






(一)二叉树
1.二叉树的性质
二叉树的特点就是每个结点至多有两棵子树; 二叉树的子树有左右之分; 二叉树的存储和处理比一般树简单. 任何树都可以方便地转换为二叉树来存储和处理。

像上述的这个图形一样的我们就称为二叉树。
2.二叉树的存储结构
(1)动态二叉树
数据结构中一般这么定义二叉树:
struct Node {
int value ;//节点的值,可以定义多个值
node *lson ,*rosn;//指向左右子节点;
};
动态新建一个Node时,用new运算符动态申请一个节点。使用完毕后,应该用delete命令释放他,否则内存会泄露。动态二叉树的优点是不会浪费内存,缺点就是需要关心,一不小心就会出错。
(2)用静态数组存储二叉数
在竞赛算法中,为了编码简单,加快速度,一般用静态数组实现二叉树。下面定义一个大小为N的结构体数组。
struct Node {
char value;
int lson, rson;//左右孩子,竞赛时把lson rson简写为l,r;
}tree[N];

3.二叉树的遍历
这边我们讲的是深度优先遍历。
(1)先序遍历
按树根、左子树、右子树的顺序访问

上面的图片中的二叉树按照先序遍历进行走的话,遍历的结果的是EBADCGFIH 先序遍历的第一个节点是根,接下来是他的伪代码:
void preorder (node *root){
cout << root ->value; //输出
preorder (root ->l); //递归左子树
preorder (root ->r); //递归右子树
}
(2)中序遍历
按照左子树、树根、右子树进行遍历。我们按照图一的树来走的话是ABCDEFHHI 我们可以发现,中序遍历的中间是我们的根节点E 在跟节点的左边是我们左子树的部分,在我们右边是我们的右子树部分 这就是中序遍历的一大优点。下面是他的伪代码:
void inorder (node *root){
inorder (root ->l); //递归左子树
cout << root ->value; //输出
inorder (root ->r); //递归右子树
}
(3)后序遍历
按照左子树、右子树、树根进行遍历。按照图一走的话是ACDBFHIGE 根节点在最后 下面是他的伪代码:
void preorder(node* root) {
preorder(root->l); //递归左子树
preorder(root->r); //递归右子树
cout << root->value; //输出
}
注意:“中序遍历+先序遍历”,或者“中序遍历+后序遍历”,都能确定一棵树。 但是只有“先序遍历+后序遍历”,不能确定一棵树。例如下图,它们的先序遍历都是"1 2 3",后序遍历都是"3 2 1"。

接下来我们看一个关于这三个遍历的例题:
Binary Tree Traversals(hdu1710)


这个题目就是输入先序遍历和中序遍历 让我们输出后续遍历的结果 这个题目的思路就是
1)先序遍历的第一个数是整棵树的根,例如样例中的“1”。再对照中序遍历,“1”左边的“4 7 2”都在根的左子树上,右边的“8 5 9 3 6”都在根的右子树上。得到下图最左子图。 (2)递归上述过程。
如下图所示:

代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 1000 + 10;
int pre[N];//先序
int in[N];//中序
int post[N];//后序
int idx = 0;//标记数组下标的位置
struct node {
int value;//节点的值
node* left, * right;//左子树,右子树
//初始化
node(int v = 0, node* l = NULL, node* r = NULL) {
value = v;
left = l;
right = r;
}
};
void build(int left, int right, int& layer, node*& tree);
void postOrder(node* root);
int main() {
int n;
while (cin >> n){
//读入数据
//先序序列
for (int i = 0; i < n; i++) {
cin >> pre[i];
}
//中序序列
for (int i = 0; i < n; i++) {
cin >> in[i];
}
//建树
node* root; //定义树根节点
int t = 0;
build(0, n - 1, t, root);
idx = 0;//初始化idx的值
postOrder(root);
for (int i = 0; i < n - 1; i++) {
cout << post[i] << " ";
}
cout << post[n - 1] << endl;
}
return 0;
}
//创建二叉树
void build(int left, int right, int& layer, node*& tree) {
// 1.在先序遍历中找到根节点pre[layer - 1];
int t = pre[layer];
//2.在中序遍历中找到树根的位置pos,初始化为-1
int pos = -1;
for (int i = left; i <= right; i++) {
if (in[i] == t) {//找到了树根
pos = i;//记录树根的位置
break;
}
}
//如果没找到树根就直接结束
if (pos == -1) {
return;
}
//创建树根节点
tree = new node(t);
layer++;
//递归创建左子树[left,pos - 1]
if (left < pos) {
build(left, pos - 1, layer, tree->left);
}
//递归创建右子树[pos + 1,right]
if (right > pos) {
build(pos + 1, right, layer, tree->right);
}
}
//后序遍历
void postOrder(node* root) {
if (root == NULL) {//递归出口
return;
}
postOrder(root->left);//递归遍历左子树
postOrder(root->right);//递归遍历右子树
post[idx++] = root->value;//保存树根
}
//先序遍历
void preOrder(node* root) {
if (root == NULL) {//递归出口
return;
}
cout << root->value << " ";//树根
preOrder(root->left); //左子树
preOrder(root->right); //右子树
}
//中序遍历
void inOrder(node* root)
{
if (root == NULL) return; //递归出口
inOrder(root->left); //左子树
cout << root->value << " ";//树根
inOrder(root->right); //右子树
}其中对于node*的解释在下面:

4.二叉堆
堆可以看成一棵完全二叉树。用数组实现的二叉树堆,树中的每个结点与数组中存放的元素对应。树的每一层,除了最后一层可能不满,其他每一层都是满的。 二叉堆中的每个结点,都是以它为父结点的子树的最小值。

用数组A[]存储完全二叉树,结点数量为n,A[0]不用,A[1]为根结点,有以下性质:
(1)i > 1的结点,其父结点位于i/2;
(2)如果2i > n,那么i没有孩子;如果2i+1 > n,那么i没有右孩子;
(3)如果结点i有孩子,那么它的左孩子是2i,右孩子是2i+1。

看每个数的下标符合上述的规律和定义
二叉堆的操作
(1)上浮

(2)下沉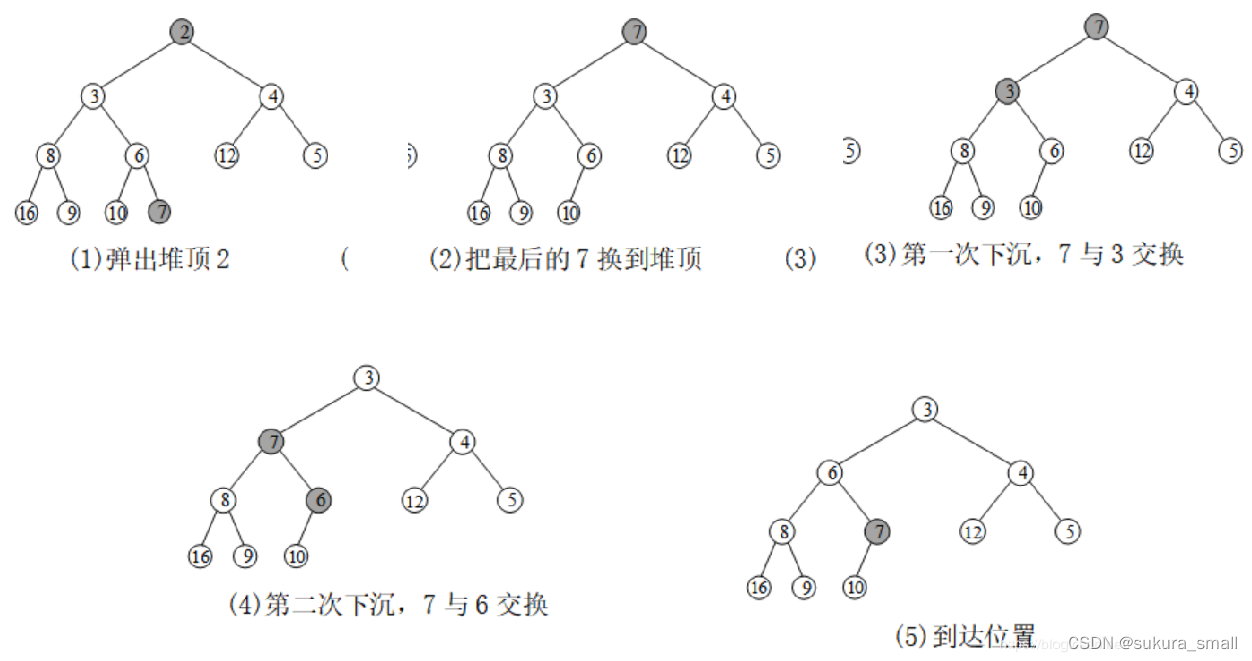
堆经常用于实现优先队列,上浮对应优先队列的插入操作push(),下沉对应优先队列的删除操作pop();
介绍了二叉堆的操作,那我们能写出手写堆吗 当然可以
堆(洛谷P3378)

