







 文章介绍了Mini-Gemini框架,通过高分辨率解决方案、高质量数据和扩展应用,提升多模态视觉语言模型的性能。该框架使用CLIP和ConvNext-L进行预训练,通过优化策略和大量数据集训练,实现在多模态任务中的先进处理能力。
文章介绍了Mini-Gemini框架,通过高分辨率解决方案、高质量数据和扩展应用,提升多模态视觉语言模型的性能。该框架使用CLIP和ConvNext-L进行预训练,通过优化策略和大量数据集训练,实现在多模态任务中的先进处理能力。

一、背景
在数字化时代,人工智能的发展正以前所未有的速度推进。特别是在多模态学习领域,结合视觉和语言的能力已成为研究的热点。最近,一篇名为“Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models”的文章在arXiv上发表,为我们展示了一个简单而有效的框架,旨在提升多模态视觉语言模型(VLMs)的性能。它即能直接提升图像感知能力,也能作为多模态环境下图像生成任务的前置prompt生成器。主要探索了如何增强图像全局感受野,以及探索了如何融合现有ocr工具来增强图像中文本感知能力。
论文:https://arxiv.org/pdf/2403.18814.pdf
代码:https://github.com/dvlab-research/MiniGemini
二、原理
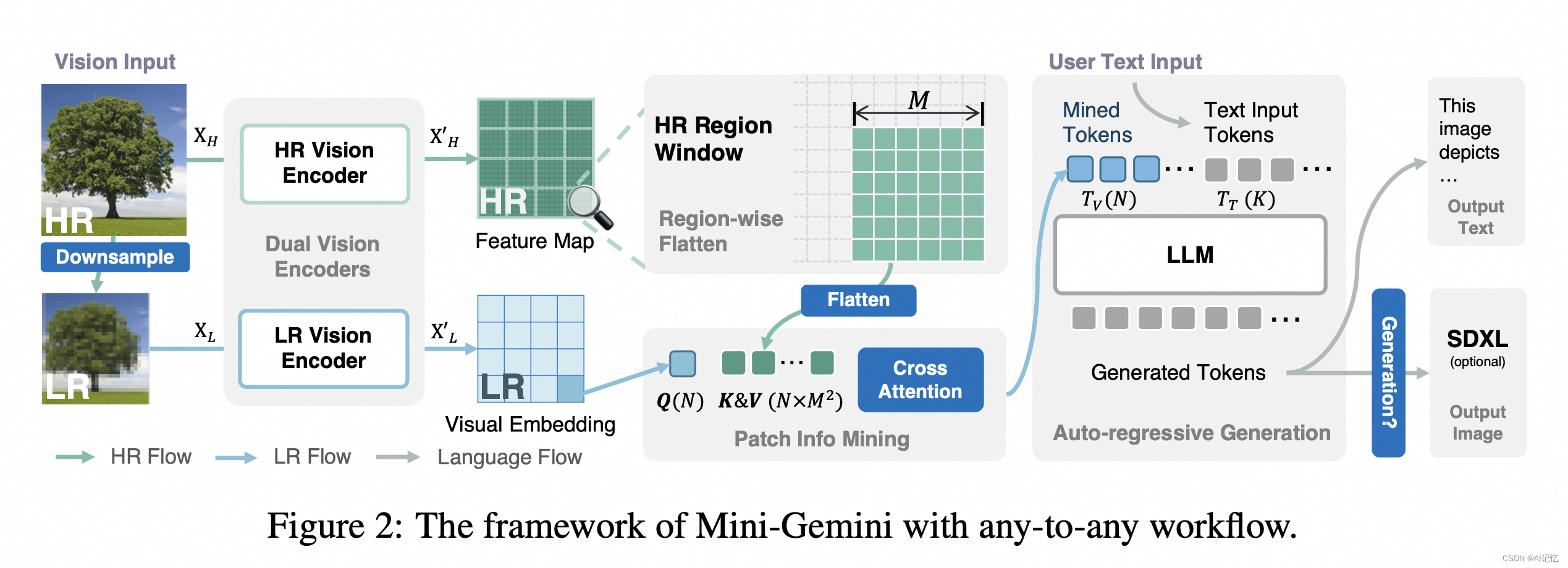
本文的核心训练逻辑围绕Mini-Gemini框架的三个关键方面展开:高效的高分辨率解决方案、高质量数据和扩展应用。以下是这些方面的具体训练逻辑:
-
高效的高分辨率解决方案:
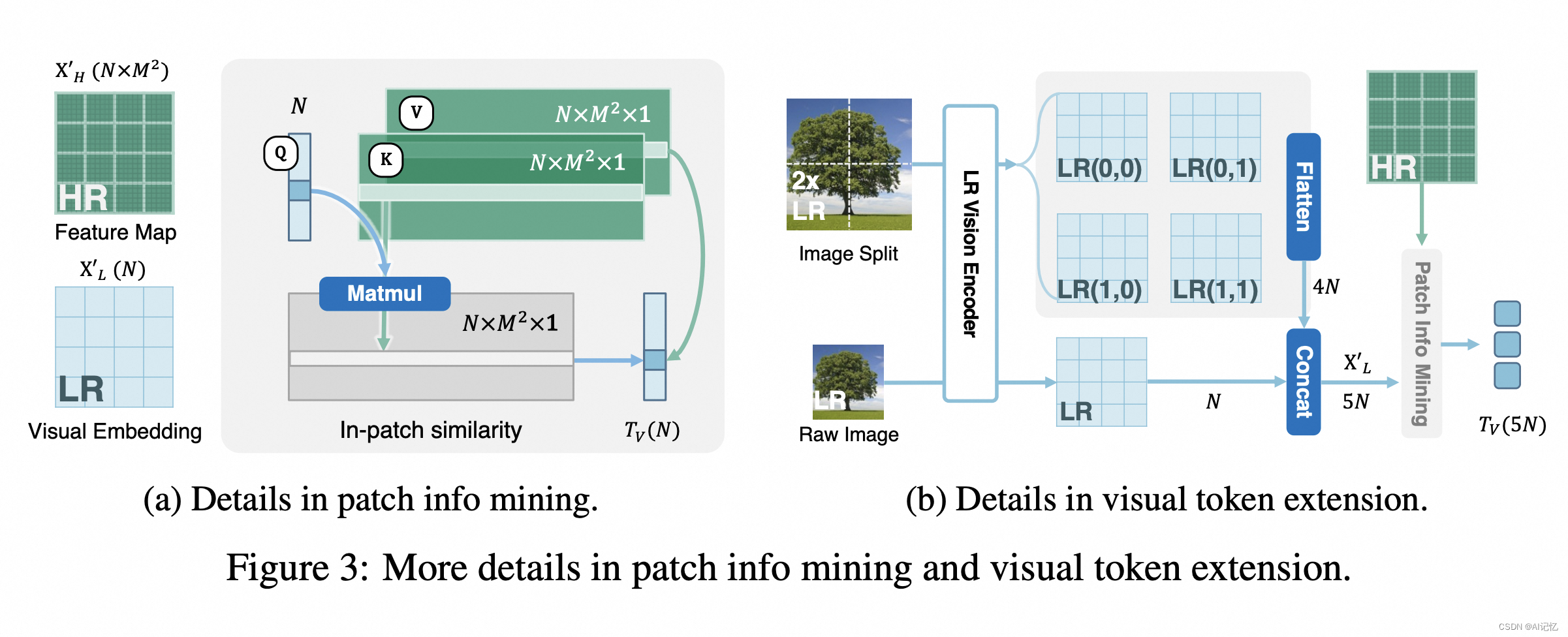
- 利用ConvNet作为HR视觉编码器,以高效地生成高分辨率候选图像,同时保持LLMs的视觉标记数量不变。
- 通过双编码器系统(LR和HR)和注意力机制,使得在推理时,LR编码器生成视觉查询,而HR编码器提供候选键和值,从而在不增加计算负担的情况下增强视觉细节。
-
高质量数据:
- 通过整合来自不同公共资源的高质量数据集,确保数据的基础丰富多样。
- 收集和生成基于公共资源的更多数据,包括高质量的响应、面向任务的指令和与生成相关的数据,以提高整体性能并扩展模型的能力。
-
扩展应用:
- 采用任何到任何(any-to-any)的范式,处理图像和文本作为输入和输出。
- 集成最新的LLMs和生成模型,提升VLM性能和用户体验。
- 支持并行图像和文本生成,通过无缝集成VLM与先进的生成模型,利用VLM指导图像生成,提供LLMs生成的文本。
训练过程:
- 实现Mini-Gemini时,使用CLIP预训练的ViTL作为LR视觉编码器,使用LAION预训练的ConvNext-L作为HR视觉编码器。
- 为了高效训练,保持两个视觉编码器固定,并优化所有阶段的补丁信息挖掘投影器。
- 在指令调整阶段,只优化LLM。
- 使用AdamW优化器和余弦学习率调度策略进行模型优化,通常设置学习率为1e−3(模态对齐)和2e−5(指令调整),对于较大的模型(如Mixtral-8×7B和Hermes-2-Yi-34B),调整学习率以确保稳定的指令调整。
- 训练在标准的机器配置上进行,对于最大的模型,使用DeepSpeed Zero3策略在4天内完成优化。
数据集:
- 模型优化使用的数据集主要包括1.2M图像标题对用于模态对齐,以及1.5M单轮或多轮对话用于指令调整。
- 在多个零样本图像基准数据集上报告结果,包括VQAT、MMB、MME、MM-Vet、MMMU和MathVista等。
