






背景:
在解析阮大大的博客文章,发给自己阅读的时候,碰到了一些解析方面的问题。
网页的结构是很简单的拼接式的。
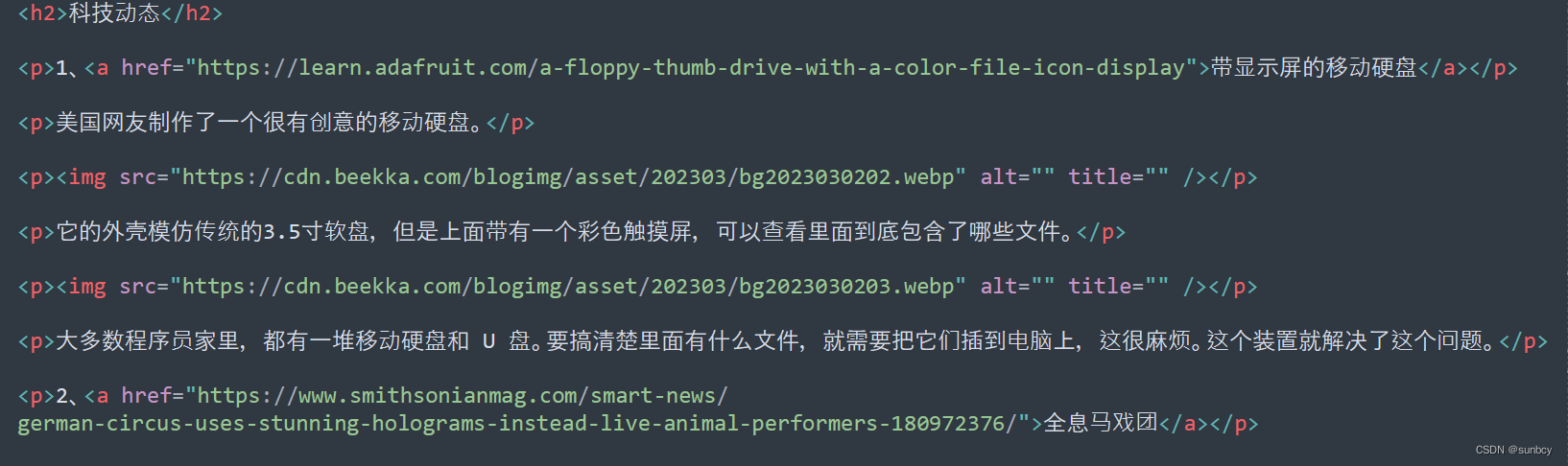
问题:
已经拿到了etree对象解析过后的html对象。
html = etree.HTML(r.text)
article = html.xpath('//article[@class="hentry"]')[0]
entry_content = article.xpath('//div[@class="asset-content entry-content"]')[0]
entry_h2 = entry_content.xpath('//h2/text()')
想打印entry_h2 ,发现打印出来了不属于entry_h2 的部分元素【 ‘相关文章’, ‘广告’, ‘留言(58条)’, ‘我要发表看法’】
:

下面这个才是我想要的:

