







在开始这周的总结之前,我先把map的取值赋值以及输出写一下
#include<bits/stdc++.h>
using namespace std;
int main() {
map<char, int>m;
for (int i = 0; i < 2; i++) {
char x;
int y;
cin >> x >> y;
m.insert(pair<char, int>(x, y));
}
for (auto it = m.begin(); it != m.end(); it++) {
cout<< it->first<<" "<<it->second << endl;
}
}(怕自己忘记)
这周讲了很多算法 也有一两个算法是我没有完全理解的 我就跟着题目一点点讲自己对于每个算法的理解吧
(一)排序和排列
对于排序和排列 我们有很多种方法,常见的老三样:选择排序、插入排序、冒泡排序。这个是我们一开始学习的排序方法,但在数据过大时,很显然,对于O(n^2)的时间复杂度,很容易就超时了,这个时候我们就有另外一些时间复杂度较小的算法降临了:快速排序、归并排序、快速排序....等等。今天我们就着重来讲这三种排序。
在讲之前呢,我们先分享一个stl函数 next_permutation 它是干什么的 是输出一个比一个大的数或数组或者字符 可以说它是全能的 要记住,next_permutation 是从当前的全排列开始,逐个输出更大的全排列,而不是输出所有的全排列 例如:
#include<bits/stdc++.h>
using namespace std;
int main() {
int a[3];
for (int i = 0; i < 3; i++) {
cin >> a[i];
}
sort(a, a + 3);
do{
for(int i = 0; i < 3; i++) {
cout << a[i]<<" ";
}
cout << endl;
} while (next_permutation(a, a + 3));
return 0;
}
输入:
6 2 5
输出结果:
2 5 6
2 6 5
5 2 6
5 6 2
6 2 5
6 5 2.
你可以发现它按照每个数字的大小依次给你排序输出来了 这个就适合某种场景 要记住,next_permutation是给你排更大的数,而不是从小到大依次给你排 如果你没有前面的sort函数,那么你的输出可就大大不相同,不信我们试试:
#include<bits/stdc++.h>
using namespace std;
int main() {
int a[3];
for (int i = 0; i < 3; i++) {
cin >> a[i];
}
do{
for(int i = 0; i < 3; i++) {
cout << a[i]<<" ";
}
cout << endl;
} while (next_permutation(a, a + 3));
return 0;
}
输入
6 2 5
输出结果:
6 2 5
6 5 2
看吧 他就是这么有个性 ,你不给他先从小到大排序好他还不会按你的想法来。
(1)快速排序
一看到快速排序,我们脑子里一闪而过的肯定就是sort函数 sort函数的用法就不多说了,复杂度是O(nlogn) sort可以对很多数据类型进行排序 这个貌似在前面讲到过(记不清了~~) 接下来用一个sort对结构体函数来排序的题目作为讲解
奖学金(洛谷P1093)
某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前 55 名学生发奖学金。期末,每个学生都有 33 门课的成绩:语文、数学、英语。先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学 排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的 33 门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前五名名学生的学号和总分。注意,在前 55 名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分) 是:
77 279279
55 279279这两行数据的含义是:总分最高的两个同学的学号依次是 77 号、55 号。这两名同学的总分都是 279279 (总分等于输入的语文、数学、英语三科成绩之和) ,但学号为 77 的学生语文成绩更高一些。如果你的前两名的输出数据是:
55 279279
77 279279则按输出错误处理,不能得分。
输入格式
共 n+1n+1行。
第 11 行为一个正整数n ( \le 300)n(≤300),表示该校参加评选的学生人数。
第 22 到 n+1n+1 行,每行有 33 个用空格隔开的数字,每个数字都在 00 到 100100 之间。第 jj 行的 33 个数字依次表示学号为 j-1j−1 的学生的语文、数学、英语的成绩。每个学生的学号按照输入顺序编号为 1\sim n1∼n(恰好是输入数据的行号减 11)。
所给的数据都是正确的,不必检验。
输出格式
共 55 行,每行是两个用空格隔开的正整数,依次表示前 55 名学生的学号和总分
输入样例
6 90 67 80 87 66 91 78 89 91 88 99 77 67 89 64 78 89 98输出样例
6 265 4 264 3 258 2 244 1 237
代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 305;
struct x {
int chinese;
int math;
int eng;
int zong;
int id;
};
x a[N];
bool cmp(x a, x b) {
if (a.zong == b.zong&&a.chinese!=b.chinese) {
return a.chinese > b.chinese;
}
else if(a.zong==b.zong&&a.chinese==b.chinese){
return a.id < b.id;
}
else if(a.zong!=b.zong){
return a.zong > b.zong;
}
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i].chinese >> a[i].math >> a[i].eng;
a[i].zong = a[i].chinese + a[i].eng + a[i].math;
a[i].id = i + 1;
}
sort(a, a + n, cmp);
for (int i = 0; i < 5; i++) {
cout << a[i].id << " " << a[i].zong << endl;
}
}这个代码就不做解释了,一个简单的sort对于结构体的排序,其实很简单,看不清题目的大伙可以去洛谷那边看,那既然这个题目简单,那引出这个题目是为了什么呢?众所周知,sort的快排复杂度是O(nlogn),并不是最简单的O(n),所以在一些数据刁钻的情况下我们是可能时间超了的,比如:
求第k小的数字(洛谷p1923)
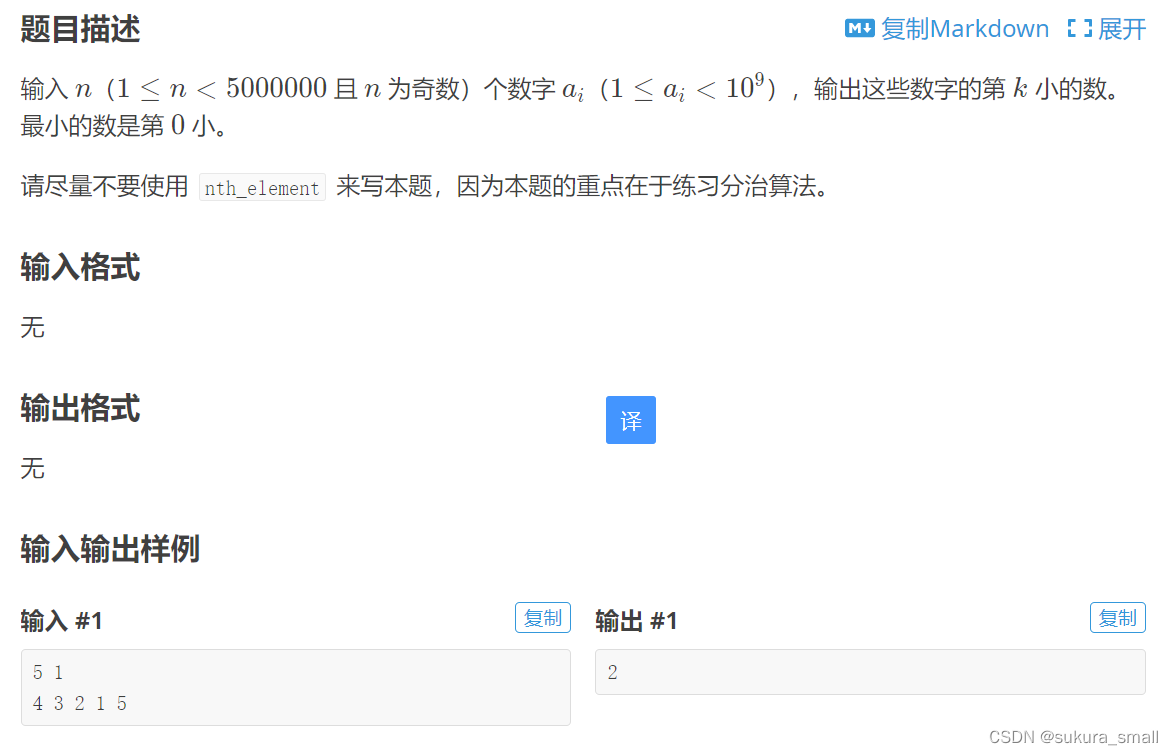
这边我们可以见到 那个n的范围是5*1e6次,如果不知道如何计算复杂度的 那我们就试着用经典的快排跑一下这个题目
结果是这样的
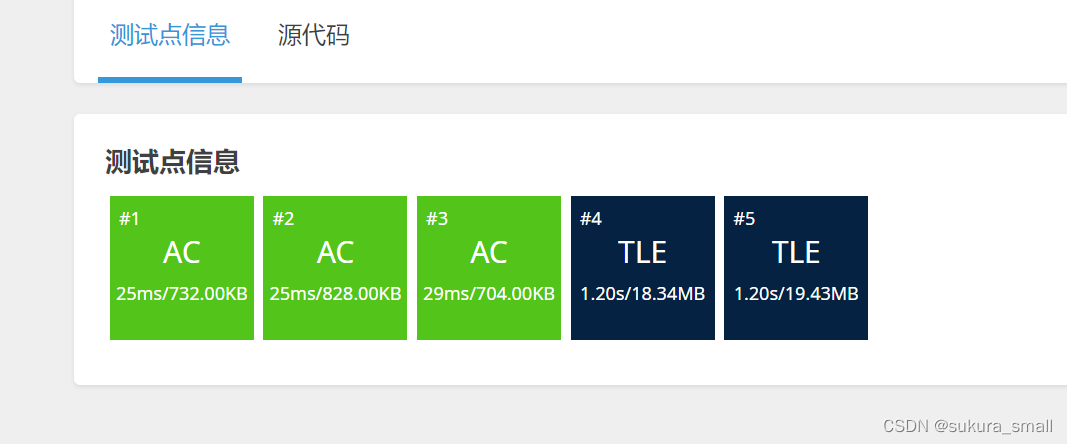
很不难看出后面的两个测试点全部超时了,这说明O(nlogn)的复杂度对于这个题目的数据来说也是时间超的,这时候就需要超人,也就是O(n)复杂度的算法来救世了。我的能力肯定想不出如何去优化,直到我看了洛谷题解里面有一种比较巧妙的解题思想(大家如果想进一步了解他怎么说的,可以自己去洛谷搜这个题目然后去搜索题解) 他用到一个三分的思想,因为快排的思想其实是二分,然后我们在这个基础上优化,变成三分,那么复杂度就随之而之的降低了
具体代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5;
int x[N];
int k;
void qsort(int l, int r) {
int i = l;
int j = r;
int mid = x[(l + r) / 2];
