







1、数挖的定义、产生原因,解决问题
数据挖掘就是寻找数据中隐含的知识并用于产生商业价值。
数据挖掘产生动因:海量数据、维度众多、问题复杂
解决问题:分类问题,聚类问题、回归问题、关联问题、
- 分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
- 聚类算法:K-Means,EM
- 关联分析:Apriori
- 连接分析:PageRank
2、数挖步骤:业务理解、数据理解、数据准备、构建模型、模型评估、模型部署
- 商业理解:我们的目的是更好地帮助业务,从业务出发,到业务中去
- 数据理解:收集数据后,对数据探索,包括数据描述、数据质量验证等。
- 数据准备:包括数据收集、数据清洗、数据补全、数据整合、数据转换、特征提取等一系列动作
- 模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
- 模型评估:对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的
商业目标。 - 模型部署:最终需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。
3、python三重点数据类型
- 列表(有序可重复的数组)list
- 集合(无序的不重复序列)set()
- 字典(每一个元素实际上是一个键值对(key:value),其中 key 是不能重复的,存入相同的key,它的 value 会被替换成最新的)dict={}
4、python 常用包
数挖常用6个模块:
math(数学模块)
datetime(日期时间模块)
random(随机模块)
re(正则匹配模块)
sys(系统接口模块)
第三方库:
numpy 、scipy、matploylib、pandas、scikit-learn
深度学习平台:tensorflow、pytorch
5、数挖:准备数据
数据清洗:
-
缺失值的处理
一般就 3 种情况:删掉有缺失值的数据;补充缺失值;不做处理 -
异常值的处理
异常值通常说的是那些与样本空间中绝大多数数据分布差距过大的数据
1.数据本身的错误,需要对数据进行修正,或者直接丢弃;
2.数据是正确的,需要根据你的业务需求进行处理。如果你的目标就是发现异常情况,那么这种异常值就需要保留下来,甚至需要特别关照。如果你的目标跟这些异常值没有关系,那么可以对这些异常值做一些修正,比如限定最大值和最小值的标准等,从而防止这些数据影响你后面模型的效果。 -
数据偏差处理
-
数据标准化
可以防止某个维度的数据因为数值的差异,而对结果产生较大的影响。 -
特征选择
特征选择就是尽可能留下较少的数据维度,而又可以不降低模型训练的效果。
维度越多,数据就会越稀疏,模型的可解释性就会变差、可信度降低
6、构建训练集与测试集
在训练之前,你要把数据分成训练集和测试集,有些还会有验证集。
- 如果是均衡的数据,即各个分类的数据量基本一致,可以直接随机抽取一定比例的数据作为训练样本,另外一部分作为测试样本。
- 如果是非均衡的数据,比如在风控型挖掘项目中,风险类数据一般远远少于普通型数据,这时候使用分层抽样以保障每种类型的数据都可以出现在训练集和测试集中。
训练集和测试集的构建也是有方法的:
- 留出法,就是直接把整个数据集划分为两个互斥的部分,使得训练集和测试集互不干扰,这个是最简单的方法,适合大多数场景;
- 交叉验证法,先把数据集划分成 n 个小的数据集,每次使用 n-1 个数据集作为训练集,剩下的作为测试集进行 n 次训练,这种方法主要是为了训练多个模型以降低单个模型的随机性;