应改为entry_h2 = entry_content.xpath(‘.//h2/text()’)。
多加的那个点表示从该元素索引。
想打印entry_content 对应的html网页:
打印出来发现是乱码。
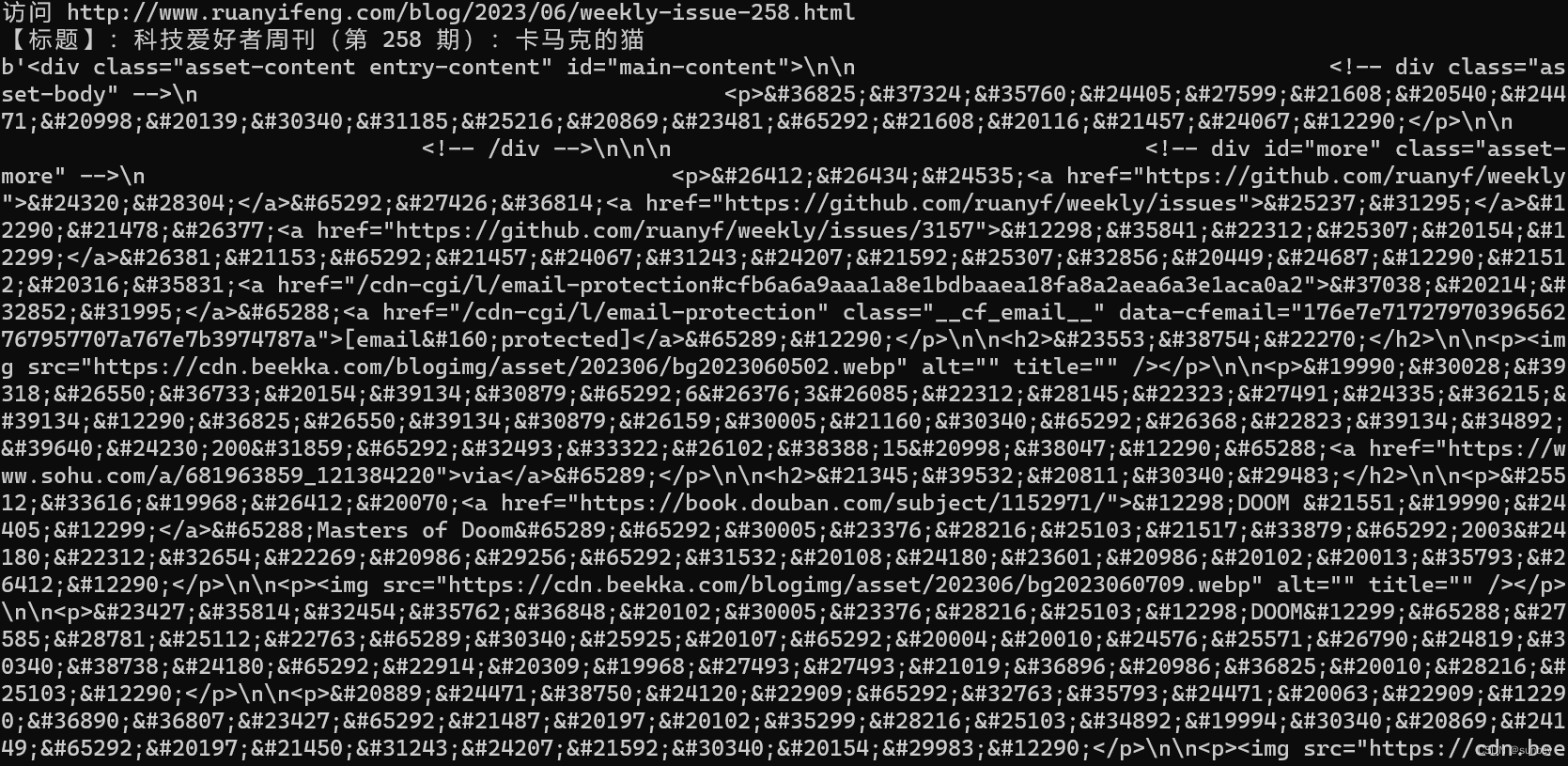
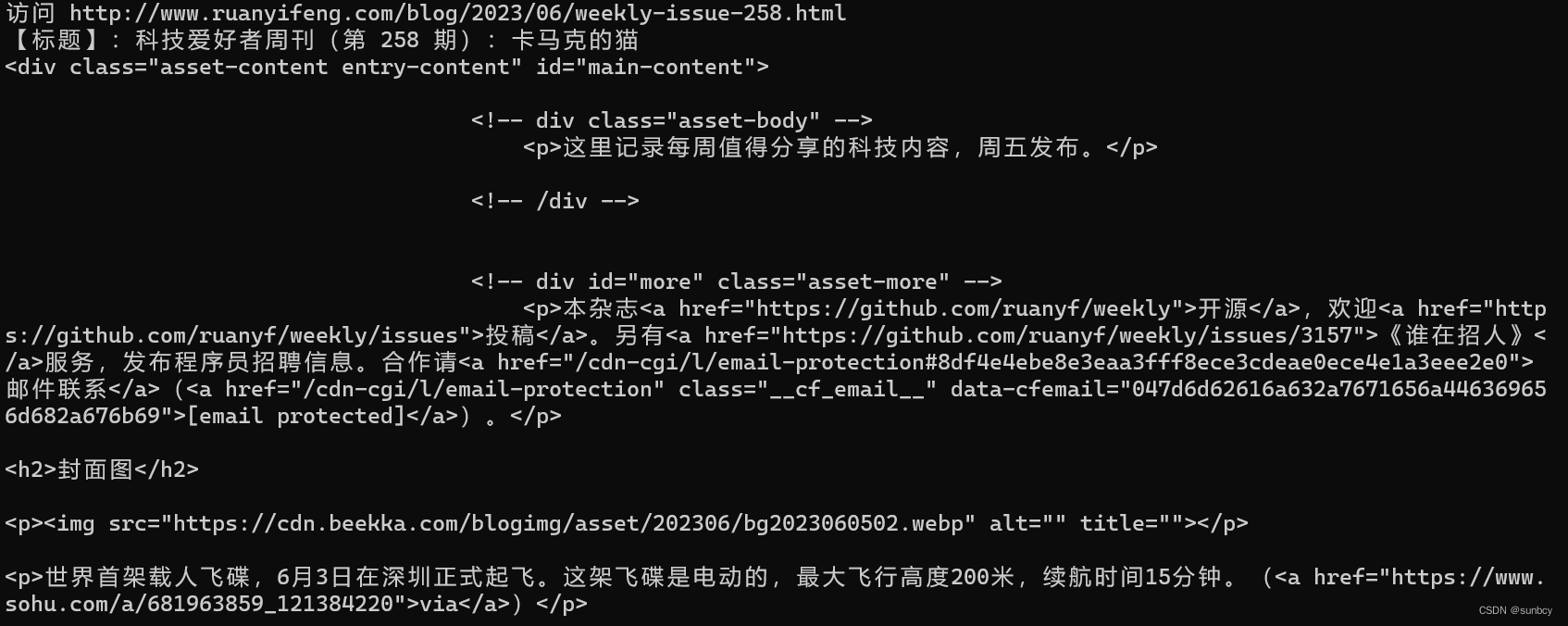
搜索后发现etree.tostring()方法可以将该网页编码转换为含中文的编码,完整的写法如下:
etree.tostring(entry_content,encoding = r.encoding, pretty_print=True, method=“html”).decode(“utf-8”)
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











