









3.1.1表的简单数组实现
对表的所有操作都可以通过数组来实现。 虽然数组是动态指定的, 但是还是需要对表的大小进行估值。 通常需要估计的大一些, 从而会造成空间的浪费。 这是严重的局限, 特别是在存在许多未知大小的表的情况下。
数组实现的printlist和find正如所预期的那样, 以线性的时间来执行, 而findth这花费数倍的时间。然而插入和删除的操作花费的时间是高昂的。 例如在位置O插入首先需要将这个数组整体向后平移一位, 然后将空出来的空间填入新的数字,同时删除一个数据也需要将后面的所有数据向前平移一位, 在极端情况下, 这样的操作将花费o(n)的时间来进行。
因为插入和删除的的运行时间如此之慢, 以及表的大小还必须实现知道, 所以简单数组一般不用来实现这样的一种结构。
·
·
·
3.1.2链表
为了避免插入和删除的线性开销, 我们需要允许表的不连续存储, 否则表的整体或者部分需要进行整体的移动。
链表是由一系列不必再内存中连续的结构组成, 每个结构含有表元素和指向该表元素的后继元的结构的指针。 我们将其称之为Next指针。 最后一个单元的Next指针指向NULL; 该值由编程语言定义, 并且不能与其他指针混淆。 ANSI C 中规定NULL的值为零。
我们回忆一下, 指针变量就是包含储存另外某个数据的地址的变量。因此, 如果P被声明为一个结构的指针, 那么存储在P中的值就被解释为一个主存中的位置, 在该位置中, 能找到一个结构。 该结构的一个域可以通过P->FieldName访问, 其中FieldName是我们要考察的域的名字。
为了执行PrintList(l)或者Find(L, Key), 我们只要将一个指针传递到该表的第一个元素, 然后用一些Next指针穿过该表极客。 这种操作显然是线性时间, 虽然这个常数可能比可能比数组实现时要大。Findth操作不如数组的实现效率高; FindKth(L, i)花费O(i)时间以显示方式穿越链表尾完成。 在实践中这个界时保守的, 因为调用FindKth常常是以(按i排序的方式进行)。 例如, FindKth(L, 2), FindKth(L, 3), 等等可以通过一次扫描同时实现。
删除命令可以通过修改一个指针来实现。 下图给出在原表中删除第三个元素的结果

插入命令需要使用一次malloc调用从系统中得到一个新的单元, 并在后面两次调整指针的指向。 其一般的方法在下图给出, 其中虚线的部分表示断开的原指针。
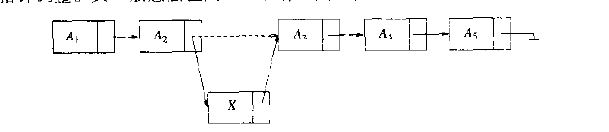
·
·
·
3.1.3 具体程序设计细节
上面的描述实际上足矣使得每一部分都正常的工作, 但是还有几处地方会出现问题。 首先, 并不存在从所给定义出发在表的前面插入元素的真正显性做法。第二, 从表的前面实行删除时提个特殊的情况, 因为他改变了表的起始端了变成中的疏忽将会造成表的丢失。第三个问题涉及一般的删除。虽然指针的移动很简单, 但是删除算法要求我们记住被删除的算数的前元。
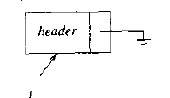
事实上我们使用一个简单的变化就能解决这所有的三个问题。 我们将留出一个标志节点, 有时我们将其称之为表头或者叫哑节点.这是通常的一种习惯, 在后面我们会多次看到它。我们约定表头在位置0处。
为了避免删除操作相关的一些问题, 我们需要编写例程FindPrevious, 他们将返回我们要删除的表元的前驱元的位置。 如果我们使用表头, 那么我们删除表头的元素的时候, FindPrivous将返回表头的位置。头节点的是有多少是存在争议的。 一些人认为添加假象的单元只是为了避免特殊的情形, 这样的理由不够充分。 他们把头节点的使用看成是老式的随意删除修改没有太大的区别。 不过即使这样, 我们还是在这里使用它, 这完全是因为它是我们能够表达基本的指针操作且有不至于使得特殊情形的代码含混不清。除此之外, 要不要使用表头这是完全个人兴趣的问题。
作为例子, 我们将把这些表ADT的半数的例程写出来。 首先, 在下图中给出需要的声明。 按照C的约定, 作为类型的List表和Position以及函数原型都在所谓的.c未见之中。 具体的Node节点的生命在.c文件之中。
·······································

我们的第一个示例函数是用来测试空表的。 但我们编写涉及指针的任意数据结构的代码时, 最好先画出一张图来。 图3 - 7就是一个最为简单的表, 按照这个图就容易写出下文的函数出来。
int isempty(List L)
{
return L->Next == NULL;
}下面我们要讲解的是Find例程。 Find它返回每个元素在表中的值的位置,。其中在主程序的第二行, 用到了&&操作走了捷径, 即如果与运算(&&)的1前半部分为假, 那么结果就为假, 而后半部分着不再执行。
也许有人发现, 递归的编写Find例程更有吸引力, 大概是这样可以避免冗长的终止条件, 但是后面我们将会看到这是一个非常糟糕的想法, 我们将要不惜一切的避免他。
Position Find(ElementType X, List L)
{
Position P;
P = List->next;
while (P != NULL && P->Element != x)
p = p->next;
return p;
}第四个例程是删除表L中的某个元素X, 我们需要确定:如果X出现不止一次, 或者根本就没有, 我们做什么? 我们的例程将删除第一次出现的X, 如果X不再表中, 我们就什么也不做。 为此我们通过调用调用FindPrevious函数找出含有X的前驱元P。 实现删除的例程在图3 - 11给出。 FindPrevious例程类似于Find在下文中给出。
void Delete(ElementType X, List L)
{
Position P, TmpCeell;
P = FindPrevious(X, L);
if (!Islast(P, L))
{
TmpCeell = p->Next;
P->Next = TmpCeell->next;
free(Tmpcell);
}
}
Position FindPrevious(ElementType X, List L)
{
Position P;
P = L;
while (P->Next != NULL && P->Next->Element != x)
P = P - > Next;
return P;
}我们最后写的一个例程是插入例程。 将要插入的元素与表L和位置P一起传入。 这个insert例程将一个元素插入到由P只是的位置之后。 我们这个决定由随意性, 它意味着插入操作如何实现并没有明确的规则。 很可能将新元素插入到位置P处, 但是这么做则需要知道位置P前面的元素。 他们可以通过调用FindPrevious确定。如下的程序完成这项任务:
void Insert(ElementType x, List L, Position P)
{
Position TmpCell;
TmpCell = malloc(sizeof(node));
if (TmpCell == NULL)
return;
TmpCell->Element = x;
TmpCell->Next = P->Next;
P->Next = TmpCell;
}除了find和findPrivious进程外, 我们已经编码的所有操作均需0(1)时间。 因为这大都数情况下, 这些操作均只执行固定的指令。 对于例程Find 和FindPrevious, 在最坏的情况下, 运行的时间复杂度是O(N),因为如果查询的结果在表的末尾, 那么这个例程将遍历全部的表。 平均来看运行时间是O(N), 因为平均必须扫描办个表















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









