







目录
HashMap的存储结构可以概括为Node节点数组+链表。
添加与获取元素都是先通过元素的hash值找到其对应的index,其中的hash算法采用的是高低16位特征混合策略。
HashMap的扩容是将数组扩大到2倍,然后逐个元素计算新的index(取决于原数组大小+1位元素key的hash值是0或1),逐个迁移到新的位置。
ConcurrentHashMap实现并发安全是使用volatile关键字+CAS来保证。
在put时先锁住目标index的头结点,然后通过CAS来操作。
值得一提的是ConcurrentHashMap的扩容也支持并发,当put操作发现当前table正在扩容时,此线程将加入其中,协助并发扩容。
整个扩容分为了两个步骤:
单线程创建容量2倍的新数组;
多线程将原数组迁移到新数组中。
第2步是可以并发进行的,通过volatile修饰的transferIndex+每个线程需要负责多少桶(步长stride)实现并行迁移。
JUC-Collection

JUC中为我们提供的并发集合,大致可以分为:
- Map
- Queue队列
- Set集合
- List列表
HashMap【线程不安全Map】
在看ConcurrentHashMap实现原理之前,先了解一下HashMap。
HashMap的底层结构为:
- 数组
- 链表
它与HashTable之间的区别在于:
HashMap是线程不安全的
而HashTable内部的方法都是经过synchronize关键字修饰,是线程安全的。
也正是因为其使用了synchronize对put等操作,都对整个表进行加锁,所以效率也会相对慢。
1. HashMap存储结构、构造函数
存储结构
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
HashMap的内部存储结构是一个Node类型的数组,它实现了Map.Entry接口,保存了K/V键值对。
构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
HashMap中有几个变量:
int length(capacity);//数组table初始化的长度,其长度一定是2的倍数,默认值:16
int threshold;//Map中最大能容纳Node的数量(threshold = length * loadFactor)
final float loadFactor;//负载因子,默认值:0.75
transient int size;//Map中当前实际含有的Node数量
2. 【HashMap功能实现】——GET
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
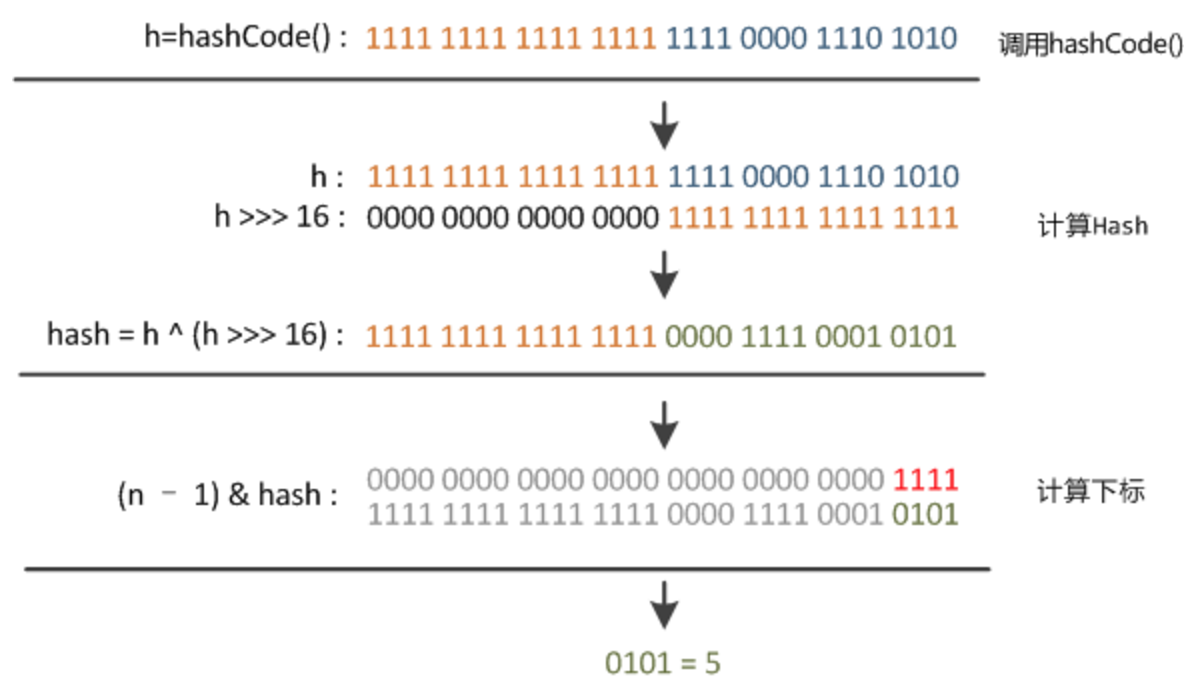
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Hash概念
首先来了解一个概念:Hash。
哈希就是把不固定的输入,通过散列算法,输出固定长度的散列值。同一个算法的散列值不同,那么输入值一定不相同;但是不同的输入值经过同一个算法,其输出值可能相同,这种现象叫碰撞。
1. 通过Hash算法找到数组的目标index
first = tab[(n - 1) & hash]
其中的hash:
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
可以概括为3步:
- 获取key的hash值
h = key.hashcode() - 高位运算
hash = (h = key.hashCode()) ^ (h >>> 16)
第2步的运算是为了对key的hash算法进行打散,可以说把 高位的特征和低位的特征结合起来 ,降低冲突的概率。
Q:为什么是hash值右移16位呢?
