






一、概念
正则表达式是一种匹配方式,用于对字符串里的子字符串进行提取、修改、替换等操作,通过re模块实现。
re模块共有三个主要方法:
1.re.match(pattern, string, flags=0):匹配字符串的开头,如果匹配成功则返回完整匹配字符串;
注意:只检查字符串开头是否匹配,若开头不匹配,就返回None;需用group()打印结果,
2.re.search(pattern, string, flags=0):扫描字符串,返回第一个完整匹配的字符串。
注意:只返回第一个匹配成功的内容,需用group()打印结果。
3.re.findall(pattern, string, flags=0): 扫描整个字符串,返回所有与pattern匹配的列表;
注意: 如果pattern中有分组则返回与分组匹配的列表。
二、正则表达式详解
每个正则表达式由普通字符和元字符组成。
普通字符:0123456789abcd@…
元字符:正则表达式所特有的符号 => [0-9],^,*,+,?
下面是字符规则:
(一)查什么:
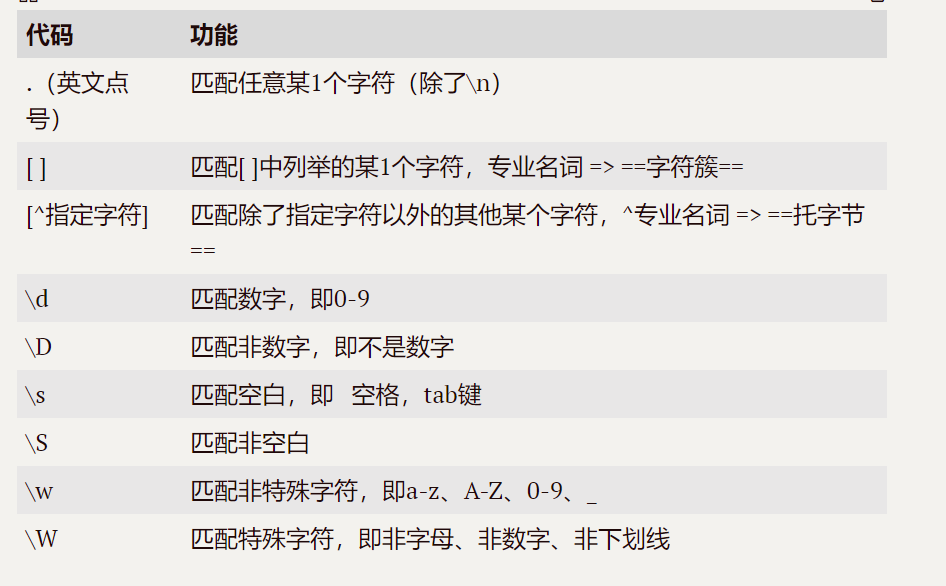
(二)查多少

(三)怎么查

注意:1.在正则表达式中,通过一对圆括号括起来的内容,我们就称之为==“子表达式”==(即:分组),findall若有分组,则只返回分组内容,返回内容并被叫做“捕获”,不同于匹配。
2. 在正则表达式中,我们可以通过\n(n代表第n个缓存区的编号)来引用缓存区中的内容,我们把这个过程就称之为"反向引用"(即:后向引用)。
三、代码实现
例:
import re #导入re模块
(1)match方法:
str1 = '<book></book>'
result = re.match(r'<(?P<mark>\w+)></(?P=mark)>', str1)
print(result.group()) #检查字符串开头是否匹配,打印匹配内容
(2)search方法:
str1 = '<book></book>'
result = re.search(r'<(?P<mark>\w+)></(?P=mark)>', str1)
print(result.group()) #扫描字符串,打印匹配到的第一个内容
(3)findall方法
result = re.findall('\d', 'a1b2c3d4f5')
if result:
print(result) #扫描整个字符串,直接打印所有匹配结果
else:
print('未匹配到任何数据')
最后,分享一个综合运用(因为findall方法比较方便好用,平时使用较多):
例:匹配出163、126、qq等邮箱
import re #导入模块
email = '1478670@qq.com, go@126.com, heima123@163.com'
result = re.findall('\w+@(qq|126|163).com', email)
if result:
for i in result:
print(i) #只打印分组内的内容:qq或126或163
else:
print('未匹配到任何数据')
备注:finditer()方法与findall()方法类似:都会返回所有匹配结果,只不过finditer是返回迭代器,findall返回列表。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