代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6+10;
int h[N];
int len = 0;
void push(int x){
h[++len]=x;
int i=len;
while(i > 1 && h[i] < h[i/2]){
swap(h[i],h[i/2]);
i/=2;
}
}
void pop(){
h[1] = h[len];
len --;
int i = 1;
while(2 * i <=len){
int s = 2 * i;
if(s < len && h[s + 1] < h[s]){
s ++;
}
if(h[s] < h[i]){
swap(h[s],h[i]);
i = s;
}
else{
break;
}
}
}
int main(){
int n;
cin >> n;
int op ,x;
while(n--){
cin >> op;
if(op==1){
cin >> x;
push(x);
}
else if(op ==2){
cout << h[1] << endl;
}
else{
pop();
}
}
}
上面就是我们手写了一个堆
优先队列
一个优先队列声明的基本格式是:priority_queue<结构类型> 队列名;
就像这样:
priority_queue <int> i;
priority_queue <double> d;
但我们一般都这么写:
priority_queue <node> q;
//node是一个结构体
//结构体里重载了‘<’小于符号
priority_queue <int,vector<int>,greater<int> > q;
//不需要#include<vector>头文件
//注意后面两个“>”不要写在一起,“>>”是右移运算符
priority_queue <int,vector<int>,less<int> >q;
这个优先队列有什么用呢?他能默认帮我们把输入的数字排好大小,然后任我们处置 比如:
#include<bits/stdc++.h>
using namespace std;
priority_queue<int >q;
int main() {
q.push(10), q.push(23), q.push(12), q.push(6), q.push(2);
while (!q.empty()) {
cout << q.top()<<" ";
q.pop();
}
return 0;
}输出的结果就是 23 12 10 6 2 他默认帮我们从小到大排好序
至于对于结构体函数如何排序 我们看接下来的代码
#include<bits/stdc++.h>
using namespace std;
struct node {
int x, y;
bool operator<(const node& a)const
{
return x < a.x;
}
}k;
priority_queue<node>q;
int main() {
k.x = 10, k.y = 100; q.push(k);
k.x = 12, k.y = 60; q.push(k);
k.x = 14, k.y = 40; q.push(k);
k.x = 6, k.y = 80; q.push(k);
k.x = 8, k.y = 20; q.push(k);
while (!q.empty()) {
cout <<"("<< q.top().x<<"," << q.top().y <<") "<<" ";
q.pop();
}
return 0;
}程序大意就是插入(10,100),(12,60),(14,40),(6,20),(8,20)这五个node。
再来看看它的输出:(14,40) (12,60) (10,100) (8,20) (6,80) 它也是按照重载后的小于规则,从大到小排序的。
less和greater的优先队列:
先来看定义这两个优先队列的格式:
priority_queue <int,vector<int>,less<int> > p;
priority_queue <int,vector<int>,greater<int> > q;
然后我们看一个简单的用到这两个队列的案例:
#include<cstdio>
#include<queue>
using namespace std;
priority_queue <int,vector<int>,less<int> > p;
priority_queue <int,vector<int>,greater<int> > q;
int a[5]={10,12,14,6,8};
int main()
{
for(int i=0;i<5;i++)
p.push(a[i]),q.push(a[i]);
printf("less<int>:");
while(!p.empty())
printf("%d ",p.top()),p.pop();
printf("\ngreater<int>:");
while(!q.empty())
printf("%d ",q.top()),q.pop();
}
输出结果:less<int>:14 12 10 8 6 greater<int>:6 8 10 12 14
所以我们可以看到 less是从大到小进行排序 而greater是从大到小进行排序
还有就是里面我们不一定要加那个greater<int> 我们可以自己构造bool的判断函数进行判断 比如如下代码:
#include<queue>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
int n;
struct node
{
int fir,sec;
void Read() {scanf("%d %d",&fir,&sec);}
}input;
struct cmp1
{
bool operator () (const node &x,const node &y) const
{
return x.fir<y.fir;
}
};//当一个node x的fir值小于另一个node y的fir值时,称x<y
struct cmp2
{
bool operator () (const node &x,const node &y) const
{
return x.sec<y.sec;
}
};//当一个node x的sec值小于另一个node y的sec值时,称x<y
struct cmp3
{
bool operator () (const node &x,const node &y) const
{
return x.fir+x.sec<y.fir+y.sec;
}
};//当一个node x的fri值和sec值的和小于另一个node y的fir值和sec值的和时,称x<y
priority_queue<node,vector<node>,cmp1> q1;
priority_queue<node,vector<node>,cmp2> q2;
priority_queue<node,vector<node>,cmp3> q3;
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++) input.Read(),q1.push(input),q2.push(input),q3.push(input);
printf("\ncmp1:\n");
while(!q1.empty()) printf("(%d,%d) ",q1.top().fir,q1.top().sec),q1.pop();
printf("\n\ncmp2:\n");
while(!q2.empty()) printf("(%d,%d) ",q2.top().fir,q2.top().sec),q2.pop();
printf("\n\ncmp3:\n");
while(!q3.empty()) printf("(%d,%d) ",q3.top().fir,q3.top().sec),q3.pop();
}
我们构造了三个自定义的cmp 里面镶嵌了一个bool类型的operator 来排列各自需要的排列顺序
以上就是所有关于优先队列的内容 ..
下面是一些关于二叉堆的题目 我们一题一题来分析和理解
5.二叉树课后题目
先序排列(洛谷p1030)