- A:因为h为一个int类型,已知int长度为32,所以右移16位(高位的16位补0),可以正好凑齐低16位与高16位,再做^运算,相当于将高16位与低16位的特征结合。
- 取模,得到余数
[(n - 1) & hash]
第3步,将上述获取的h,与HashMap中的槽大小做余数,得出当前的index,与%运算等价。
Q:为什么不直接使用%,而是使用&位运算?
- A:为了效率更高
Q:为什么是与(n-1)做&运算?
- A:因为n是2的指数,所以n-1的二进制都是1。比如HashMap的初始值为16个槽位,n-1的二进制就是1111,四位数,那么与算出的hash值&运算的意义,就正好是hash的最后4位本身,更加随机。
整个算法如图:(原图地址)

2. 通过index获取冲突链表(或者只有一个Node)
Node<K,V> first = tab[(n - 1) & hash])
3. 判断冲突链表的第1个key是否符合条件
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
找到数组中index的key,接下来是判断key是否满足条件:
- 判断key的hash值
- 通过key的equals()方法判断,或者是指向同一个内存地址
注意两个条件需要同时满足!即 hashcode和equals方法都要相等 。
4. 遍历冲突链表通过equals判断
如果数组中index的第1个key不是目标,说明此hash值有冲突,遍历此index位置的其他Node,直到找到目标key。
这里有两种情况:以链表结构存储Node、以红黑树结构存储Node。
3. 【HashMap功能实现】——PUT
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
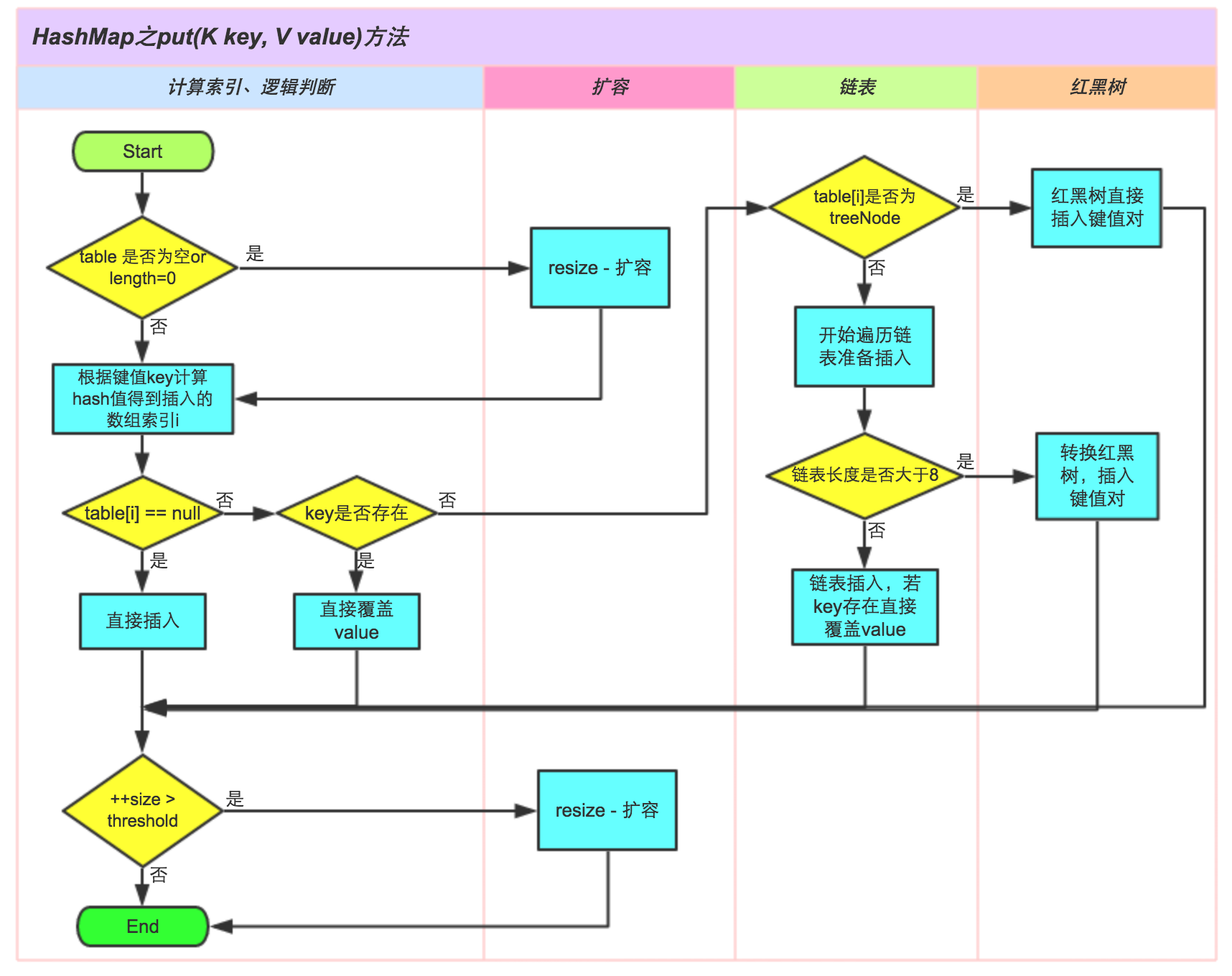
1. 判断当前数组是否为空,或长度为0
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
如果当前数组为空,那么先扩容。
2. 计算key对应的index,如果index位置为空
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
直接new一个新的Node节点,放在算出的index的位置。
其中index的计算:index:[i = (n - 1) & hash],与get操作中的计算是对应的。
3. 计算出index位置有冲突
- 如果tab[index]与key的 equals方法相同,则直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
-
equals不相同,则需要解决冲突
2-1. 红黑树类型:
直接插入KV
2-2. 如链表类型:
遍历链表,如果发现链表中某个key的equals方法符合,则覆盖;
遍历链表到最后,插入目标KV;判断如果链表长度>8,则转换为红黑树;
4. 计算size是否需要扩容
if (++size > threshold)
resize();
将HashMap的size+1,即实际保存Node的个数+1,判断是否超过了threshold,进行 扩容。
整个过程如图:(原图地址)

4. 【HashMap功能实现】——RESIZE
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
