







python 爬虫学习之旅
这里我们用到 python,和开发环境IDE pycharm。
完整的爬虫包括爬取网页,解析数据,保存数据
目录
- python 爬虫学习之旅
- 重点提要
- 最终代码
- python常见错误
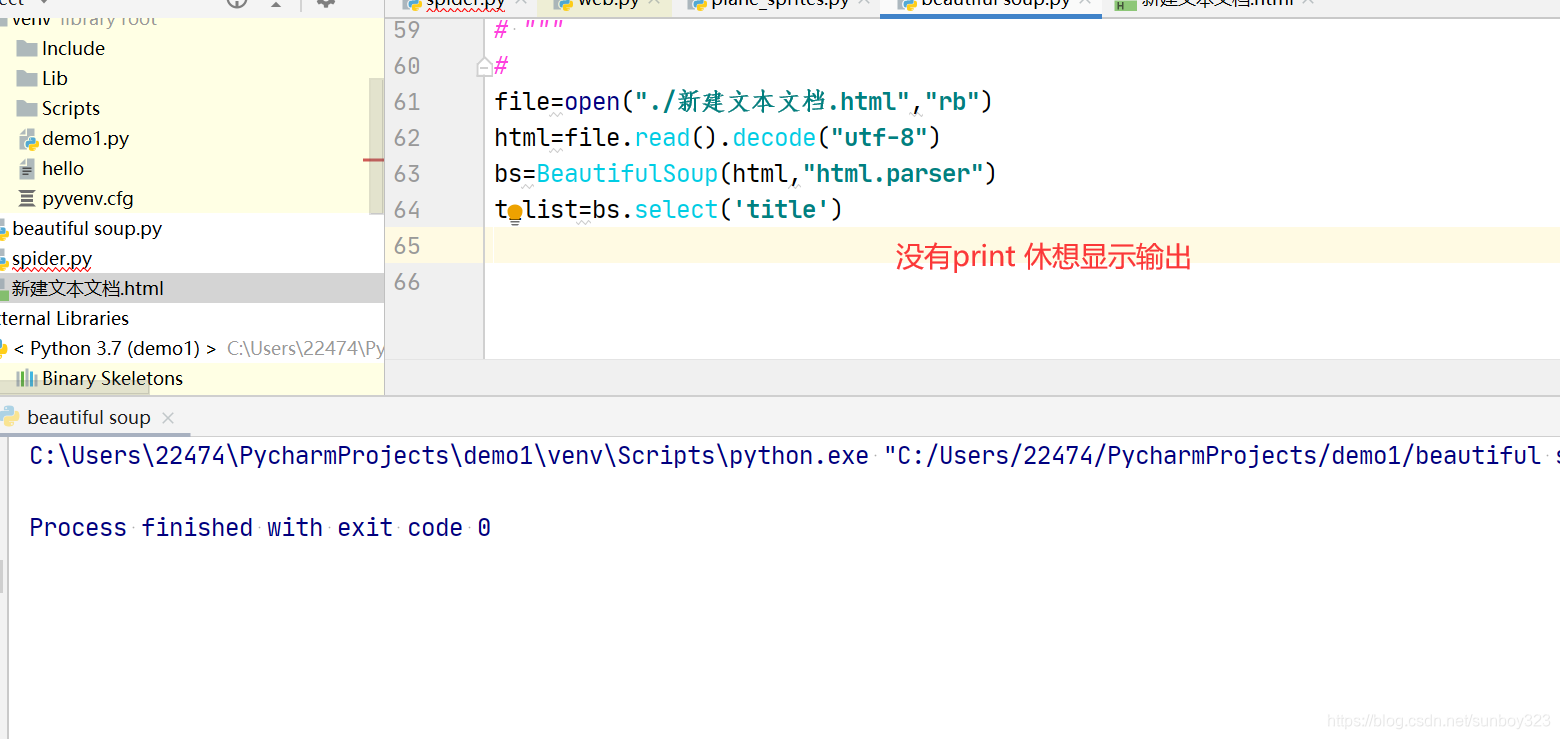
- 1.一直只显示运行成功,啥都不输出。不可原谅,因为忘记了打印。只有打印print,才会输出。
- ***2.这个会导致NAME XXX has not defined***
- 3.Python: 编程遇到的一些问题以及网上解决办法?