do {
while (x[j] > mid) {
j--;
}
while (x[i] < mid) {
i++;
}
if (i <= j) {
swap(x[i], x[j]);
i++;
j--;
}
} while (i <= j);
//数据被划分为三块 l<=j<=i<=r;
if (k <= j) {
qsort(l, j);//搜索左区间
}
else if (i <= k) {//搜索右区间
qsort(i, r);
}
else {
cout << x[j + 1];//在中间说明找到了 直接输出
exit(0);
}
}
int main() {
int n;
cin >> n >>k;
for (int i = 0; i < n; i++) {
scanf("%d",&x[i]);
}
qsort(0, n - 1);
}由这个题目我由此引发,如果对于一些数据较大的题目,当不能用sort排序的时候 他又让你求第几个数字的大小时,我们可以用这个代码或者思想 因为k是可以变得 他代表我们要求的第几个数字。
(2)归并排序
归并排序就是一个拆分开来再合上这么一个过程 (大概是这样)

按上面的图片来理解应该能很好理解 它的算法复杂度是O(nlogn) 跟快速排序的复杂度是一样的
接下来是他的代码模板:
#include<bits/stdc++.h>
using namespace std;
const int N = 5 * 1e6+10;
int box[N];
int mark[N];
long long ans = 0;
void merge_sort(int left, int right) {
if (left < right) {
int mid = (right + left) / 2;
int k = left;
int p = left;
int q = mid + 1;
merge_sort(left, mid);
merge_sort(mid + 1, right);//递归一直细分
while (p <= mid && q <= right) {
if (box[p] <= box[q]) {//在box里面的数字是没有算是排过序的数字 把它从中间分成两半
//然后p是左端 q是右端 来比较是左端的数字比较大还是右边的数字比较大 然后来排序 这个排序是你能控制的 你想让大的放前面那么就输入box[q++]
//想让小的放前面那么就是像我下面写的
mark[k++] = box[p++];
}
else {
mark[k++] = box[q++];
}
}
//这两个是判断什么?防止就是 左右有一方全部放进去了 但是有一方还有数字没有放进mark数组里面 那么这个时候就来写下面这串代码防止这种方式出现
while (p <= mid) {
mark[k++] = box[p++];
}
while (q <= right) {
mark[k++] = box[q++];
}
for (int l = left; l <= right; l++) {
box[l] = mark[l];
}
}
else {
return;
}
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >>box[i];
}
merge_sort(1, n);//这边已经排好了 可以输出了
return 0;
}这个就是基础的归并排序的代码模板 接下来我们看几道有关的例题:
逆序对(洛谷p1908)
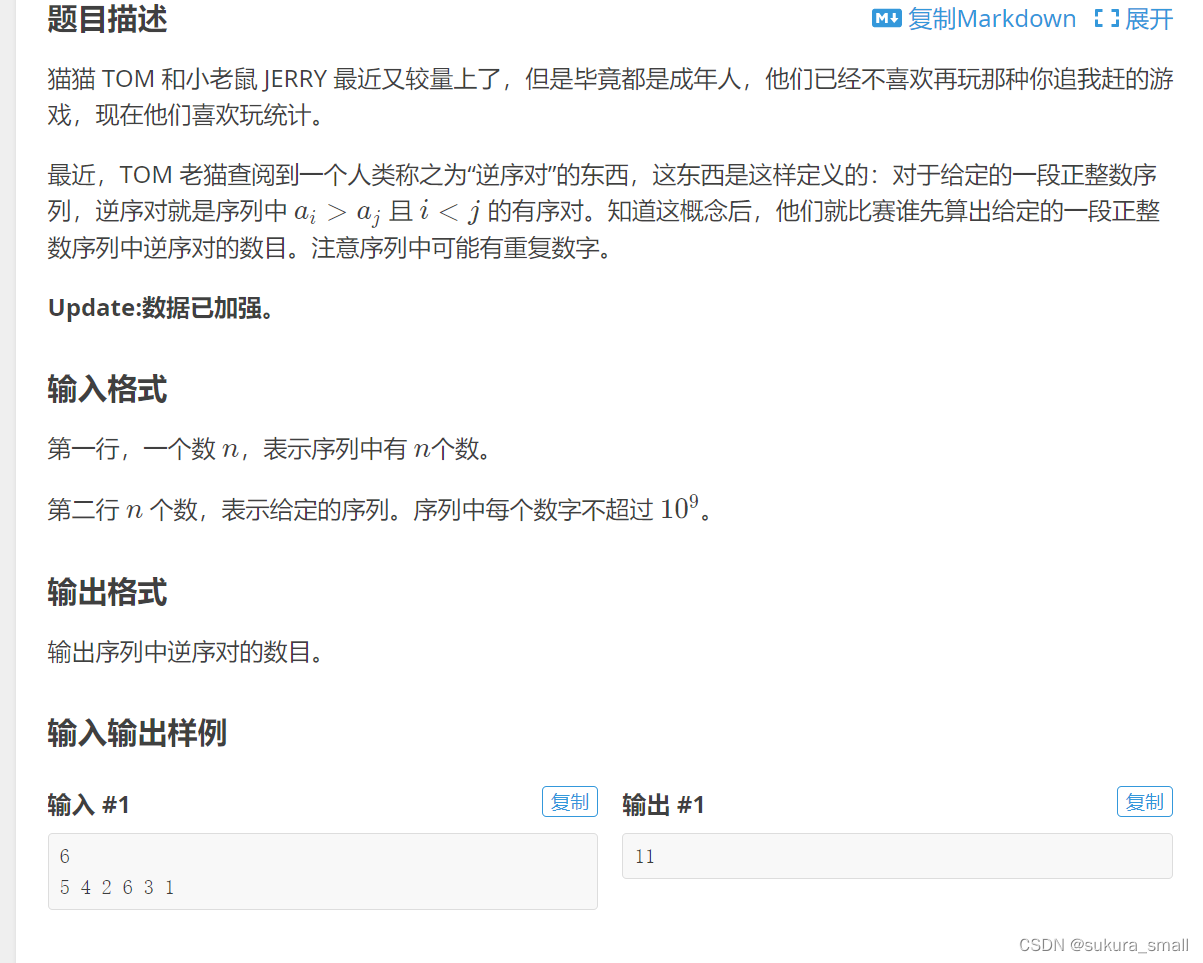
这个题目就可以用到这个方法
如果我们想要将一个序列排成从小到大有序的,那么每次划分后合并时左右子区间都是从小到大排好序的,我们只需要统计右边区间每一个数分别会与左边区间产生多少逆序对即可。
比如在某个时刻
左区间 的数字为 5 6 7 右区间1 2 9 左右两个区间的下标分别为 i j 这个时候我们开始合并 5 6 7对1 产生了逆序 那么数字加一 5 6 7 对2产生了逆序 那么又加一次 后面就都比9小 那么就不加 ,所以我们只要在原有代码的基础加一个 当左边的数比右边的大的时候 在原有mark[k++]=box[q++]的基础上加一个 ans+=mid-i+1; 这个就相当于有几个逆序 接下来就是完整代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 5 * 1e6+10;