这里的源码是JDK1.8版本的。
1. 计算新表的长度newCap、容量newThr
- 如果原table的长度已经超过MAXIMUM_CAPACITY最大容量
threshold = Integer.MAX_VALUE;
return oldTab;
直接将可容纳Node的最大数量设为int的最大值,且直接返回原表 ,不再扩大表的length。
- 原table的长度大于16,小于MAXIMUM_CAPACITY
newCap = oldCap << 1
newThr = oldThr << 1;
将新表的长度、最大容纳Node数量都*2
- 原table为空或者长度为0,先将length和threshold都设为默认值。
2. 初始化新表newTab
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
3. 将旧表的Node转移到新表
- 遍历oldTab,获取当前index的Node:oldTable[index],保存到Node e对象
- 将oldTable[index]的值设为null
- 如果当前index只有一个Node,那么直接将e对象赋值给newTable
newTab[e.hash & (newCap - 1)] = e;
newTable中新index的计算:
e.hash & (newCap - 1)
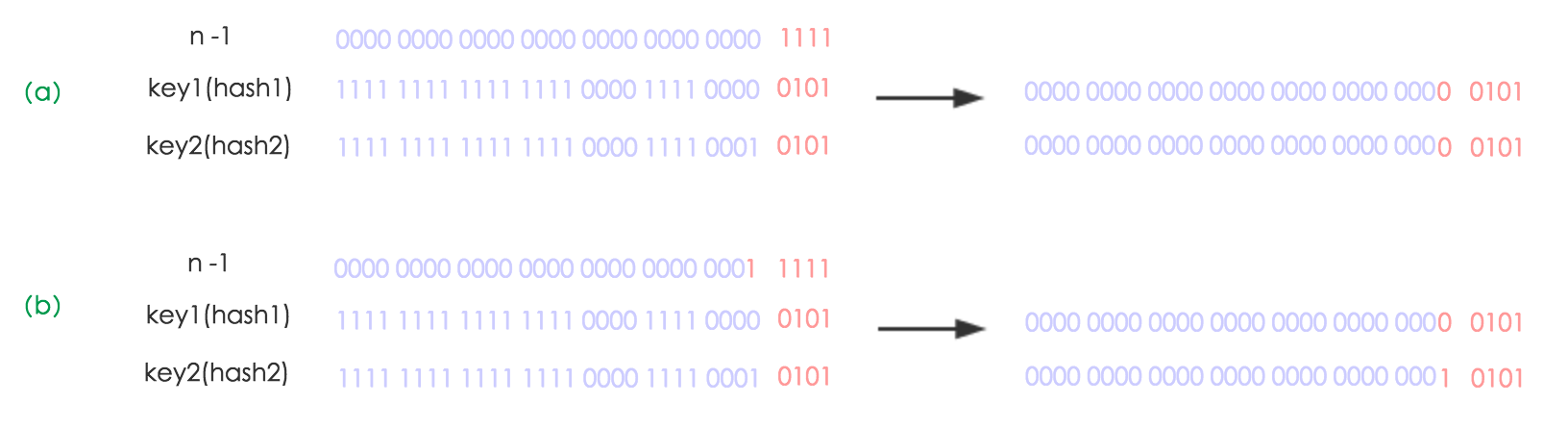
因为表的长度被扩大为了原来的2倍,所以Node要么放在index原位置,要么放在(index+length)的新位置。
假如:oldCap为16,那么newCap为32
-
对于一个key,在原表中是hash(key)的低4位,与1111做运算:都被分配到了0101的index上。
-
扩容之后的index计算,是hash(key)的低5位,与11111做运算,也可以说是取决于hash(key)中低第5位是0或者1,而这个概率是对半的。所以可均匀地分配到原index、原index+length的位置。
-
计算流程如图(原图链接)

- 当前index中有冲突,如果是红黑树的结构,
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
- 当前index中有冲突,如果是链表的结构
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
这段代码的意义是:遍历冲突链表,通过判断(e.hash & oldCap) == 0来确定,将node放在新表的index位置,或者是(index+oldCap)位置。
(e.hash & oldCap) == 0
这个算法与上述「newTable中新index的计算」是类似的。
只不过它算出来的结果不是一个具体的index,而是0或者1(如上述例子中hash(key)的低第5位数字是0还是1)代表是否要移动到新位置上去。
- 之后就是将Node一个个地按照hash放到新的链表上,与jdk1.7不同,Node的顺序不会颠倒。
5. HashMap的线程不安全问题
触发线程安全问题的场景有:
- 多线程的put操作可能导致元素的丢失
问题在于put方法中的:
if ((e = p.next) == null) // #1
p.next = newNode(hash, key, value, null); // #2