想法:
- 输出该部分后序遍历最后一项(后序遍历是左右根,所以最后一项是根)
- 在中序遍历中找到他
- 分成左右两部分
- 判断是否为空
- 如果不为空,回到第1步
这里有一个问题,就是在中序和后序中的位置对不好,以样例为例,当输出A和B之后,中序的DC位于2、3的位置(位置用0--3表示),而后序在1、2位置,这怎么办呢?
其实,通过观察,我们会发现,一个位置,每被划分为右半部分一次,中序和后序的位置就会错开1。还是以样例为例,DC在有且仅有第一次划分是被分到右边,所以中序和后序的位置会错开1个点。 那么,了解了这点以后,就不会有什么大问题了
下面就是对应的代码:
#include<bits/stdc++.h>
using namespace std;
string s2, s3;
void dis(int l, int r, int s)
{
cout << s3[r - s];
for (int i = l; i <= r; i++)
if (s2[i] == s3[r - s])
{
if (i != l) dis(l, i - 1, s);
if (i != r) dis(i + 1, r, s + 1);
}
return;
}
int main()
{
cin >> s2 >> s3;
int l = s2.length();
dis(0, l - 1, 0);
return 0;
}新二叉树(洛谷P1305)

这个就是一个新二叉树的写法 就是判断根和左右节点的事情 下面是代码
#include<bits/stdc++.h>
using namespace std;
int n;
char a[30][3];
void f(char x)
{
if (x != '*')
{
cout << x;
for (int i = 1; i <= n; i++)
if (a[i][0] == x)
{
f(a[i][1]);
f(a[i][2]);
}
}
return;
}
int main()
{
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i][0] >> a[i][1] >> a[i][2];
f(a[1][0]);
return 0;
}中位数(洛谷p1168)