- 自助法,通过重复抽样构建数据集,通常在小数据集的情况下非常适用。
7、构建模型时如何选择模型
针对每一类型的问题,就可以找到对应的算法,再根据算法的特性去进行选择
已经有一批已经有标签结果的数据—分类
缺少这些已知的信息—聚类算法
要么考虑处理数据----人工进行标注。
7.1 分类问题
分类种类:二分类、多分类、多标签分类(对于二分类和多分类,一条内容最后的结果只有一个,标签之间是互斥的关系。但是多标签分类下的一条数据可以被标注上多个标签。比如一个人既可以写玩法,也可以写美食,这两者并不冲突。)
分类算法: KNN 算法、决策树算法、随机森林、SVM 等
7.2聚类问题
跟分类不同,聚类是无监督的
聚类就是把一个数据集划分成多个组的过程,使得组内的数据尽量高度集中,而和其他组的数据之间尽量远离。

7.3 回归问题
分类方法输出的是离散的标签,回归方法输出的结果是连续值。、
回归方法和分类方法可以相互转化:
- 回归-》分类。划分标签即可
在使用回归方法得到函数方程式以后,你可以根据对新数据运算的结果进行区间分段,高于某个阈值给定一个标签,低于该阈值给定另外一个标签。比如你使用回归方法预测完房价之后,不想让客户看到真实的房价,而是给予一个范围的感受,就可以设定高于 500w 的就是 “高房价” 标签,低于 100w 的就是 “低房价” 标签; - 分类-》回归。加一些逻辑运算
对于通过分类方法得到的标签,你可以根据给定标签的概率值为其增加一些运算逻辑,将标签转换到一个连续值的结果上。

7.4 关联问题
无监督学习。
与分类和回归不同,关联分析是要在已有的数据中寻找出数据的相关关系,以期望能够使用这些规则去提升效率和业绩
啤酒与尿布的故事
7.5 模型集成
作集成学习,其思路就是去合并多个模型来提升整体的效果。