当线程a和线程b同时通过#1的判断
线程a先执行了#2的代码,new了一个新的nodeA,将p.next指向nodeA;
此时线程b再执行#2代码,new一个新的nodeB,将p.next指向nodeB;
那么nodeA将会丢失。
- put和get并发执行时,get可能为null
ConcurrentHashMap【线程安全Map】
JDK-1.8
1.存储结构、构造函数
存储结构
- Node:存放在tab[index]的位置,当存在hash冲突时,Node节点以链表的形式连接起来;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
- TreeBin:(hash=-2)是个代理节点,代理红黑树的TreeNode节点,存放在table[index]的位置;
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
}
- ForwardingNode:(hash=-1)在 扩容 操作时产生的临时占位节点,其hash值为-1,且不存储具体数据;
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
- ReservationNode
static final class ReservationNode<K,V> extends Node<K,V> {
ReservationNode() {
super(RESERVED, null, null, null);
}
}
构造函数
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
/**
* Returns a power of two table size for the given desired capacity.
* See Hackers Delight, sec 3.2
*/
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- 入参:initialCapcity
- 返回值:与initialCapcity最近的2的此方,如输入15,返回16.
与HashMap是类似的。这里并不会对table进行初始化,而只是确定一个size,初始化操作会在第一次的put时进行,属于“懒加载”。
ConcurrentHashMap中有几个变量:
private transient volatile int sizeCtl;//当前数组正在初始化时为-1;初始化结束后,表示threshold,即 数组大小*负载因子
private transient volatile int transferIndex;//扩容时的一个下标
2. 【ConcurrentHashMap功能实现】——GET
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
1. 计算key的hash值,通过Unsafe类getObjectVolatile获取table[index]的Node
int h = spread(key.hashCode());
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
Q:为什么是通过getObjectVolatile,而不是直接table[index]?