想法:这边的思想就是创造两个堆 一个是大根堆 一个是小根堆 然后有一个中间值 每次存两个 如果两个堆的个数是一样的 那么我就输出中间值 这个时候中位数就是mid 但有一种情况就是我前面输入的两个数字都比mid大 那做完这两次操作的时候有一个堆的数量是没有加的 那这个时候我们就要做一个操作 重新寻找mid 然后还要让两个堆的数量一样 那这个时候我们输出的中位数才是中位数 接下来是我们的代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
#include<queue>
using namespace std;
int n;
int a[100100];
int mid;
priority_queue<int, vector<int>, less<int> >q1;//大根堆
priority_queue<int, vector<int>, greater<int> >q2;//小根堆
int main() {
cin >> n;
scanf("%d", &a[1]);
mid = a[1];
cout << mid << endl;//mid初值是a[1]
for (int i = 2; i <= n; i++) {
scanf("%d", &a[i]);
if (a[i] > mid) q2.push(a[i]);
else q1.push(a[i]);
if (i % 2 == 1) {//第奇数次加入
while (q1.size() != q2.size()) {
if (q1.size() > q2.size()) {
q2.push(mid);
mid = q1.top();
q1.pop();
}
else {
q1.push(mid);
mid = q2.top();
q2.pop();
}
}
cout << mid << endl;
}
}
return 0;
}合并果子(洛谷p1090)

这个题目用个优先队列就行 每次取上面的两个数字 然后加起来 再存入数组 循环反复 代码如下
#include<bits/stdc++.h>
using namespace std;
priority_queue<int, vector<int>, greater<int> > q;
int main() {
int n;
cin >>n;
for (int i = 0; i < n; i++) {
int x;
cin >> x;
q.push(x);
}
int ans = 0;
while (q.size() != 1) {
int a = q.top();
q.pop();
int b = q.top();
q.pop();
ans += a + b;
q.push(a + b);
}
cout << ans << endl;
return 0;
}(二)DFS搜索算法
它这个算法的本质其实是递归算法 他就是往死里递归
接下来我们看一个有关这个搜索的题目:
(1)全排序


这个题目看到的第一个瞬间就是用暴力枚举(这边我就不写了)但这个很可惜是个不确定的数字输入 然后算法复杂度是O(n^n) 我们也可以用stl的next_permutation来写 但要记得前面先给他排序号 (这个方法对于这个题目来说貌似是最快的) 但这个题目其实可以用我们的深度优先搜索DFS 它就是递归 在递归的同时很好的利用到我们的vector容器 接下来就看我们的代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<vector>
#include<iostream>
using namespace std;
struct ARRAY : vector<int>
{
ARRAY append(int n) { ARRAY t(*this); t.push_back(n); return t; }//把n这个数字加进来
ARRAY remove(int i) { ARRAY t(*this); t.erase(t.begin() + i); return t; }//删除容器中第i个元素
};
void f(ARRAY L, ARRAY R)
{
if (R.size() == 0)//当R容器里面没有数字了
{
for (int i = 0; i < L.size(); i++) printf("%5d", L[i]);
printf("\n");
return;
}
for (int i = 0; i < R.size(); i++)
{
f(L.append(R[i]), R.remove(i));//递归 往死里递归它
}
}
int main()
{
ARRAY L, R;
int n;
scanf("%d", &n);
for (int i = 1; i <=n ; i++) R.push_back(i);
f(L, R);
}
它这个现在前面构造了两个算是自定义的结构体吧 一个是append 添加 把这个i加到原有的容器里 一个是remove移除 把第i个数从容器中除掉 然后之后呢 就是一直递归递归递归 可能 有些人看不懂那个中间的f(L.append(R[i]),R.remove(i)); 我这边引用一个图片 看下面的图片

它就是逐渐一个个分一个个分 这个ABCD就好比1234 有那种子函数的那种感觉 我觉得看这张图片之后我们就会比较好理解这个其中的递归
(2)部分排序:
上面那个是全排序 就是将所有数字按照一定顺序全部输出 上面也说了 用我们STL里面的next_permutation 但当我们想输出部分排序的时候 也就是 比如想输出四个数字里面的三个数字 然后从小到大排序的时候 我们就用不到这个容器了 那这个时候我们也可以用这个DFS来做到