int box[N];
int mark[N];
long long ans = 0;
void merge_sort(int left, int right) {
if (left < right) {
int mid = (right + left) / 2;
int k = left;
int p = left;
int q = mid + 1;
merge_sort(left, mid);
merge_sort(mid + 1, right);
while (p <= mid && q <= right) {
if (box[p] <= box[q]) {
mark[k++] = box[p++];
}
else {
mark[k++] = box[q++];
ans += mid - p + 1;
}
}
while (p <= mid) {
mark[k++] = box[p++];
}
while (q <= right) {
mark[k++] = box[q++];
}
for (int l = left; l <= right; l++) {
box[l] = mark[l];
}
}
else {
return;
}
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >>box[i];
}
merge_sort(1, n);
cout << ans;
return 0;
}只要我们知道这题和归并有关系并且能理解我上述的那个思想 其实挺简单的。当然注意ans是longlong型的(这个思路是洛谷上面的题解分享的 如果有不懂的可以自己去洛谷对应的题目的题解那边去再仔细看看思考理解一下)
(3)快速幂
快速幂就是运用了一个二进制的一个思想,一般代码如下:
#include<bits/stdc++.h>
using namespace std;
long long math(long long base, long long power) {
long long result = 1;
while (power) {
if (power % 2 == 1) {// 核心思想就是把那个指数当成二进制来看
//就比如说3 二进制是011 那么 第一步 3%2==1 那么就result乘以
//base 然后power/2变成1 base是什么呢 base就相当于下面逐渐变大增倍的
//指数 然后if判断那个指数是否是1 是1那我就给他乘 其实就是二进制;
result *= base;
}
power =power/ 2;
base *= base;
}
return result;
}
int main()
{
int n, m;
cin >> n >> m;
cout << math(n, m);
return 0;
}但当m 和n的值很大的时候,可能里面的数据会超范围,所以一般我们都会mod一个数
比如下面的那个代码就是对m取余
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll fastpow(ll a, ll n, ll m) {
if (n == 0) return 1;
if (n == 1) return a;
ll temp = fastpow(a, n / 2, m);
if (n % 2 == 1) {
return temp * temp * a % m;
}
else {
return temp * temp % m;
}
}
int main() {
ll a, n, m;
cin >> a >> n >> m;
cout << fastpow(a, n, m);
return 0;
}
(二)前缀和与差分
可以理解为前n项数列和 sum[i]=a[i]+a[i-1]+a[i-2]+.......+a[0];
差分就是前缀和的倒过来的一个形式
接下来看几个有关前缀和与差分的题目
color the ball(HDU1556)