- A:因为虽然table是通过volatile关键字修饰的,但是一个volatile类型的数组并不能保证数组内的每一个元素都有可见性的特性,而getObjectVolatile保证了每一个元素都是最新值。
2. 如果tab[index]的key与参数key相同,则返回tab[index].val
3. 如果tab[index]的hash<0,当前Node正在扩容迁移中,到nextTable中查找
return (p = e.find(h, key)) != null ? p.val : null;
ForwardingNode的find方法:
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
代码中nextTable表示扩容中迁移到的新表;
通过loop循环查找,返回null、或者是目标Node。
4. 如果tab[index]的Node有链表的结构,则遍历查找
3. 【ConcurrentHashMap功能实现】——PUT
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
1. 如果当前table为空,先进行初始化
tab = initTable();
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
- 判断sizeCtl<0,即当前table是否正在初始化,如果是,则当前线程等待;
- 通过CAS将sc设为-1,表示table正在初始化
- 初始化table后,赋值sizeCtl:n - (n >>> 2),即n*0.75
2. 计算key的hash值,通过Unsafe类getObjectVolatile获取table[index]的Node
int hash = spread(key.hashCode());
f = tabAt(tab, i = (n - 1) & hash)
3. 如果table[index]为空,通过Unsafe类compareAndSwapObject给table[index]赋值
casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
4. 如果table[index]的hash=-1表示正在扩容,协助数据迁移
tab = helpTransfer(tab, f);
/**
* Helps transfer if a resize is in progress.
*/
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
这里调用了transfer(tab, nextTab)方法,这个方法在下文的扩容实现中有详细分析。
5. 如果table[index]中已有节点,表示hash有冲突,锁住当前Node
-
如果fh = f.hash >= 0,表示不是TreeBin节点,是普通Node节点:
新建Node插入到链表的尾部
-
如果fh = f.hash < 0,表示table[index]是TreeBin节点(hash=-2):
将新节点以红黑树的形式插入
-
如果是链表结构,判断长度是否>8,需要将链表转换为红黑树结构
6. 判断元素个数是否超限,需要扩容
addCount(1L, binCount);
4. 【ConcurrentHashMap功能实现】——扩容
扩容时机1. PUT后某个index链表长度>8
当PUT操作执行,需要对链表到红黑树进行转换,即treeifyBin操作:
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
可以看到,当table的length<64时,并不会直接对红黑树进行转换,而是先进行扩容。
即当table中某个index位置的冲突较为严重时,如果此时table的length非常短,则不会将此index的Node转为红黑树结构,而是先扩大table的长度为2倍。
扩容时机2. PUT后计算元素个数,超出阈值后扩容
当调用transfer方法进行扩容时,传入参数:
- Node<K,V>[] tab:原table
- Node<K,V>[] nextTab:扩容后的新table。这个参数可以为nextTable,表示已经有别的线程发起了扩容,当前线程只是协助数组的迁移;也可以为null,表示当前线程发起了扩容,nextTable还没创建
总结来说,ConcurrentHashMap的扩容可以分为两个部分:
- 创建一个长度*2的新数组(单线程)
- 将原数组的元素迁移到新数组中(可以并行进行)
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
1.计算stride步长
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
stride表示了每一个线程需要负责迁移原table中的多少个桶
2.如果nextTable为空,先初始化
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
这里的新table大小:n<<1,即扩容2倍
3.确定本轮需处理的index范围[transferIndex-1,transferIndex-stride]
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
其中:
- advance:表示是否可以进行下一个桶的迁移
- i:开始桶的位置:transferIndex-1
- bound:结束桶的位置:transferIndex-stride
4.【case1】table[i]为空,直接ForwardingNode占位
if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
5.【case2】table[i].hash=-1,已被迁移,跳过本index
if ((fh = f.hash) == MOVED)
advance = true; // already processed
6.【case3】table[i]需要被迁移,分为链表和红黑树两种
7.【case4】最后一轮任务,迁移结束
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
- 将table换为扩容后的新数组
- 重新计算sizeCtl,新数组长度*0.75
总结
Q:为什么JDK1.8中抛弃了segment的概念,而把每个桶作为最小粒度?
A:加锁的对象时每个链表或红黑树的头结点,减小锁粒度,提高并发度。
Q:既然已经使用了CAS的无锁操作来保证原子性,为什么还要锁住每个链表或红黑树的头结点?
A:防止在一个线程对某个桶下的链表或者红黑树节点进行写操作时,另外一个线程引起了扩容操作,导致链表或者红黑树中的元素index发生变化,当前线程计算出的hash值不能找到对应的节点等情况。















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}