这个时候我们在原来的代码基础上改一下 就是当左边的容器的数量达到m的时候 就输出 然后继续递归 下面是代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<vector>
#include<iostream>
using namespace std;
struct ARRAY : vector<char>
{
ARRAY append(char n) { ARRAY t(*this); t.push_back(n); return t; }//把n这个数字加进来
ARRAY remove(int i) { ARRAY t(*this); t.erase(t.begin() + i); return t; }//删除容器中第i个元素
};
void f(ARRAY L, ARRAY R,int m)
{
if (L.size() == m)//当L容器的长度等于m的时候 就输出 然后继续递归
{
for (auto it = L.begin(); it != L.end(); it++) {
cout << *it;
}
printf("\n");
}
for (int i = 0; i < R.size(); i++)
{
f(L.append(R[i]), R.remove(i),m);//递归 往死里递归它
}
}
int main()
{
ARRAY L, R;
int n,m;
scanf("%d%d", &n,&m);
for (int i = 1; i <= n; i++) R.push_back((i-1)+'A');
f(L, R,m);
}
(3)求组合数

这个我们也可以用DFS搜索算法进行编程:
#define _CRT_SECURE_NO_WARNINGS 1
#include<vector>
#include<iostream>
using namespace std;
struct ARRAY : vector<int>
{
ARRAY append(int n) { ARRAY t(*this); t.push_back(n); return t; }//把n这个数字加进来
ARRAY remove(int i) { ARRAY t(*this); t.erase(t.begin() + i); return t; }//删除容器中第i个元素
};
void f(ARRAY L, ARRAY R,int m)
{
if (L.size() == m)//当L容器的长度等于m的时候 就输出 然后继续递归
{
for (auto it = L.begin(); it != L.end(); it++) {
printf("%3d",*it);
}
printf("\n");
}
for (int i = 0; i < R.size(); i++)
{
if (L.size() > 0) {
if (L.back() >= R[i])continue;//如果L的最后一位大于R的第一位 那么继续递归遍历
//他这个管了就是里面的数字只能升序 如果例如1234 四个数字 然后取3个数字
//132 4这样的布局是不行的 它是不会输出132的 只有134 2 然后输出134
}
f(L.append(R[i]), R.remove(i), m);
}
}
int main()
{
ARRAY L, R;
int n,m;
scanf("%d%d", &n,&m);
for (int i = 1; i <= n; i++) R.push_back((i));
f(L, R,m);
}
(4)有重复元素的排列问题

代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
using namespace std;
struct ARRAY : vector<char>
{
ARRAY append(char n) { ARRAY t(*this); t.push_back(n); return t; }//把n这个数字加进来
ARRAY remove(int i) { ARRAY t(*this); t.erase(t.begin() + i); return t; }//删除容器中第i个元素
};
long long ans = 0;
void f(ARRAY L, ARRAY R)
{
if (R.size() == 0) {
for (auto it = L.begin(); it != L.end(); it++) {
cout << *it;
}
ans++;
printf("\n");
return;
}
for (int i = 0; i < R.size(); i++) {
if (i > 0)
if (R[i - 1] == R[i]) //把重复的元素就是排除 继续
continue;
f(L.append(R[i]), R.remove(i));
}
}
int main()
{
ARRAY L, R;
int n;
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
char x;
cin >> x;
R.push_back(x);
}
sort(R.begin(), R.end());
f(L, R);
cout << ans;
}
大致格式都和上面的题目差不多 只不过多了一步排除重复的元素的一个步骤 挺好理解的。
(5)排列棋子

#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
using namespace std;
struct ARRAY : vector<int >
{
ARRAY append(int n) { ARRAY t(*this); t.push_back(n); return t; }//把n这个数字加进来
ARRAY remove(int i) { ARRAY t(*this); t.erase(t.begin() + i); return t; }//删除容器中第i个元素
};
void f(ARRAY L, ARRAY A,ARRAY B)
{
if (A.empty() && B.empty()) {
for (auto it = L.begin(); it != L.end(); it++) {
cout << *it;
}
cout << endl;
}
if (A.size() > 0) {
f(L.append(A[0]), A. remove(0), B);
}
if (B.size() > 0) {
f(L.append(B[0]),A, B.remove(0));
}
}
int main()
{
ARRAY L, A, B;
int a, b;
cin >> a>>b ;
for (int i = 0; i < a; i++) {
A.push_back(0);
}
for (int i = 0; i < b; i++) {
B.push_back(1);
}
f(L, A,B);
}
这个就是有a个白棋子和b个黑棋子然后去从小到大输出 然后分别取最上面的一个数给L 递归
(6)拆分自然数

