







一、摘要:

论文:Generative Image Dynamics,https://arxiv.org/pdf/2309.07906
项目主页:https://generative-dynamics.github.io/
本文提出了一种新颖的方法来模拟场景运动的图像空间先验。通过从真实视频序列中提取的自然振荡动态(如树木、花朵、蜡烛和衣物随风摆动)学习运动轨迹,作者将长期运动建模为傅里叶域中的频谱体积。给定单张图片,训练好的模型使用频率协调的扩散采样过程预测频谱体积,进而转换为整个视频的运动纹理。结合基于图像的渲染模块,预测的运动表示可以用于多种应用,例如将静态图像转换为无缝循环视频,或允许用户与真实图像中的对象进行交互,产生逼真的模拟动态。
二、创新:
- 频谱体积表示:引入频谱体积作为运动表示,适用于傅里叶域中的预测和扩散模型。
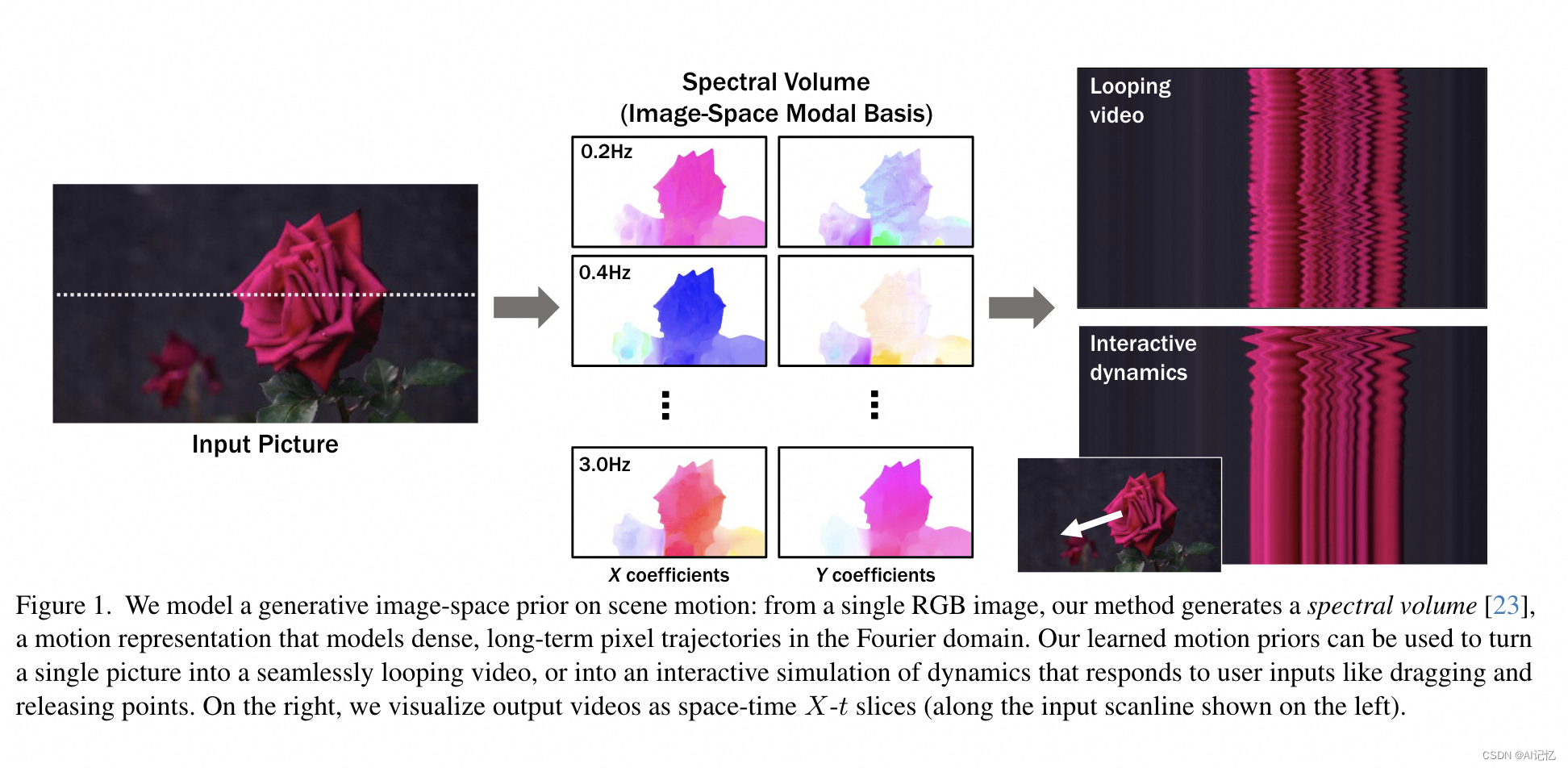
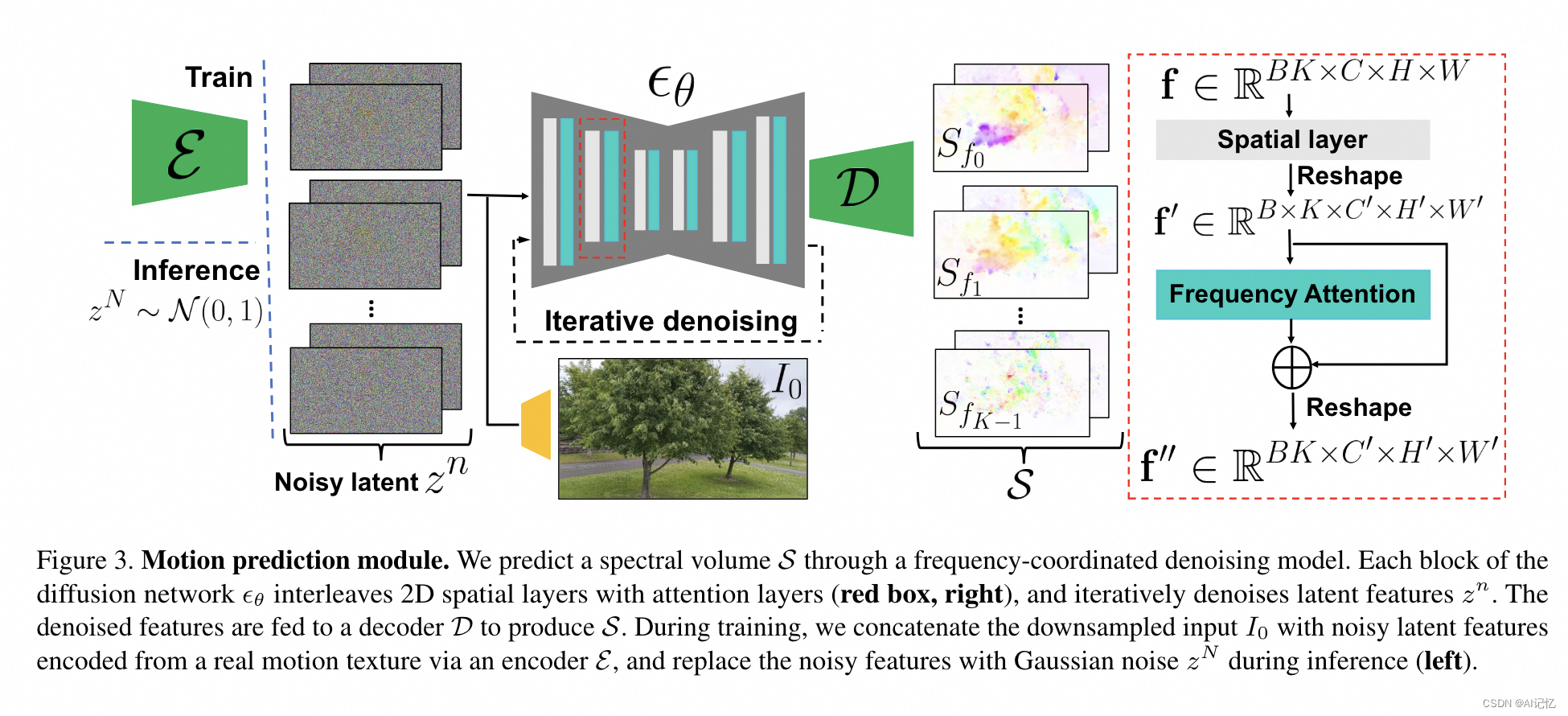
- 运动预测模块:提出了一种新颖的扩散模型,用于逐频率生成频谱体积参数,并通过共享注意力模块跨频率带预测。