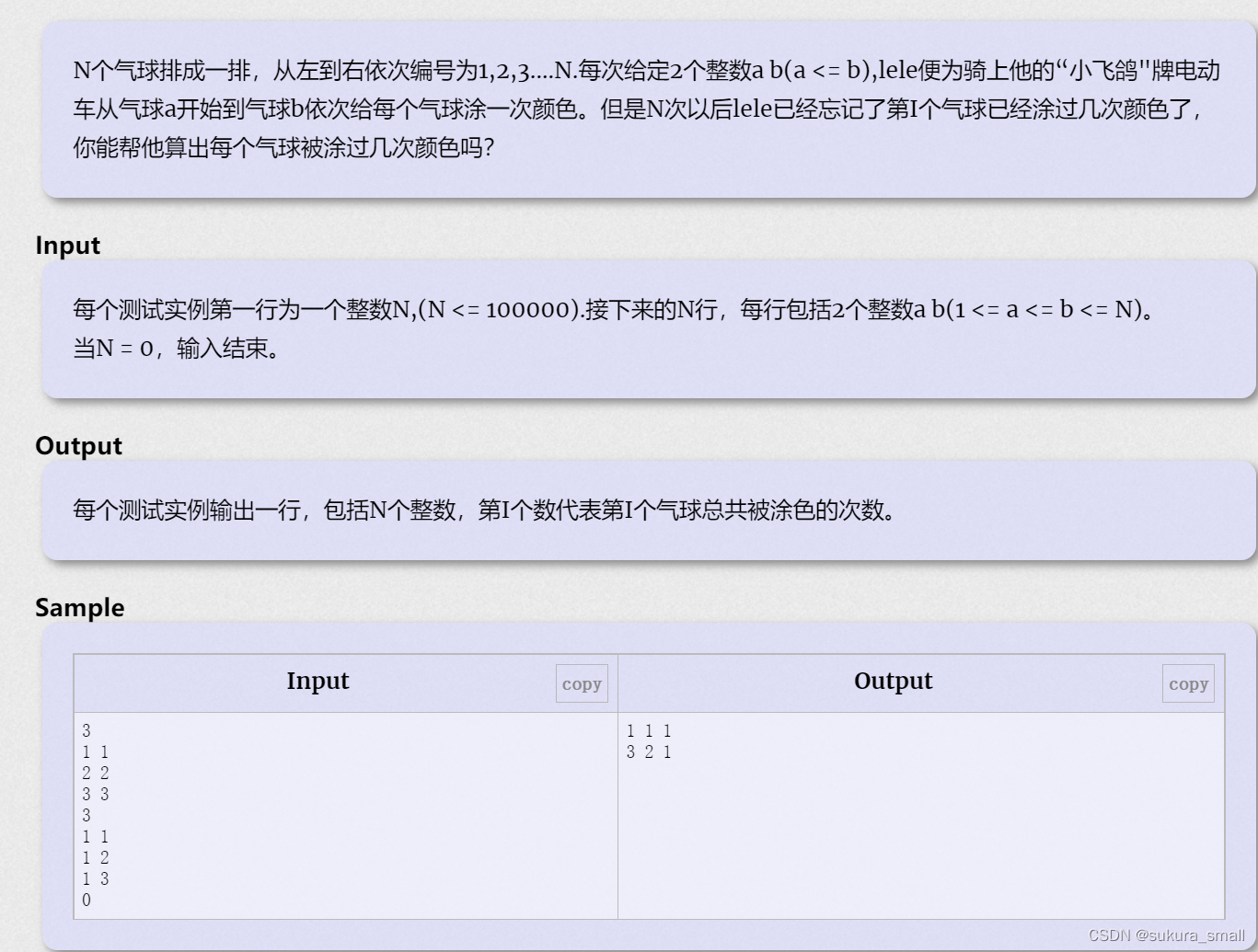
代码:
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
int n;
int a[100005];
int D[100005];
while (cin >> n)
{
if (n == 0) {
break;
}
memset(a, 0, sizeof(a));
memset(D, 0, sizeof(D));
for (int i = 1; i <= n; i++) {
int l, r;
cin >> l >> r;
D[l]++;//从D[i]开始就加1 说明加过了
D[r + 1]--;//从D[r+1]开始变成原来的 给他--
}
for (int i = 1; i <= n; i++) {
a[i] = a[i - 1] + D[i];//开始统计每个a[i]
if (i != n) {
cout << a[i] << " ";
}
else {
cout << a[i] << endl;
}
}
}
return 0;
}这个题目就是运用了一个前缀和 如果用一般的暴力去用一个双重循环就会超时 用前缀和就很好的弥补了这一个漏洞
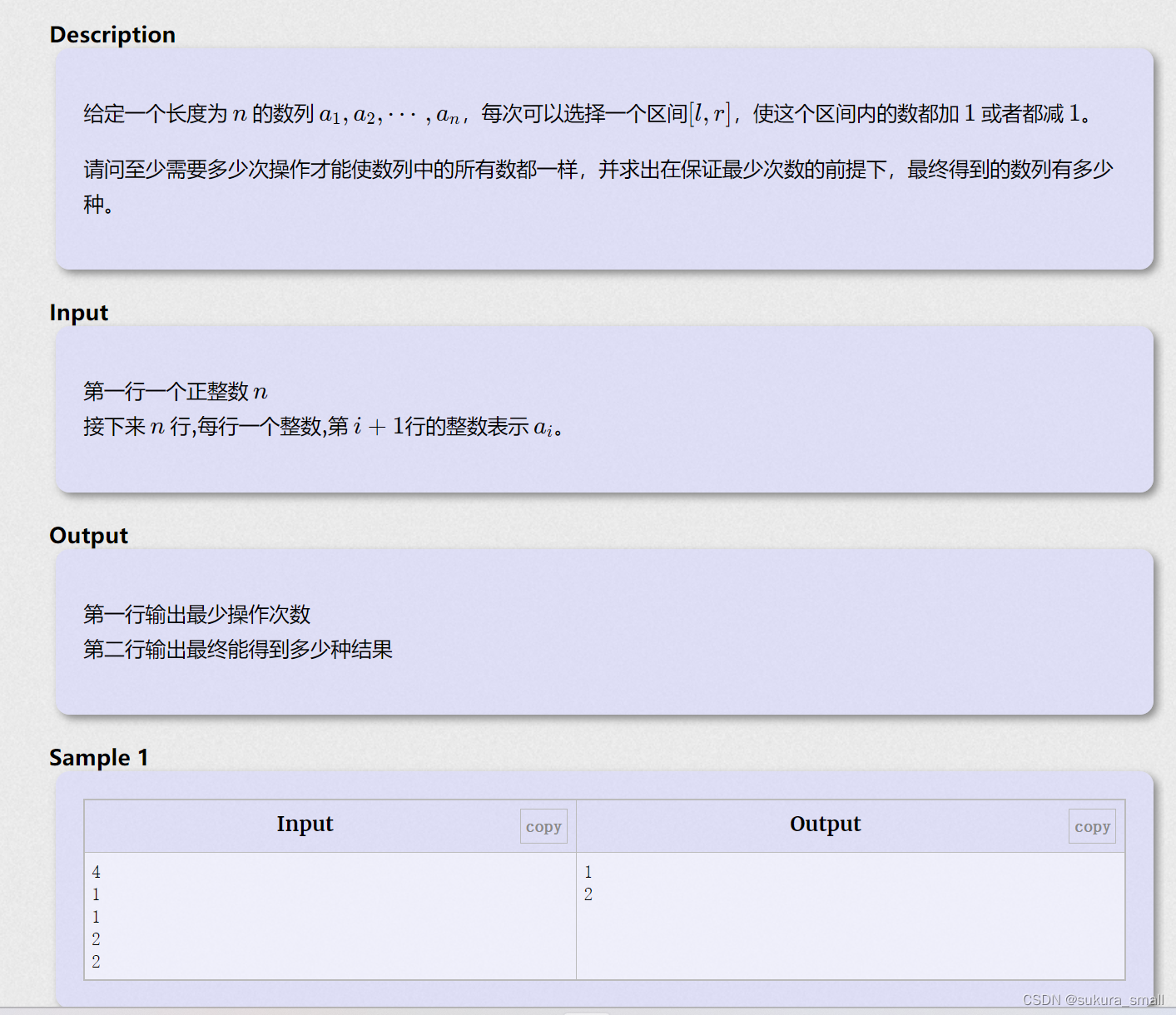
IncDec Sequence(洛谷p4552)
代码:
#include<bits/stdc++.h>
using namespace std;
long long a[100010];
long long b[100010];
int main() {
long long n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
b[i] = a[i] - a[i - 1];
}
long long q = 0, p = 0;
for (int i = 2; i <= n; i++) {
if (b[i] > 0) {
q = b[i] + q;
}
else if (b[i] < 0) {
p = p - b[i];
}
}
long long ans1 = max(q, p);
long long ans2 = abs(q - p) + 1;
cout << ans1 << endl << ans2;
return 0;
}这个题目是差分 我们每次输[a[i]的时候 计算b[i] 它的值是a[i]-a[i-1] 它是来干啥的呢?它是来判断第i个数比前面的数大或小多少 这能用来干啥呢?我们后面判断要走几次的时候就靠这个 比如说 我一趟走完 大于0的b[i]有9个 小于0的b[i]有6个 那么在操作的时候我们是否可以在增大一个数的情况下同时减小另一个数来达到两边中和 这个q和p就是起到了这个作用 中和的次数是min(q,p) 然后剩下的是只有小于0或者只有大于0的部分 那么接下来的操作次数就是abs(q-p) 那么其实加起来的两个操作次数是max(q,p) 所以上面的ans1就等于max(q,p) 至于有几种排列的顺序 得到的数列有多少种,其实就是问的b[1]可以有多少种 我们上述所有操作是与b[1]无关的,因为我们的目标是让除了b[1]以外的项变0,所以我们上述的操作没有考虑到b[1],b[1]怎么变,与我们求出的最小步骤无关 那么,我们怎么知道b[1]有几种呢?很简单,其实就是看看有几种一步步减或一步步 加的操作数,因为我们一步步加的时候(假设我们现在的操作对象下标为i),可以这样操作,b[1] - 1, b[i] + 1 一步步减的时候可以这样操作,b[1] + 1, b[i] - 1(注意,一个差分序列里一步步操作的时候只可能一步步加或一步步减,不可能一步步加和一步步减同时存在)所以说,有几步一步步的操作就有几种情况 + 1,为什么 + 1呢,因为这个b[1]本身就有一个值啊!就算你不对他进行任何操作,它自己也有一种情况。
(三)二分法
当问题单调的时候 让我们在这个有序数列里面找某个符合条件的值得时候 我们可以考虑用二分这个方法 它的算法复杂度是O(logn) 下面我们看几个有关于它的例题:
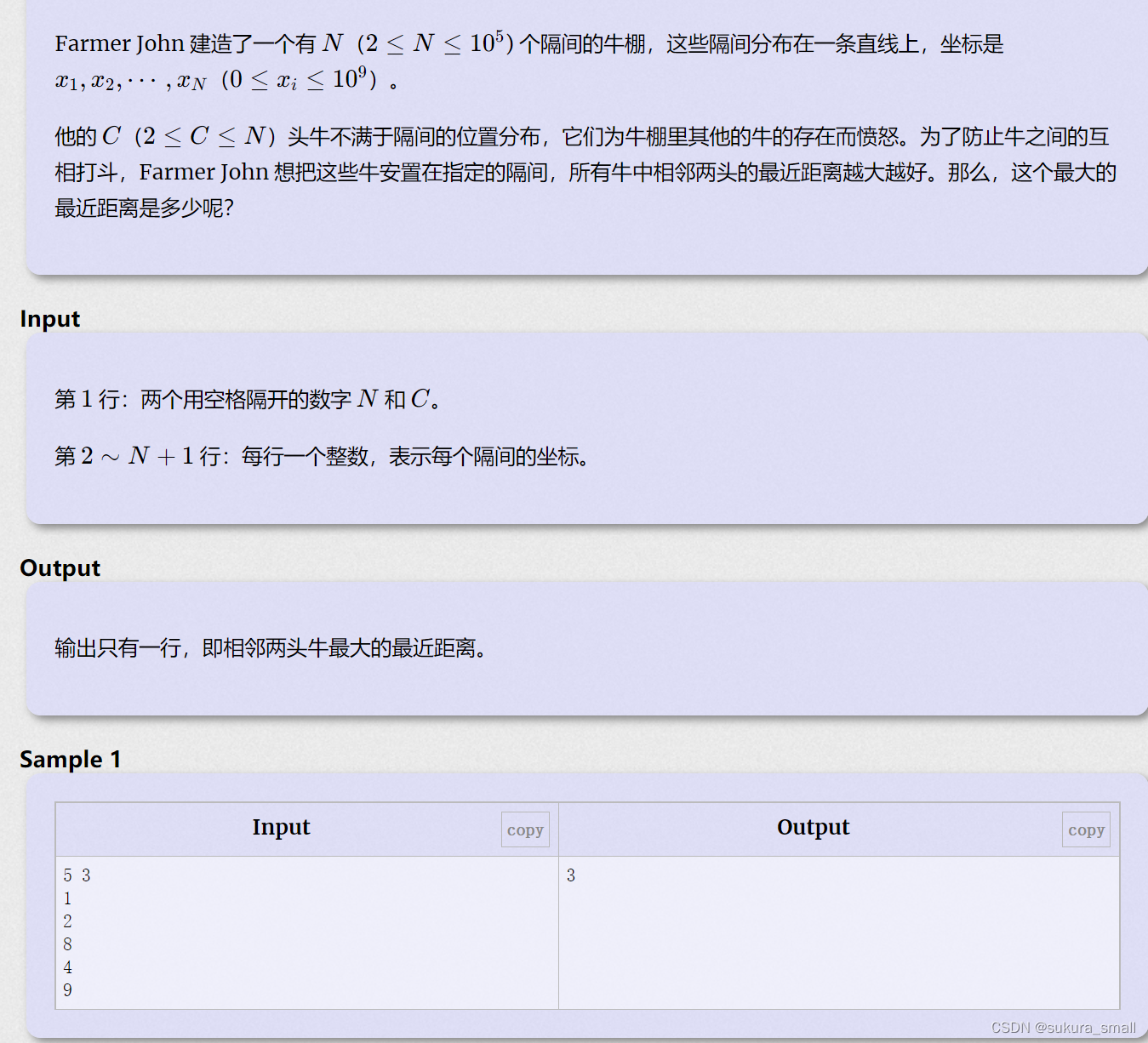
