






目录
前言
ProcessDB实时/时序数据库不仅具有卓越的性能,还可以和算法模型,机器学习等有良好的相融性,下面将以监测管道泄露的业务场景,阐述如何使两者联动
一、业务场景介绍
在复杂的工业场景下,管道的状况无法人工进行实时排查,单一的监控设备等也无法完整的对管道状况进行判断,所以我们使用ProcessDB实时/时序数据库训练出适配的算法模型,并实时对管道泄露状况进行判断
二、根据实时库点位获取训练数据
使用ProcessGateway数采网关采集到管道的参数数据,例如:温度,压差,开度等,并上传至ProcessDB数据库,如下图所示:

三、通过算法生成泄露模型
这里选用AdaBoost分类模型的AdaBoostClassifier算法,从ProcessDB数据库获取管道参数数据,来进行模型训练
from sklearn.metrics import accuracy_score
from sklearn.ensemble import AdaBoostClassifier
import joblib
from sklearn.model_selection import train_test_split
import numpy as np
import ProcessDBDriver as processdbDriver
from sys import argv
# 管道参数点位
pointNameList = [
'D1.PIPELINE.PRESSURE', 'D1.PIPELINE.TEMPERATURE',
'D1.PIPELINE.OPEN', 'D1.PIPELINE.FLOW',
'D1.PIPELINE.TRAIN'
]
# 连接ProcessDB实时数据库
connectName = '127.0.0.1'
port = 8301
processdbDriver.connect(connectName, port)
# 登录
userName = 'root'
password = 'root'
wErrCode = processdbDriver.login(userName, password)
# 登录成功
if wErrCode != 0:
print('login failed. errorCode: ', wErrCode)
else:
start_time = '2023-05-15 20:00:00'
end_time = '2023-05-15 20:59:59'
filterLow = 0
filterHigh = 0
fillValue = 0
fillValueType = 1
step = 1
dnd2 = np.zeros((3600, len(pointNameList)-1))
dnd1 = np.empty(3600)
# 点名查询历史时序数据
for m in range(len(pointNameList)):
count, errCode, resultSet = processdbDriver.query_sample_his_data_by_pointName(
start_time, end_time, pointNameList[m], step, 0, 0, filterLow, filterHigh, fillValue, 0, 0, 0, 0, fillValueType)
if errCode == 0:
if count != 0 and count != 'null':
for i in range(count):
historyData = processdbDriver.get_sample_his_data(
i, resultSet)
if m == len(pointNameList)-1:
# 最后一个点位作为训练的参考结果
dnd1[i] = str(historyData.nValue)
else:
dnd2[i, m] = historyData.nValue
else:
print('pointName:', pointNameList[m],
',', 'no sampling history data.')