集成的三种方式:
- Bagging(装袋法)–随机森林
比如多次随机抽样构建训练集,每构建一次,就训练一个模型,最后对多个模型的结果附加一层决策,使用平均结果作为最终结果。
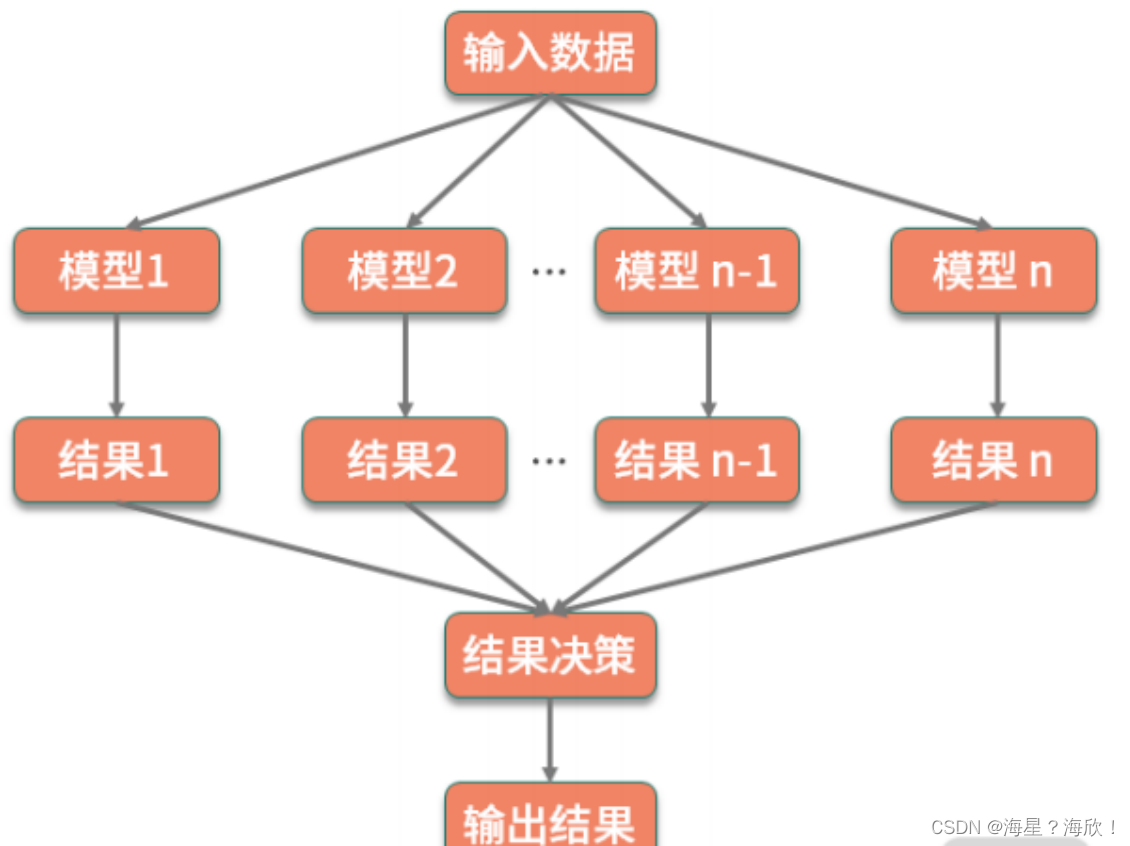
- Boosting(增强法)
串行的训练,即每次把上一次训练的结果也作为一个特征,不断地强化学习的效果
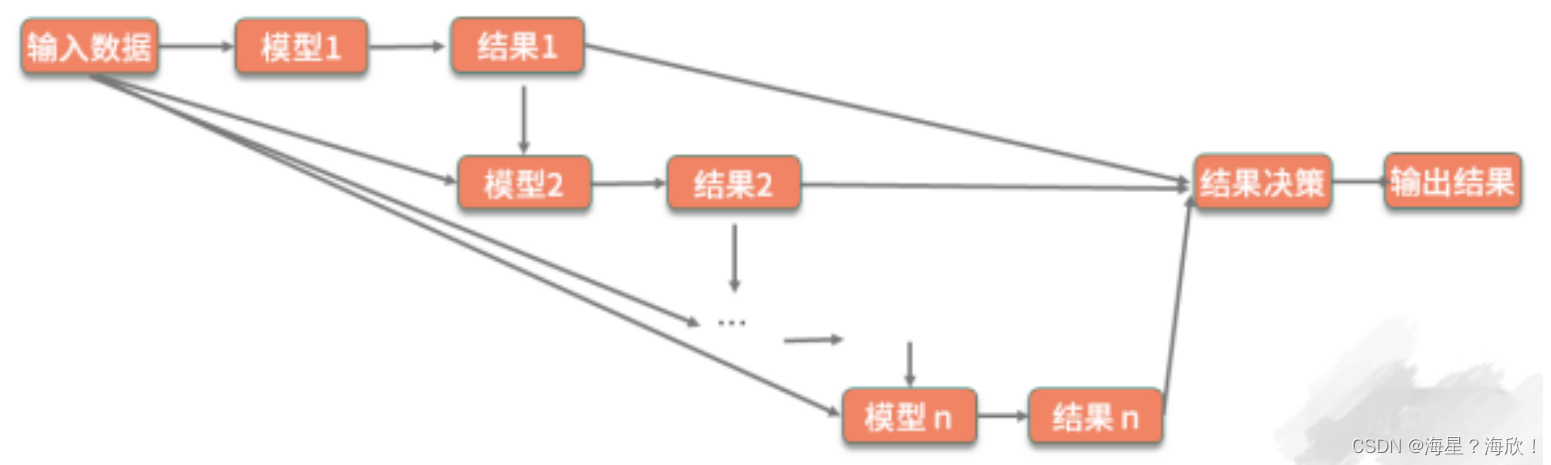
- Stacking(堆叠法)
这个方法比较宽泛,它对前面两种方法进行了扩展,训练的多个模型既可以进行横向扩展,也可以进行串行增强,最终再使用分类或者回归的方法把前面模型的结果进行整合。
在使用堆叠法时,就需要你在具体业务场景中不断地去进行尝试和优化,以达到最佳效果。
8、模型评估
评估指标:混淆矩阵、准确率指标、ROC曲线
8.1 混淆矩阵:
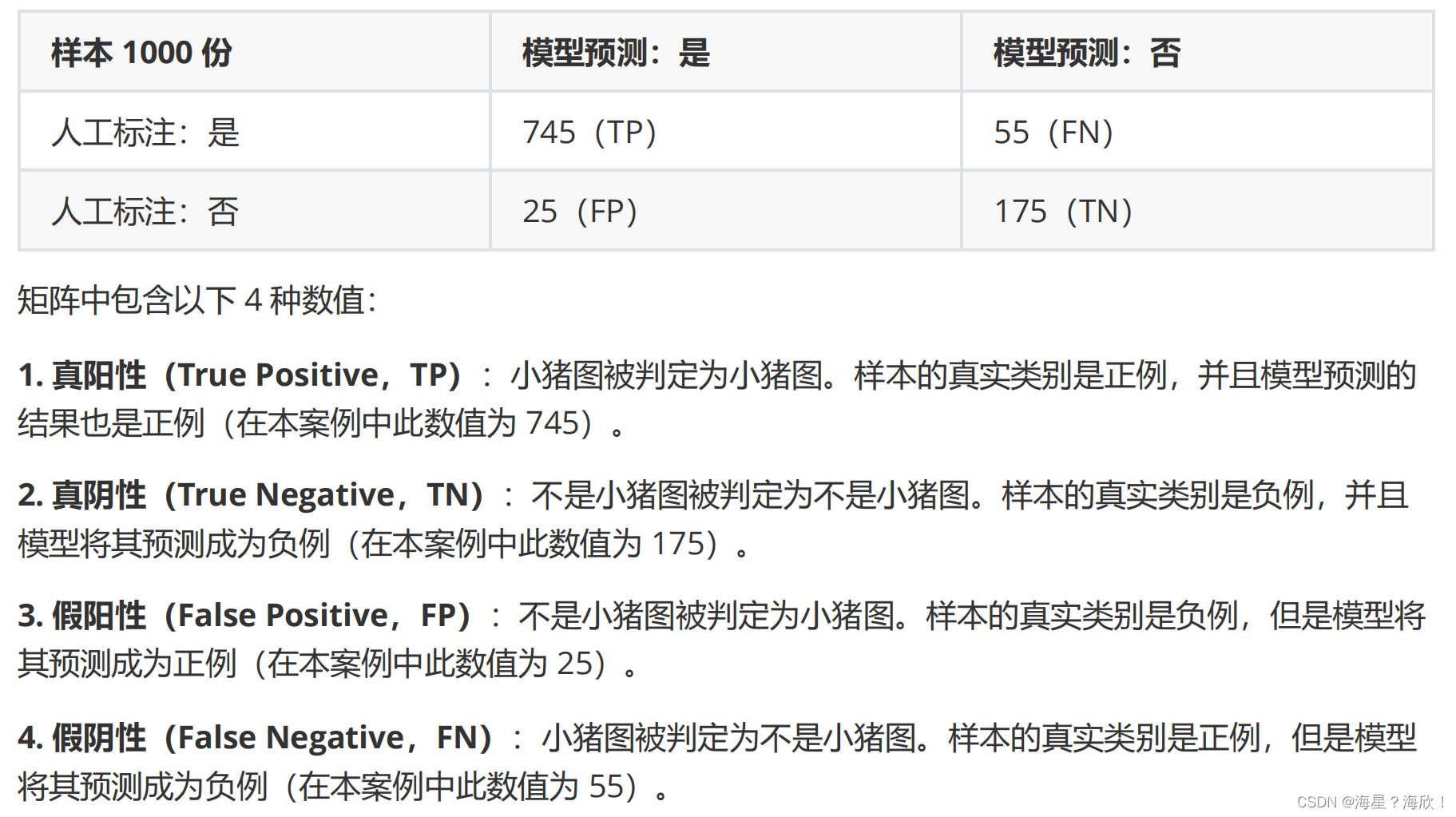
根据上述混淆矩阵,我们可以计算一些数值。


ROC曲线:
在每一组混淆矩阵中,我们获取两个值:真正例率和假正例率。
真正例率:TP/(TP+FN)
假正例率:FP/(FP+TN)
使用这两个值在坐标系上画出一系列的点,纵坐标是真正例率,横坐标是假正例率,把这些点连起来形成的曲线就是 ROC 曲线(Receiver Operating Characteristic,接收者操作特征)。ROC 曲线下方的面积是 AUC 值(Area Under Curve,曲线下面积),ROC 曲线和 AUC 值可以反映一个模型的稳定性,当 ROC 曲线接近对角线时,说明模型输出很不稳定,模型就越不准确。
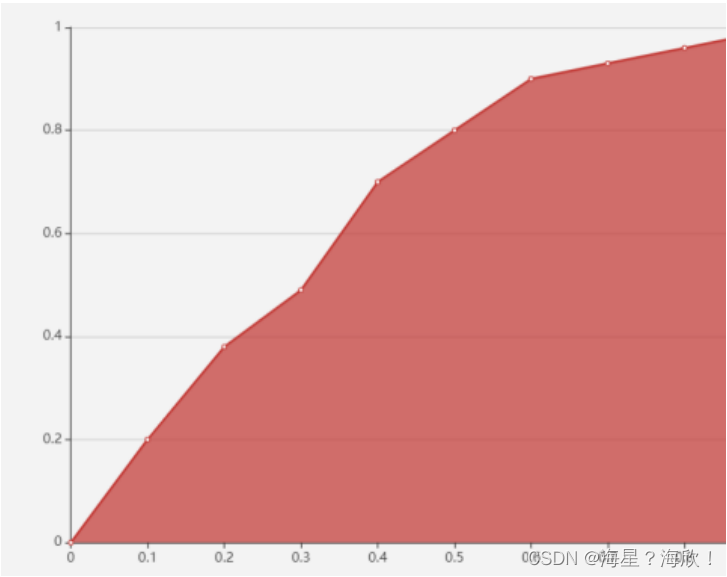