进击的奶牛(洛谷p1824)
代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 + 5;
int x[N];
int n, c;
bool check(int dis) {
int cnt = 1;
int place = 0;
for (int i = 1; i < n; ++i) {
if (x[i] - x[place] >= dis) {
cnt++;
place = i;
}
}
if (cnt >= c) {
return true;
}
else {
return false;
}
}
int main() {
cin >> n >> c;
for (int i = 0; i < n; i++) {
cin >> x[i];
}
sort(x, x + n);
int left = 0;
int right = x[n - 1] - x[0];
int ans = 0;
while (left < right) {
int mid = (left + right) / 2;
if (check(mid)) {
ans = mid;
left = mid + 1;
}
else {
right = mid;
}
}
cout << ans;
return 0;
}这个题目就是以个经典的二分法的题目 我们可以看到题目里面的N的范围是2*1e5 所以双重循环是肯定不可以的 题目中的check函数就是判断是否这个数输进去是最大的距离 如果这个数比当前的最大距离大 那我们就继续往右边走,让left等于mid+1 继续判断 然后最后求得一个最大的距离
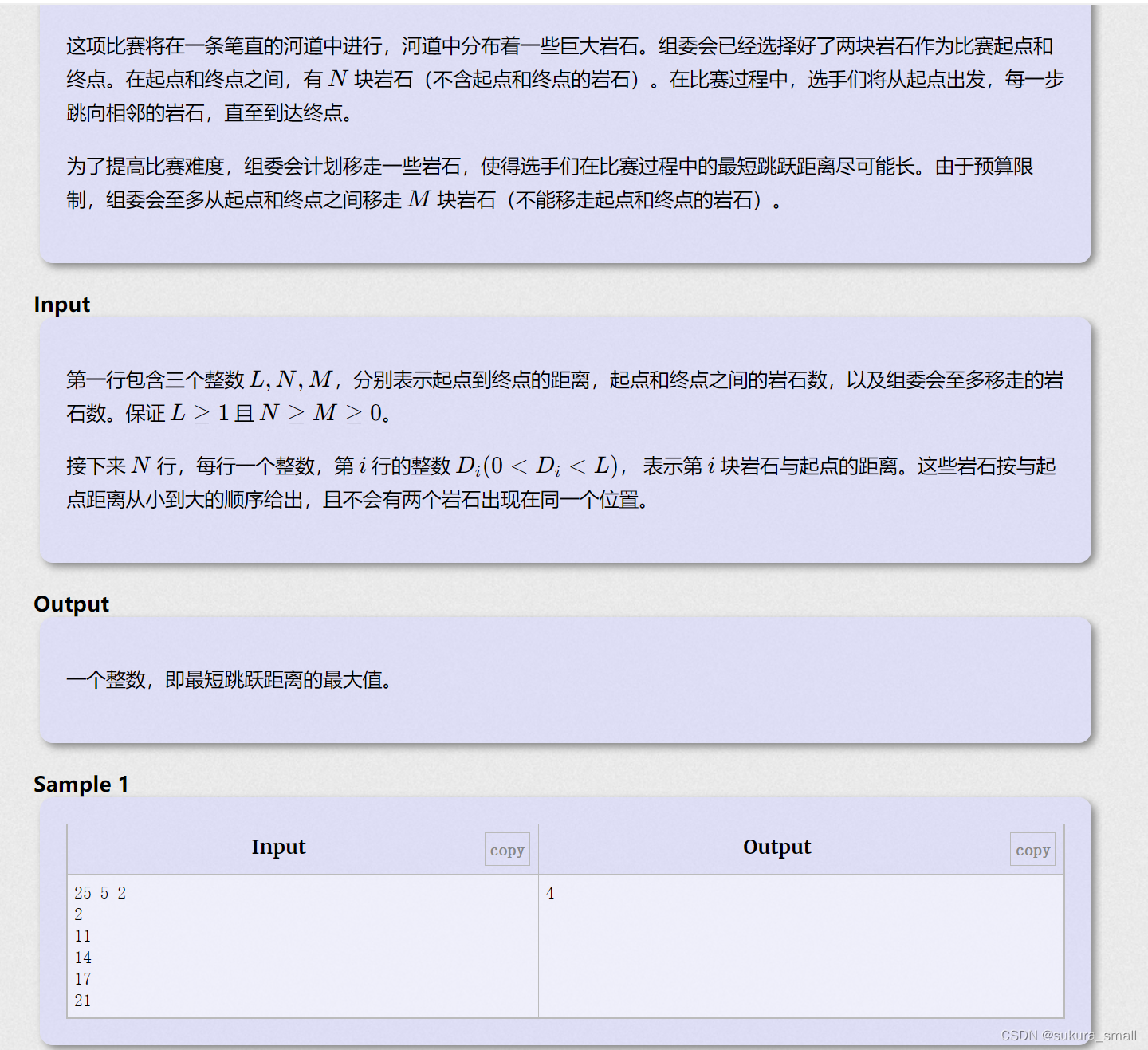
跳石头(洛谷p2678)
代码
#include<bits/stdc++.h>
using namespace std;
int l,n,m;
//l是长度,n是石头数量,m是移走的石头数量
int answer;
//最终答案
int a[50005];
//每块石头的距离
bool Find(int len){
//看看二分答案是大还是小
int now=0;
//当前的前一块石头
int have=0;
//保留的石头数量
for(int i=1; i<=n+1; i++)
if(a[i]-a[now]>=len)
have++,now=i;
if(have>=n-m+1)
return true;
else
return false;
}
void ef_do(){
//二分
int le=0,mid,ri=a[n+1];
//左中右指针
while(le<=ri){
//二分过程
mid=(le+ri)/2;
//取中间值
if(Find(mid))
answer=mid,le=mid+1;
else
ri=mid-1;
//根据Find函数调整指针
}
}
int main(){
cin>>l>>n>>m;
for(int i=1; i<=n; i++)
cin>>a[i];
//输入
a[n+1]=l;
//最后一块是中点
ef_do();
//二分
cout<<answer;
//输出
return 0;
}这个是洛谷上的一个题解 是从正面来做的 我的做法是反着来做的 也就是我能有几个石头去踩 具体代码是下面:
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <stdlib.h>
#include <math.h>
#include<algorithm>
using namespace std;
const int M = 1e5 + 5;
int a[M];
int l, m, n;
bool cmp(int x) {
int num = n - m;
int last = 0;
for (int i = 0; i < num; i++) {
int cur = last + 1;
while (cur <= n && a[cur] - a[last] < x) {
cur++;
}
if (cur > n) {
return 0;
}
last = cur;
}
return 1;
}
int main() {