else:
print('query_sample_his_data_by_pointName failed, errorCode: ', errCode)
# 数据库登出
outCode = processdbDriver.logout()
# 数据赋值
x = dnd2
y = dnd1
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=123)
# 模型训练
clf = AdaBoostClassifier(random_state=123)
clf.fit(x_train, y_train)
# 模型下载
joblib.dump(clf, 'train.model')
四、创建报警点位,接收模型评估结果
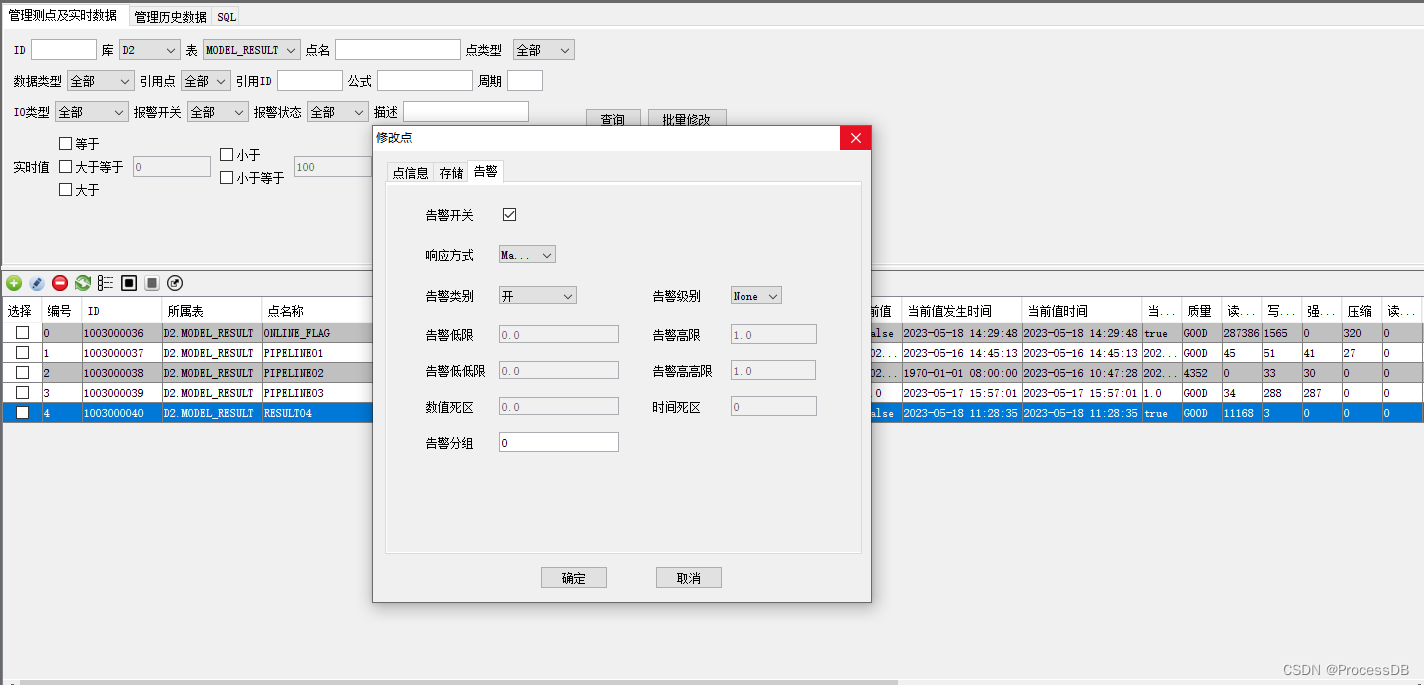
五、读取泄露模型,对当前管道泄露状态进行评估
from sklearn.metrics import accuracy_score
from sklearn.ensemble import AdaBoostClassifier
import joblib
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import ProcessDBDriver as processdbDriver
from sys import argv
waclf = joblib.load('train.model')
# 查询模型预测的所需数据
pointNameList = [
'D1.PIPELINE.PRESSURE', 'D1.PIPELINE.TEMPERATURE',
'D1.PIPELINE.OPEN', 'D1.PIPELINE.FLOW'
]
# 连接实时数据库
connectName = '127.0.0.1'
port = 8301
processdbDriver.connect(connectName, port)
# 登录
userName = 'root'
password = 'root'
wErrCode = processdbDriver.login(userName, password)
# 登录成功
if wErrCode != 0:
print('login failed. errorCode: ', wErrCode)
else:
dnd2 = []
dnd1 = []
# 点名查询实时数据
for i in range(len(pointNameList)):
count, errCode, resultSet = processdbDriver.query_realTime_data_by_pointName(
pointNameList[i])
if errCode == 0:
if count != 0 and count != 'null':
dnd1.append(str(resultSet.getValue()))
else:
print('pointName:', pointNameList[i], ',', 'No Realtime data')
else:
print('query_realTime_data_by_pointName failed.errorCode: ', errCode)
dnd2.append(dnd1)
# 数据库登出
outCode = processdbDriver.logout()
# 模型预测与评估
y_pre = waclf.predict(dnd2)
# 模型评估
a = pd.DataFrame()
a['预测值'] = list(y_pre)
quality = 0x1100
for i, row in a.itertuples():
# 把结果返回给实时数据库
errCode = processdbDriver.insert_real_time_data_by_name(
'D1.PIPELINE.PREDICT', quality, row)
if errCode == 0:
print('insert_realtime_data succeed!')