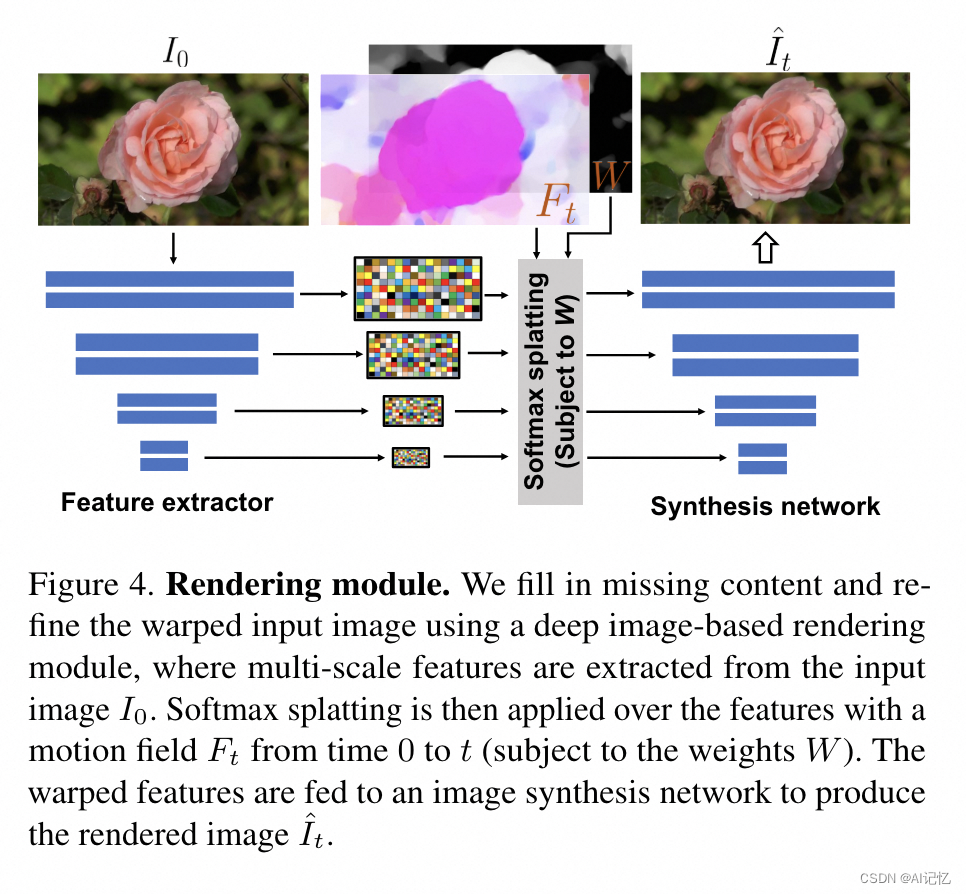
- 基于图像的渲染技术:使用神经图像渲染技术,根据预测的运动纹理动画化输入RGB图像。
- 交互式动态模拟:允许用户通过图像空间模态基与图像中的对象进行交互,模拟对象对用户施加力的响应。
三、实验结果:
a.)定性实验结果
实验部分通过X-t切片图展示了生成视频的时空动态,与真实参考视频相比,本文提出的方法能够更准确地模拟自然运动模式。用户研究表明,本文方法生成的视频在真实感和时间连贯性方面优于现有方法。