也是递归思想 下面是代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<vector>
#include<iostream>
using namespace std;
struct ARRAY : vector<int>
{
ARRAY append(int v) { ARRAY t(*this); t.push_back(v); return t; }
};
int x;
void f(ARRAY a, int n)
{
if (n <= 0)
{
if (a.size() <= 1)return;//排除最后一个数字是7
//防止是7=7;
printf("%d", a[0]);
for (int i = 1; i < a.size(); i++) printf("%+d", a[i]);
printf("\n");
}
for (int i = 1; i <= n; i++)
{
if(a.size()>0)
if (a.back() > i)continue;
f(a.append(i), n - i);
}
}
int main()
{
ARRAY a;
scanf("%d", &x);
f(a, x);
}
(三)BFS搜索算法
bfs算法的全名是宽度优先搜索 它可以理解为“全面扩散、逐层递进” 对于DFS来讲 BFS使用的空间比较大 但是搜索的时间会大大降低 下面看几个BFS的题目
(1)lake counting s (洛谷p1596)

这个题目意思就是有多少个水坑 怎么判断是个独立水坑 就是四面八方都是“.”的时候那我们这个时候就变成了一个独立的水坑 那我们就创建八个数组然后判断是否周围还有“#” 然后一直查找下去就行了 其实感觉这个题目用dfs写可能会更快 我先把dfs的代码写在下面
#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
using namespace std;
int n, m;
int ans = 0;
char a[110][110];
int fxx[9] = { 0,-1,-1,-1,0,0,1,1,1 };
int fxy[9] = { 0,0,-1,1,-1,1,-1,0,1 };
void dfs(int x, int y) {
int r, c;
a[x][y] = '.';
for (int i = 1; i <= 8; i++) {
r = x + fxx[i];
c = y + fxy[i];
if (r < 1 || r>n || c<1 || c>m || a[r][c]=='.')
continue;
a[r][c] = '.';//覆盖覆盖再覆盖
dfs(r, c);
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >>a[i][j];
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (a[i][j] == 'W') {
ans++;
dfs(i, j);
}
}
}
cout << ans<<endl;
return 0;
}这个DFS的代码就是当你找到W的时候 我先将ans+一下 然后就开始搜索 搜索他四面八方的有没有“#” 有的话就是把它覆盖为“.” 然后继续查找查找再查找 这个感觉很好理解 然后接下来我放BFS的代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 110;
char a[N][N];//田地
int v[N][N] = { 0 };//标记是否已经搜索过或者是否需要搜索
struct node {
int x, y;
};
//方向数组(8个方向)
int dx[] = { -1, -1, 0, 1, 1, 1, 0, -1 };
int dy[] = { 0, 1, 1, 1, 0, -1, -1, -1 };
int n, m;
//判断是否出界
int check(int x, int y) {//判断是否在棋盘范围内
if (x <= n && x >= 1 && y <= m && y >= 1) {
return 1;
}
return 0;
}
void BFS(int sx, int sy) {
queue<node> q;
node st;
st.x = sx;
st.y = sy;
q.push(st);
v[sx][sy] = 1;
while (!q.empty()) {
int x = q.front().x;
int y = q.front().y;
for (int i = 0; i < 8; i++) {
int tx = x + dx[i];
int ty = y + dy[i];
if (check(tx, ty) == 1 && v[tx][ty] == 0) {
node tmp;
tmp.x = tx;
tmp.y = ty;
v[tx][ty] = 1;
q.push(tmp);
}
}
q.pop();
}
}
int main() {
cin >> n >> m;
//输入田地
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >> a[i][j];
if (a[i][j] == '.') {//如果是旱地就不用搜索
v[i][j] = 1;
}
}
}
int cnt = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (a[i][j] == 'W' && v[i][j] == 0) {//如果遇到没有搜索过的水坑就搜索
BFS(i, j);//i 和 j表示搜索开始的起点
cnt++;//经过几次搜索就表示有几个水坑
}
}
}
cout << cnt << endl;
return 0;
}光看代码长度我们就可以看出 BFS确实费空间奥
上面都有注释 就不多解释了 我觉得这个题目用DFS来写会比较好一点。
(2)填涂颜色(洛谷p1162)