else:
print('insert_realtime_data failed, errorCode:', errCode)
五、在ProcessDB数据库中,查看管道泄露报警
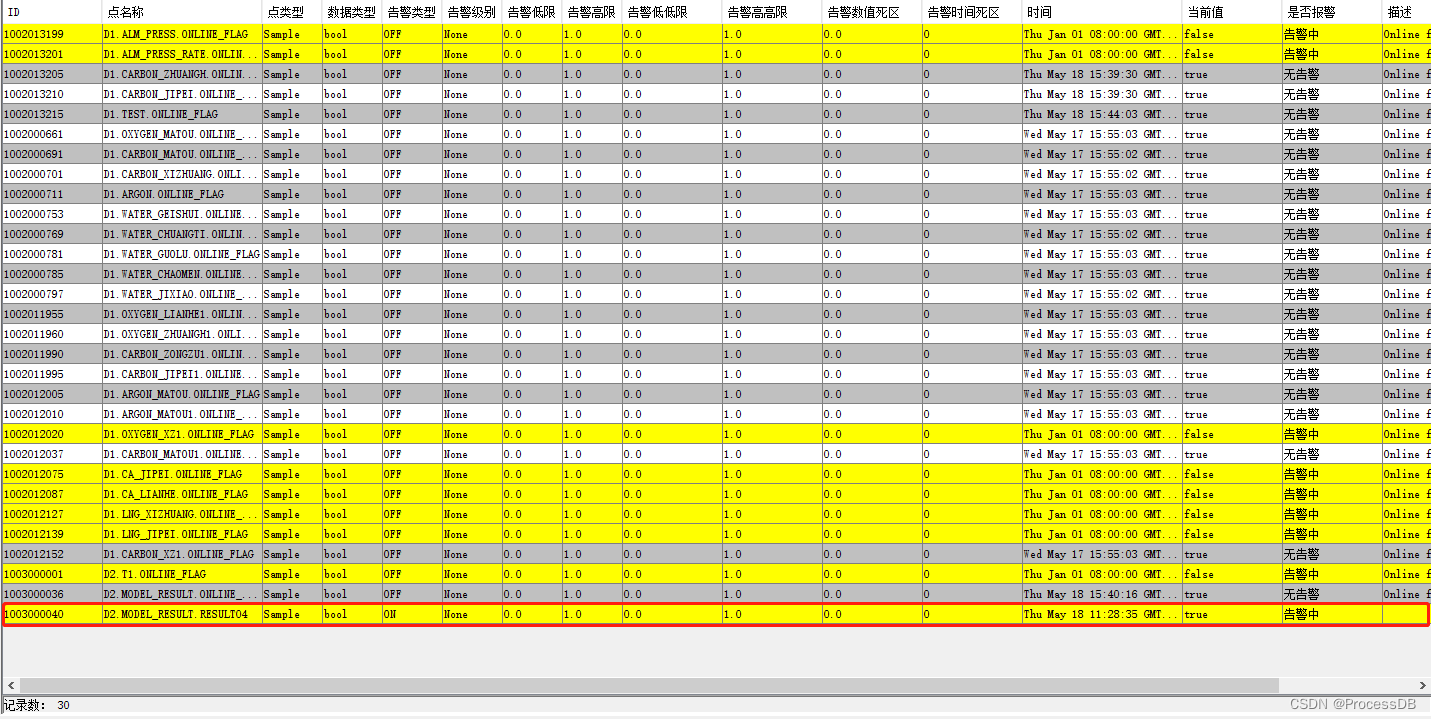
















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