b.)定量实验结果
本文方法在多个评价指标上显著优于基线方法,包括Fréchet Inception Distance (FID)、Kernel Inception Distance (KID)、Fréchet Video Distance (FVD)及其变体。这些结果表明,本文方法生成的视频在图像质量和视频合成方面具有更高的逼真度和时间一致性。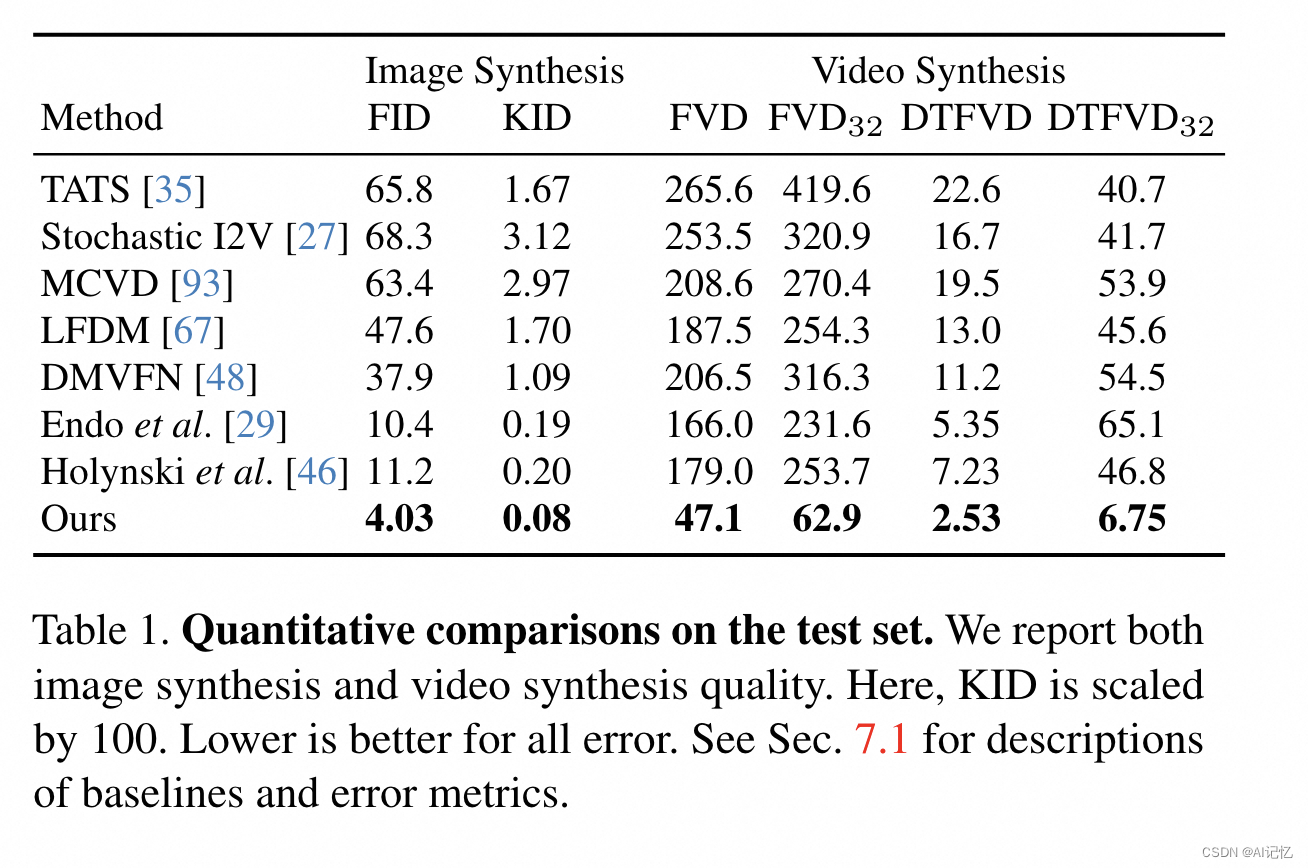
c.)ablation study