这个题目就是让你搜索一个被1包围起来的地方 然后把里面的0全部变成2 题意是很好理解的 那我们这个时候就去想是用DFS还是用BFS 很显然我们这边用BFS会更好 我们先把在框外的0给填满1 这样我们就能区别里面的0和外面的0的区别 那填满1之后我们怎么把这些0和那些本来就是1的数组区分开来呢?再开一个数组好了 我们一开始就判断 如果原来的那个数就是1 那我另外一个数组的数据就是-1 否则就是0 这样我们把三中类型的数据给区分了 接下来是代码部分:
#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
using namespace std;
int a[35][35];
int b[35][35];
int n;
void dfs(int x, int y) {
if (x <= 0 || y <= 0 || x > n || y > n || a[x][y] != 0) {
return;
}
a[x][y] = 1;
dfs(x - 1, y);
dfs(x, y - 1);
dfs(x + 1, y);
dfs(x, y + 1);
}
int main() {
memset(a, 0, sizeof(a));
memset(b, 0, sizeof(b));
cin >> n;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cin >> a[i][j];
if (a[i][j] == 1) {
b[i][j] = -1;
}
}
}
for (int i = 1; i <= n; i++) {
dfs(1, i);
dfs(n, i);
dfs(i, 1);
dfs(i, n);//把边界开始一直搜 搜到就是有1包围的那一刻 外面的0此时a[i][j]都变成1了 里面的是没有变的 而原本是1的b[i][j]就是-1 根据这三个条件来判断是哪个数字
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (b[i][j] == -1) {
cout << 1<<" ";
}
else {
if (a[i][j] == 1) {
cout << 0<<" ";
}
else {
cout << 2<<" ";
}
}
}
cout << endl;
}
return 0;
}
(3)马的遍历

这个是一个BFS的搜索题目 题目让我们判断我们给出的点跳到棋盘上任意一点是否能走到?如果能走到 那我需要几步? 那我们就一个一个搜索呗 就以原点为中心 有八个方向 然后跳 每次跳的时候去判断 这是第几次 然后在这个点的基础上再去往外面搜索 循环结束的条件就是我跳的所有地方都是我走过的 或者是我跳了之后走到棋盘外面了 下面就是代码:
#include<bits/stdc++.h>
using namespace std;
int dir[][2] = { {-2,-1},{-1,-2},{-2,1},{-1,2},{1,-2},{2,-1},{2,1},{1,2} };
int mp[405][405];
struct pos {
int r, c, d;
pos(int a=0,int b=0,int d=0):r(a),c(b),d(d){}
};
void bfs(int r, int c);
int n, m, sr, sc;
int main() {
cin >> n >> m >> sr >> sc;
memset(mp, -1, sizeof(mp));
mp[sr][sc] = 0;
bfs(sr, sc);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cout << mp[i][j] << '\t';
}
cout << endl;
}
return 0;
}
void bfs(int r, int c) {
queue<pos>q;
q.push(pos(r,c));
mp[sr][sc] = 0;
while (!q.empty()) {
pos p = q.front();
q.pop();
for (int i = 0; i < 8; i++) {
int nr = p.r + dir[i][0];
int nc = p.c + dir[i][1];
int nd = p.d + 1;
if (nr >= 1 && nr <= n && nc >= 1 && nc<=m&&mp[nr][nc] == -1) {
mp[nr][nc] = nd;
q.push(pos(nr, nc, nd));
}
}
}
}我们可以看到 DFS和BFS的差别还是有很多的 我们把两个代码对比看一下


一个是递归 一个是用到了队列的这个容器 大致的写法结构是完全不同
周总结
第一天的贪心算法我没有写进里面 我觉得贪心是相对比较简单的一个算法,所以我就没有写进去 那时候的几个习题做的也还可以 之后的二叉树以及几个搜素确实是比较难理解的 对于剪枝还是没能很好理解它的概念和用法 希望下周能抽时间去看一下竞赛书的能容 这周的有些写法也还不是很熟悉 希望继续加油 勉励















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