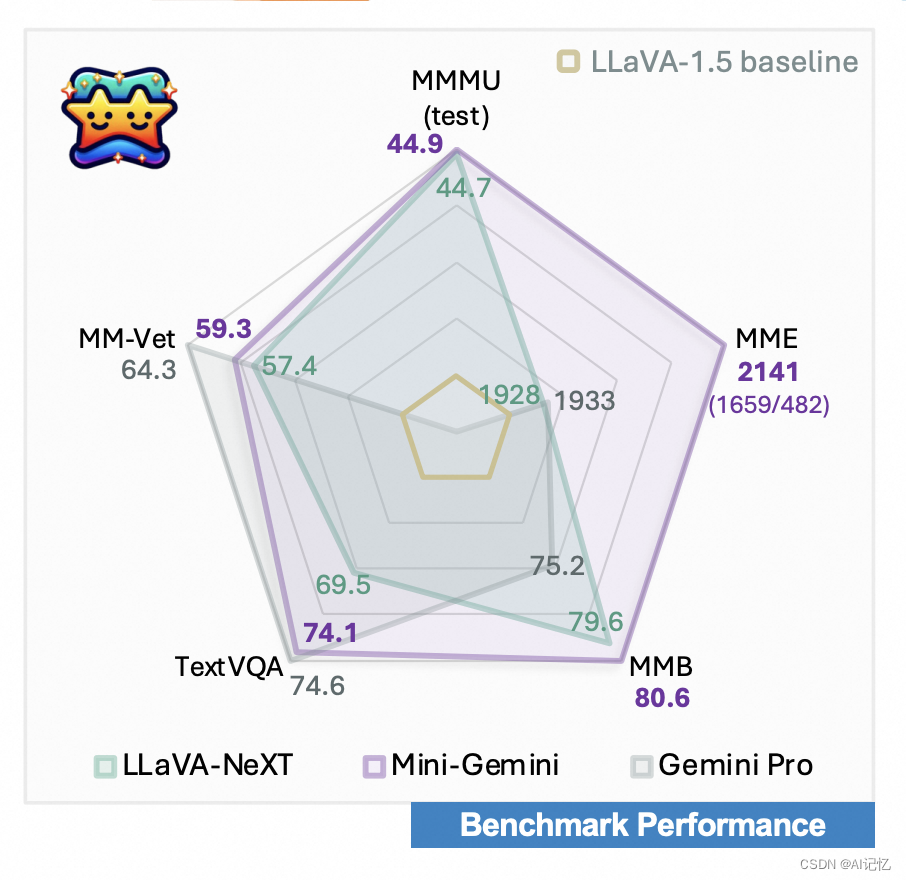
通过这种核心训练逻辑,Mini-Gemini框架能够有效地提升VLMs的性能,并在各种设置中实现先进的多模态任务处理能力。
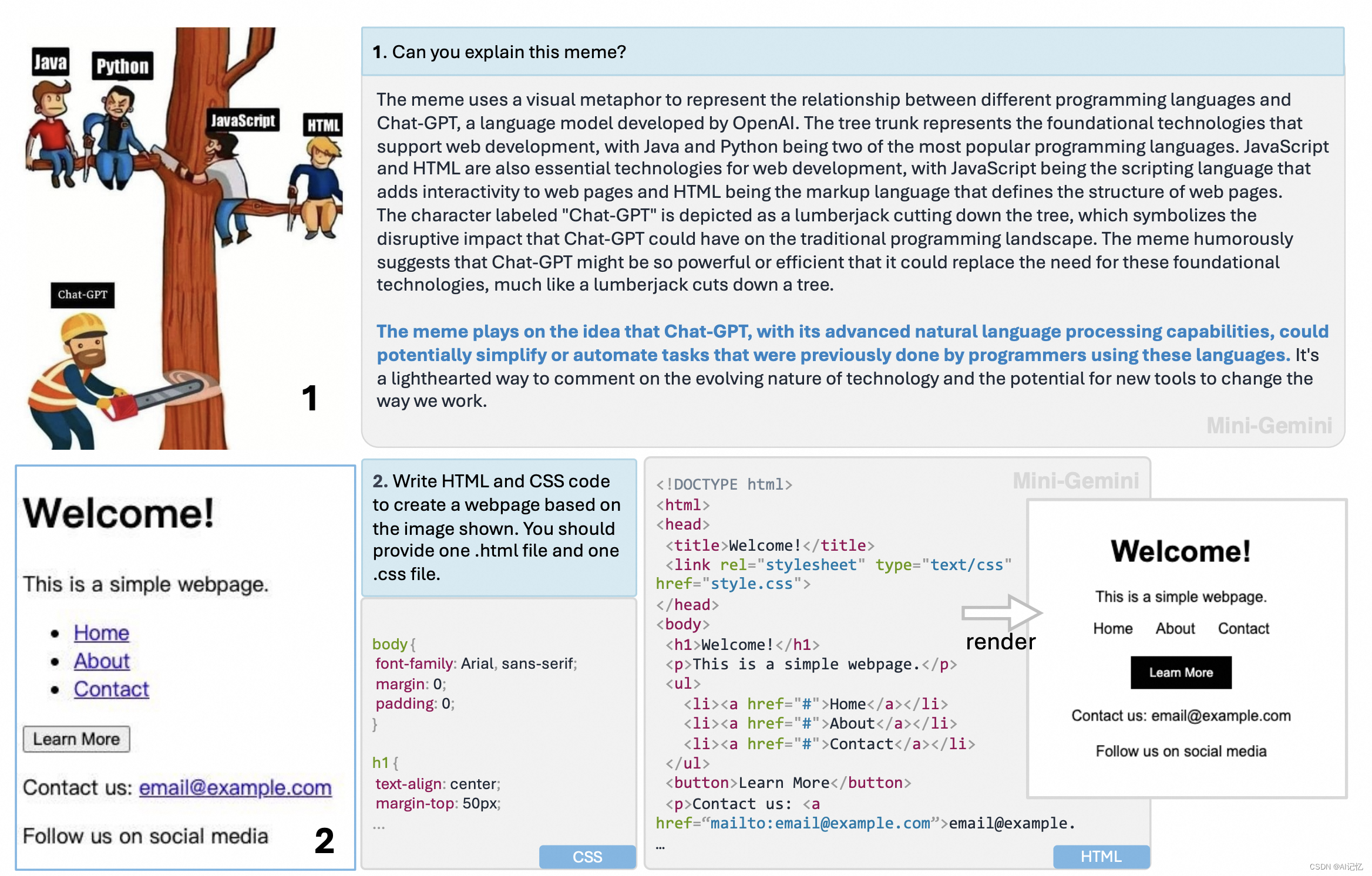
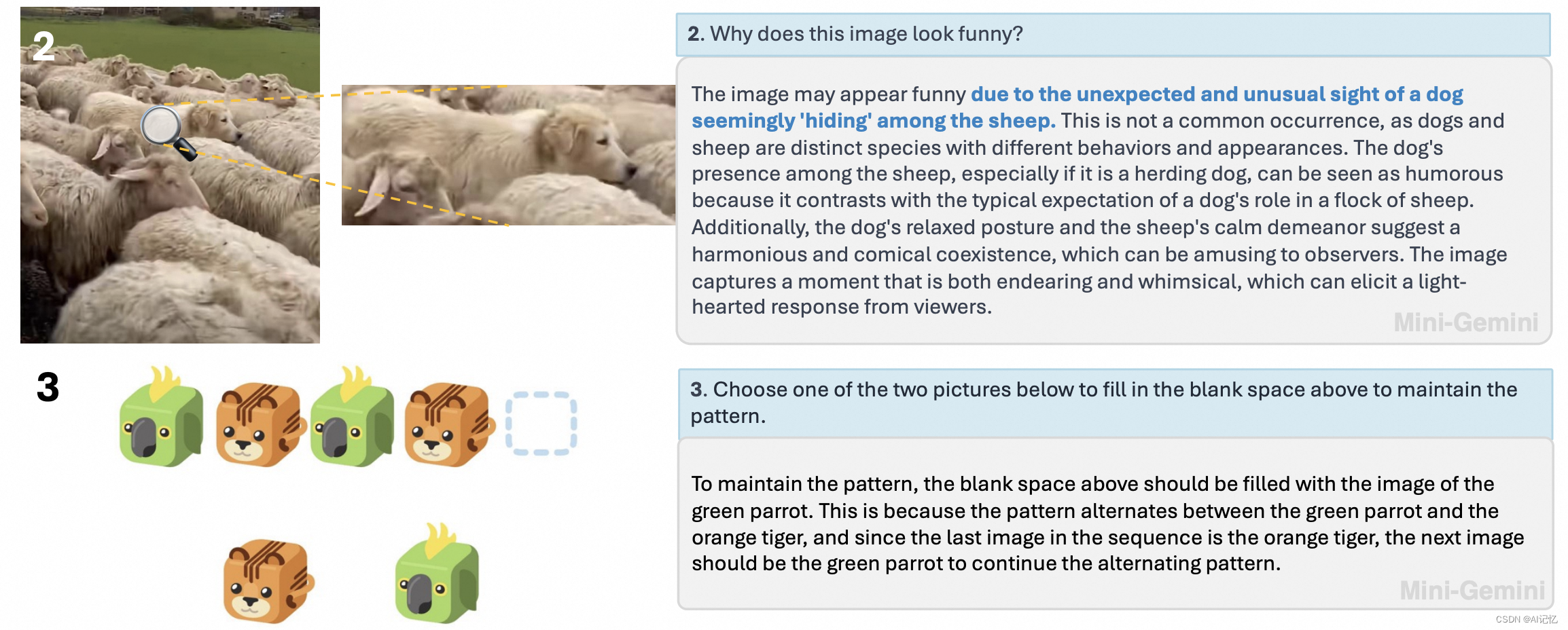
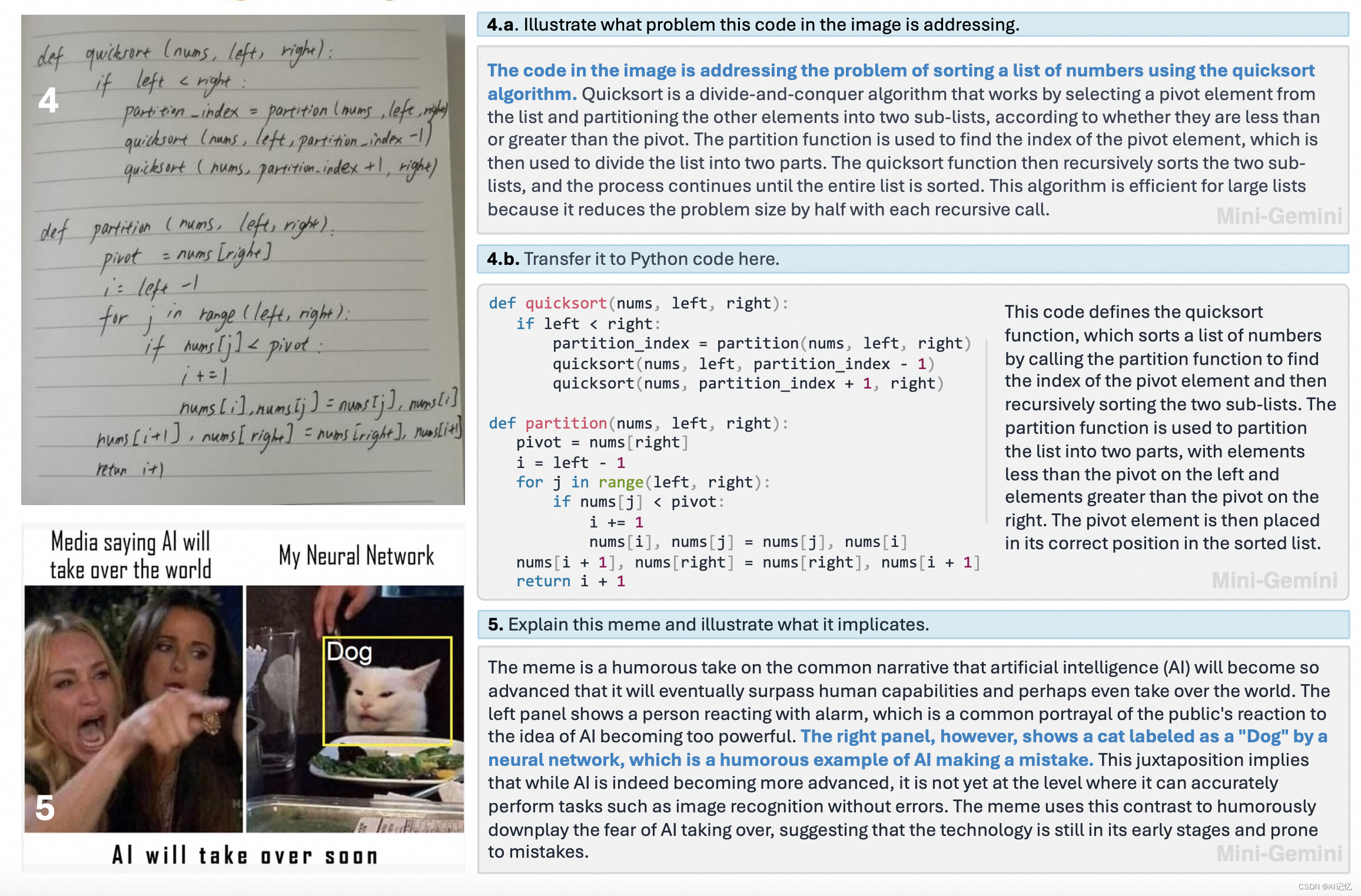
三、效果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