消融研究验证了本文方法中主要设计选择的有效性。通过比较不同变体,如使用不同数量的频率带、去除频率自适应归一化、独立预测每个频率切片等,证明了完整模型配置的性能优势。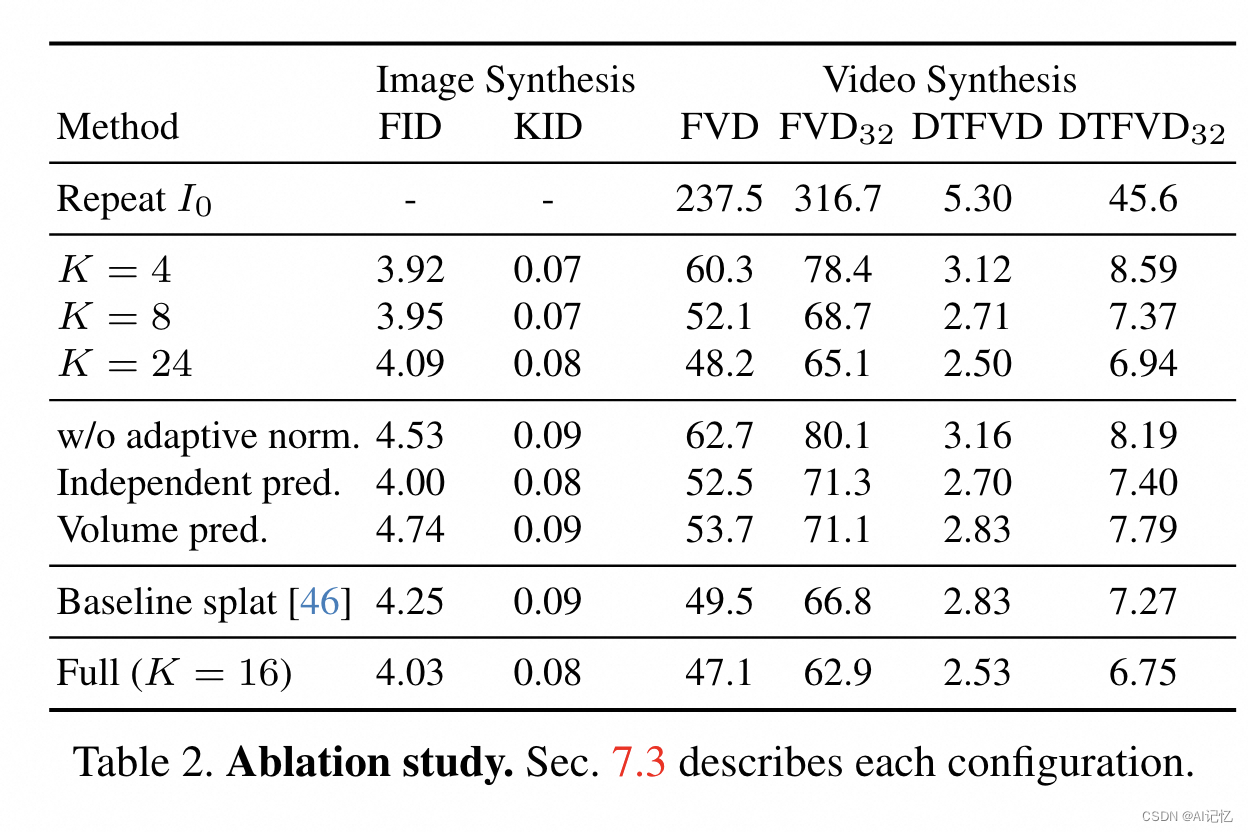
d.)Limitations
在细小的物体、运动较大、需要填充区域较大的情况下,会有相应的artifact。另外无法模拟非振荡性运动或高频振动。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











