimpleKnowledgeBase()
self.system_prompt = {'role': 'system', 'content': '你是一个 FGAI 专业助手,可以根据上下文与历史信息进行回答,请给出专业、准确的回答,如信息不足请明确说明。回答不要超过50个字。'}
def _build_messages(self, knowledge, history, prompt):
if knowledge != '无相关信息':
prompt = f'{prompt}\n\n以下为知识库上下文\n[Context]\n{knowledge}\n[/Context]'
history.append({'role': 'user', 'content': prompt})
messages = [self.system_prompt] + history
print('messages: ', messages)
return messages
def process_input(self, user_input):
# 知识检索
knowledge = self.knowledge_base.retrieve(user_input)
# 记忆检索
history = self.memory.get_history()
messages = self._build_messages(knowledge, history, user_input)
# 生成响应
response = self.llm.generate_response(messages)
# 更新记忆
self.memory.add_history('user', user_input)
self.memory.add_history('assistant', response)
return response
def main():
agent = ConversationAgent()
# 对话示例
queries = [
'请解释Python的动态类型系统',
'请介绍 React Agent?',
'RAG技术的主要优势是什么?',
'我之前问过关于Python的问题吗?'
]
for query in queries:
print(f'[用户] {query}')
response = agent.process_input(query)
print(f"[助手] {response}\n{'-'*60}")
# 大模型回复测试
def llm_test():
llm = LLM()
messages = [{'role': 'user', 'content': '你好'}]
print(llm.generate_response(messages))
# 记忆管理测试
def memory_test():
mm = MemoryManager(max_history=4)
print(mm.get_history())
for i in range(4):
mm.add_history('user', f'user {i}')
mm.add_history('assistant', f'assistant {i}')
print(mm.get_history())
# 知识库测试
def knowledge_base_test():
kb = SimpleKnowledgeBase()
print(kb.retrieve('动态类型'))
print(kb.retrieve('你好'))
print(kb.retrieve('检索'))
print(kb.retrieve('HTTP 404'))
print(kb.retrieve('HTTP 200'))
print(kb.retrieve('HTTP 200 404'))
print(kb.retrieve('HTTP 200404 500'))
if __name__ == '__main__':
# 测试大模型
# llm_test()
# 测试记忆管理
# memory_test()
# 测试知识库
# knowledge_base_test()
# 测试对话智能体
main()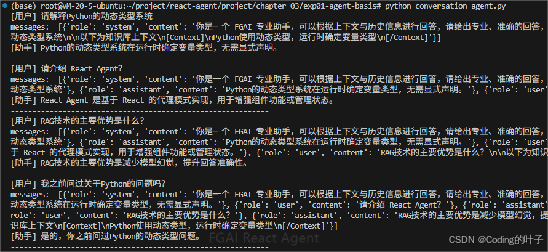
图1 对话智能体运行结果
立即关注获取最新动态
点击订阅《React Agent 开发专栏》,每周获取智能体开发深度教程。项目代码持续更新至React Agent 开源仓库,欢迎 Star 获取实时更新通知!FGAI 人工智能平台:FGAI 人工智能平台 https://www.botaigc.cn/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