8.2 泛化能力评估:
过拟合:模型在训练集上表现良好,而在测试集或者验证集上表现不佳
欠拟合:在训练集和测试集上的表现都不好。
8.3 其他评估指标
- 模型速度:主要评估模型在处理数据上的开销和时间。
- 鲁棒性:主要考虑在出现错误数据或者异常数据甚至是数据缺失时,模型是否可以给出正确的结果,甚至是否可以给出结果,会不会导致模型运算的崩溃。
- 可解释性:随着机器学习算法越来越复杂,尤其是在深度学习中,模型的可解释性越来越成为一个问题。由于在很多场景下(比如金融风控),需要给出一个让人信服的理由,所以可解释性也是算法研究的一大重点。
9、评估数据的处理
- 随机抽样:即最简单的一次性处理,把数据分成训练集与测试集,使用测试集对模型进行测试,得到各种准确率指标。
- 随机多次抽样:在随机抽样的基础上,进行 n 次随机抽样,这样可以得到 n 组测试集,使用 n 组测试集分别对模型进行测试,那么可以得到 n 组准确率指标,使用这 n 组的平均值作为最终结果。
- 交叉验证:交叉验证与随机抽样的区别是,交叉验证需要训练多个模型。譬如,k 折交叉验证,即把原始数据分为 k 份,每次选取其中的一份作为测试集,其他的作为训练集训练一个模型,这样会得到 k 个模型,计算这 k 个模型结果作为整体获得的准确率。
- 自助法:自助法也借助了随机抽样和交叉验证的思想,先随机有放回地抽取样本,构建一个训练集,对比原始样本集和该训练集,把训练集中未出现的内容整理成为测试集。重复这个过程 k次、构建出 k 组数据、训练 k 个模型,计算这 k 个模型结果作为整体获得的准确率,该方法比较适用于样本较少的情况。














 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