cin >> l >> n >> m;
if (n == m) {
cout << l << endl;
return 0;
}
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
a[0] = 0;
a[n+1] = l;
sort(a, a + n + 2);
int left = 0;
int right = l;
while (right - left > 1) {
int mid = (left + right) / 2;
if (cmp(mid)) {
left = mid;
}
else {
right = mid;
}
}
cout << left << endl;
return 0;
}这个就是 num就是我有几个石头可以踩 然后去判断这个距离是否可以做成最小距离的最大值 然后再去判断主函数是往左走还是往右走 但是这个代码在洛谷上提交 最后一个测试点是wa 是过不了的 但在poj3258的同一个题目提交是可以的 我也不清楚 可能是哪里的测试数据多了一份 所以还是正着来好了
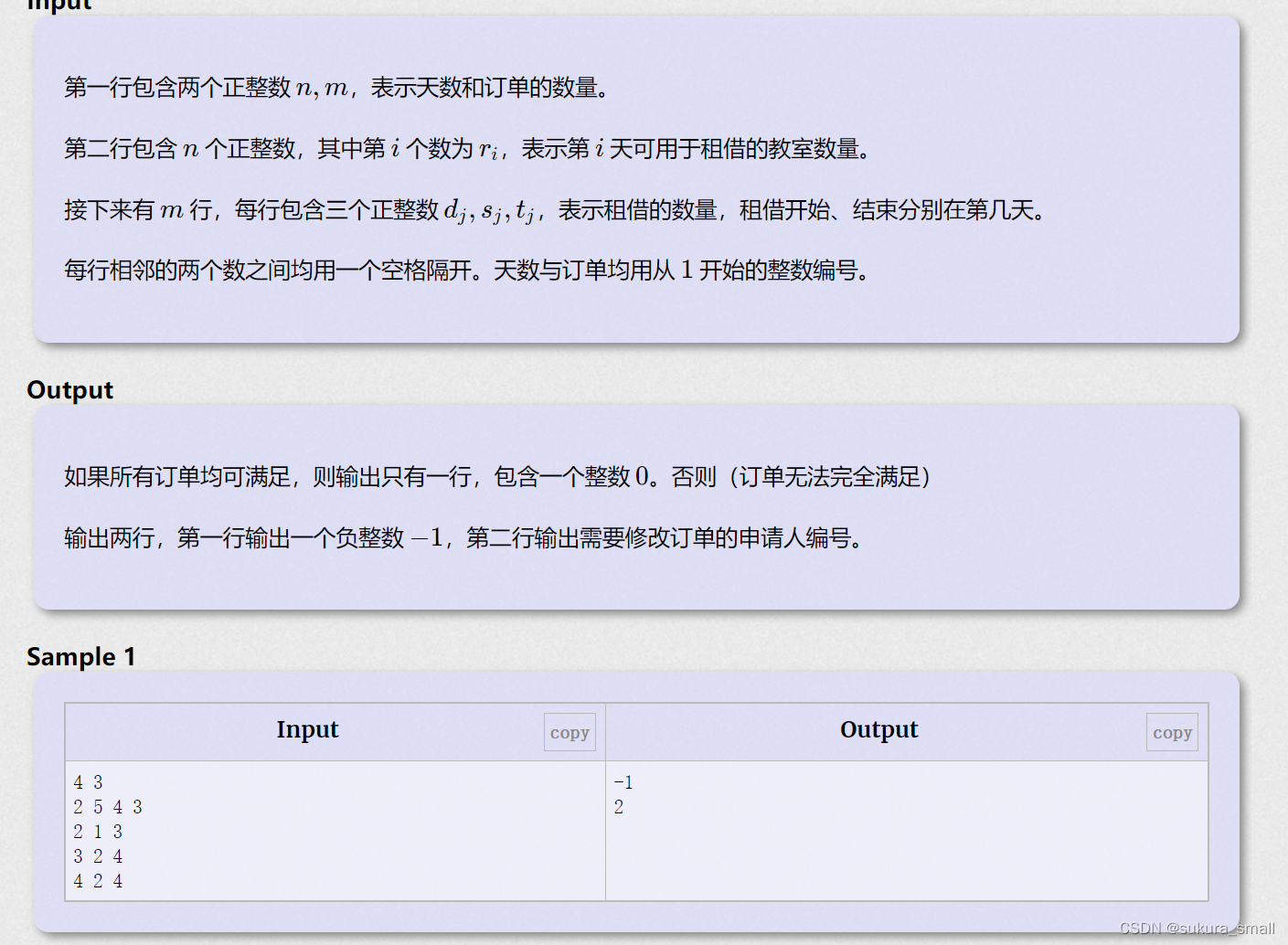
借教室(洛谷P1083)

代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
int n, m;
long long diff[1000011], need[1000011], rest[1000011], r[1000011], l[1000011], d[1000011];
bool isok(long long x)
{
memset(diff, 0, sizeof(diff));
for (int i = 1; i <= x; i++)
{
diff[l[i]] += d[i];
diff[r[i] + 1] -= d[i];
}
for (int i = 1; i <= n; i++)
{
need[i] = need[i - 1] + diff[i];
if (need[i] > rest[i])return 0;
}
return 1;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)scanf("%d", &rest[i]);
for (int i = 1; i <= m; i++)scanf("%d%d%d", &d[i], &l[i], &r[i]);
long long begin = 1, end = m;
if (isok(m)) { cout << "0"; return 0; }
while (begin < end)
{
long long mid = (begin + end) / 2;
if (isok(mid))begin = mid + 1;
else end = mid;
}
cout << "-1" << endl << begin;
}这是一个前缀和加上二分的这么一个组合 cmp的函数就是在判断当天的教室是否够 如果不够那么就return false 大体思路是简单的 用二分来做的话
(四)双指针和尺取法
尺取法也就是双指针 它的思想是什么 当你面对一堆数组的时候 你要查找某个符合条件的数可能有时候需要用到双重循环很容易就超时 那么这个时候呢 就用两个下标去走这个循环 这个就叫双指针
在尺取法中有两个扫描方法:
(1)反向扫描:i和j的方向相反,i从头到尾,j从尾到头,在中间会和。
(2)同向扫描:i和j方向相同,都从头到尾,速度不同,如让j跑在i的前面
接下来我们看几个题目
回文字符串(HDU2029)
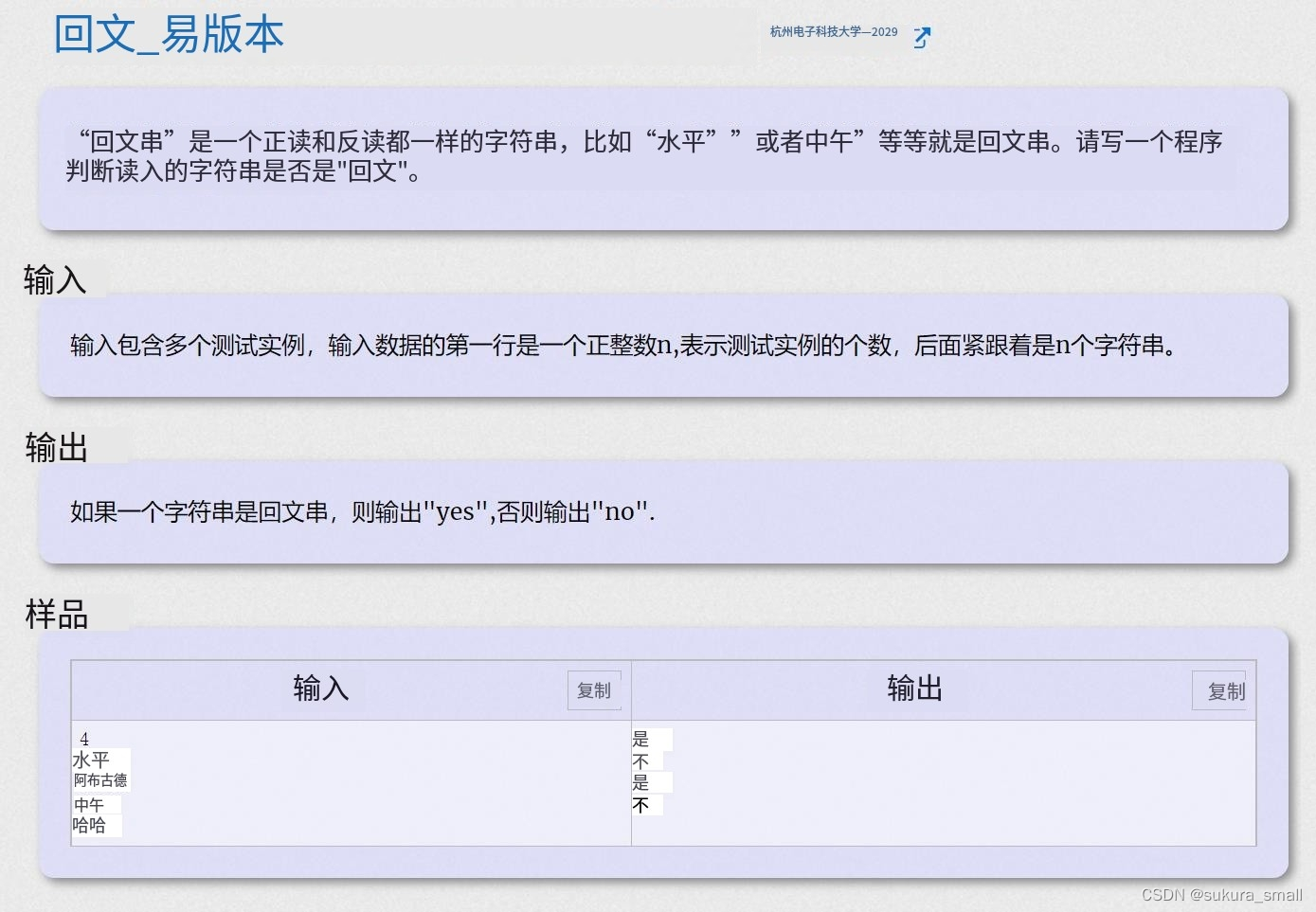
代码:
#include<iostream>
#include<string>
using namespace std;
int main() {
int n;
cin >> n;
while (n--)
{
string s;
cin >> s;
int flag = 0;
if (s.length() % 2 == 0) {
int i = 0;
while (i <= s.length() / 2) {
if (s[i] != s[s.length() - i - 1]) {
flag = 1;
break;
}
i++;
}
if (flag == 1) {
cout << "no" << endl;
}
else {
cout << "yes" << endl;
}
}
else {
int i = 0;
while (i <= s.length() / 2) {
if (s[i] != s[s.length() - i - 1]) {
flag = 1;
break;
}
i++;
}
if (flag == 1) {
cout << "no" << endl;
}
else {
cout << "yes" << endl;
}
}
}
return 0;
}emm这个题目貌似我没有用双指针来做 我直接用暴力来写 然后我去网上查找了用双指针方法来写的方法 代码在下面:
#include<iostream>
#include<cstring>
using namespace std;
int main() {
int n, m, len;
char* pf, * pl, s[50];
cin >> n;
while (n--){
cin >> s;
len = strlen(s);
pf = pl = s;
pl += (len - 1);
m = 1;
while (m < len / 2){
if (*pf != *pl){
cout << "no" << endl;
break;
}
pf++; pl--; m++;
}
if (m == len / 2)
cout << "yes" << endl;
}
}其实这个题目是简单的 就是让我们能更好理解双指针的用途 如果数据再大一点话我们的暴力就用不了 这个时候就得用到我们的双指针了 哦对了 他的算法复杂度是O(nlogn);
A-B数对(洛谷P1102)
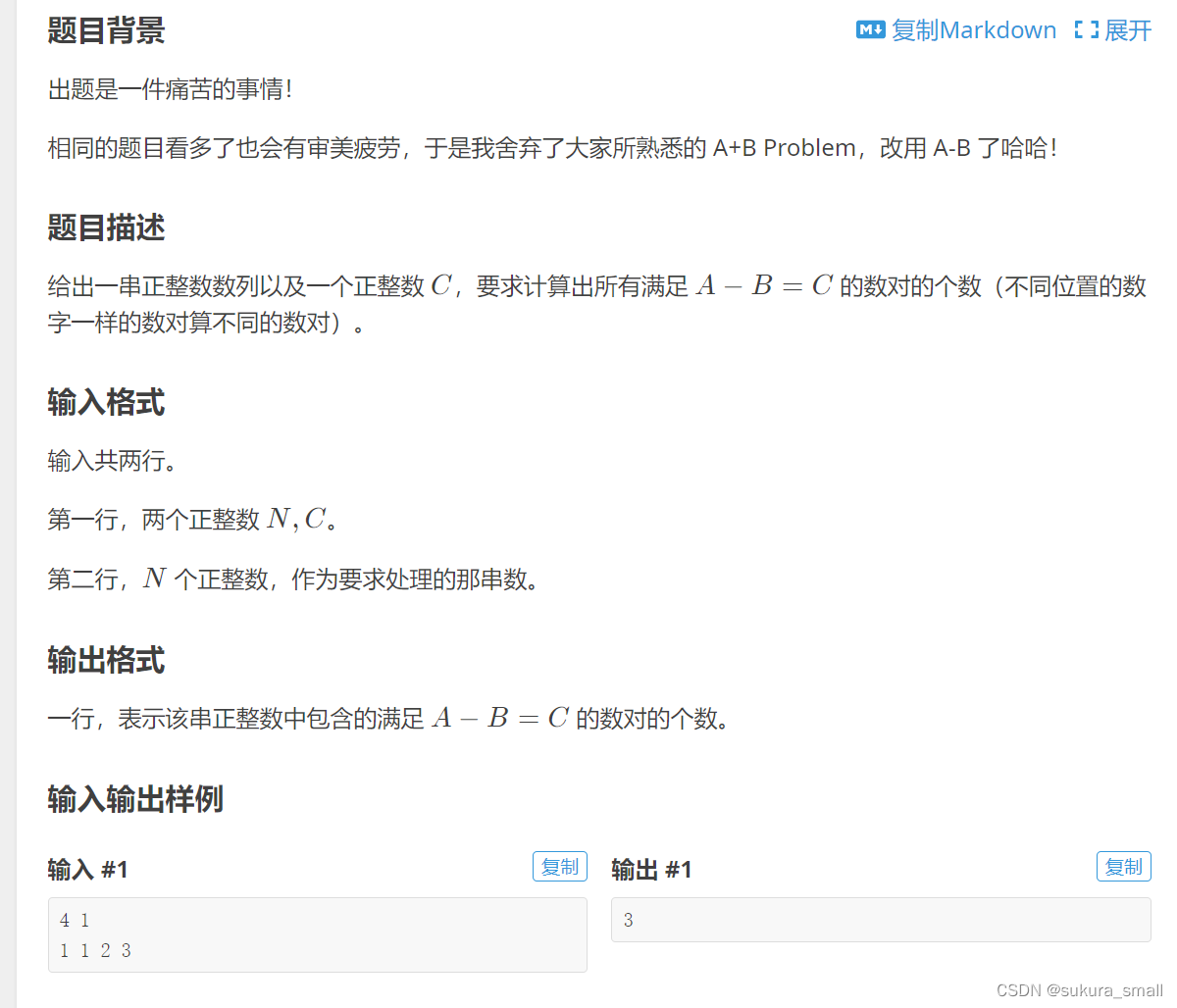
代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 5;
int a[N];
int main() {
int n, c;
cin >> n >> c;
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
int j1 = 1;
int j2 = 1;
long long ans = 0;
sort(a + 1, a + n + 1);
for (int i = 1; i <= n; i++) {
while (j1 <= n && a[j1] - a[i] <= c) {
j1++;
}
while (j2 <= n && a[j2] - a[i] < c) {
j2++;
}
if (a[j2] - a[i] == c && a[j1 - 1] - a[i] == c) {
ans = ans + j1 - j2;
}
}
cout << ans;
return 0;首先我截图的时候没有把N的范围截进去,N是小于等于2*1e5 显而易见 这个题目我们用暴力肯定是超时的,那这个题目就很好的体现了我们尺取法的妙用。首先定义两个下标 j1 j2 j1负责判断右区间 j2负责判断左区间 这个j1 j2在的目的就是防止有一段数据的大小时一样的 然后后面的ans就是ans+=j1-j2 这个双指针在这个时候就体现出来用处了
周总结
这周学了很多很多的算法 但其实还有一个算法我没在上面讲 那就是倍增法和st表 这个算法我到目前为止还是不怎么理解 对于我来说这个算法理解起来不难 但是写成代码运用到题目里面来说对我来讲有点抽象了 等个两三天 等我真的再进一步理解这个算法的时候 我会把这个理解内容以及习题的讲解放在单独的一篇来进行讲解 算是这周的补充 其他的算法也是一个皮毛吧 还是要做更多的题目来巩固 emm 归并排序也是一个要去多理解的一个对象 下周继续吧我只能说 毕竟第三周(理论上的第二周)刚结束 确实感觉越学越吃力 希望自己能继续坚持下去 噶油!!!















 1841
1841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