- 4.python常见错误:IndentationError: unexpected indent
- 5.python 错误 SyntaxError: invalid character in identifier
- 6. line 307, in __init__ elif len(markup) <= 256 and TypeError: object of type 'NoneType' has no len()
- 7.TypeError: 'set' object is not subscriptable
- 8.PermissionError: [Errno 13] Permission denied: 'はじめまして.xls'
- pycharm小技巧必备
重点提要

最终代码
#引入自定义模块
# from test1 import t1
#
#
# print(t1.add(3,5))
#引入系统模块
import sys
import os
import bs4
import urllib.request
import urllib.error
# from bs4 import beautifulsoup4
def main():
url="https://movie.douban.com/top250?start=0&filter="
#1.爬取网页
datalist=getData(url)
savepath=".\\豆瓣电影.top250.xls"
askurl("https://movie.douban.com/explore#!type=movie&tag=%E6%9C%80%E6%96%B0&page_limit=20&page_start=")
#3.保存数据
saveData(savepath)
#爬取网页
def getData(url):
datalist=[]
for i in range(0,10):#调用获取信息的页面10次 一页25条 这个是左闭右开,实际是【0,10)。所以他会得到1-9
url=url+str(i*25)
"""
0代表第一个网页里的25条,9代表第十个网页。
"""
html=askurl(url)#保存获取到的网页源码。接收。。
# 2.逐一解析数据
return datalist
#爬取一个url的信息
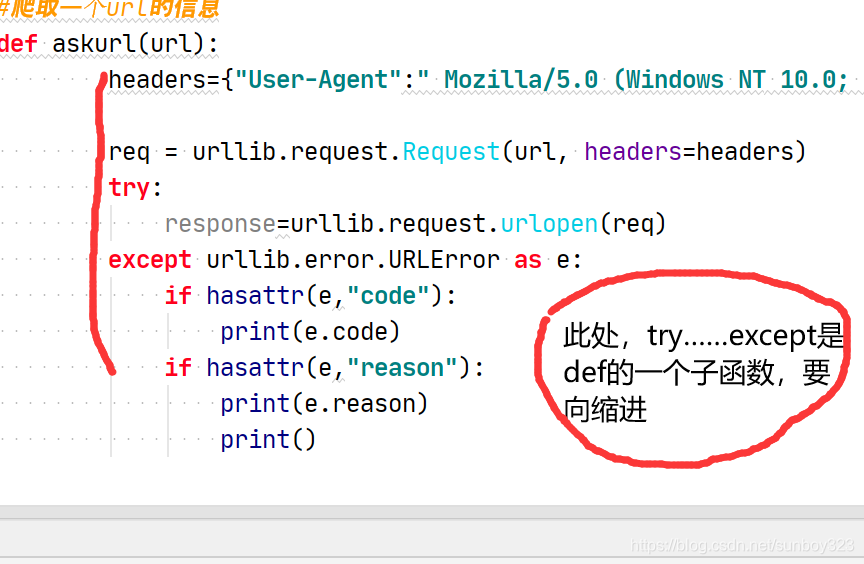
def askurl(url):
headers={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
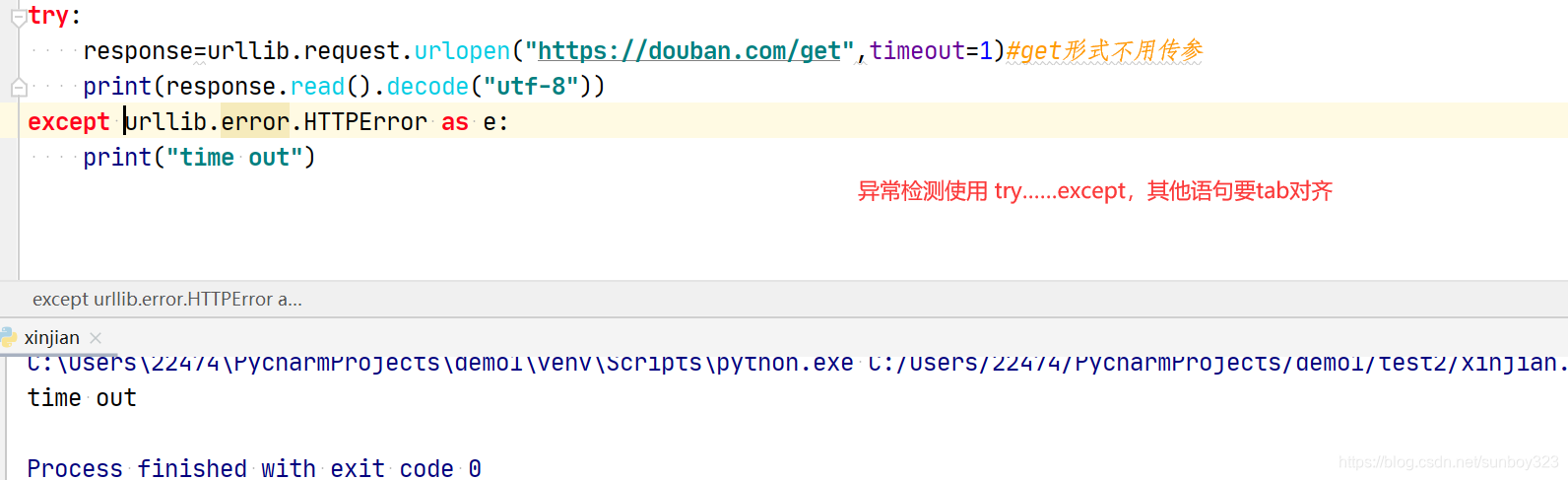
try:
response=urllib.request.urlopen(req)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
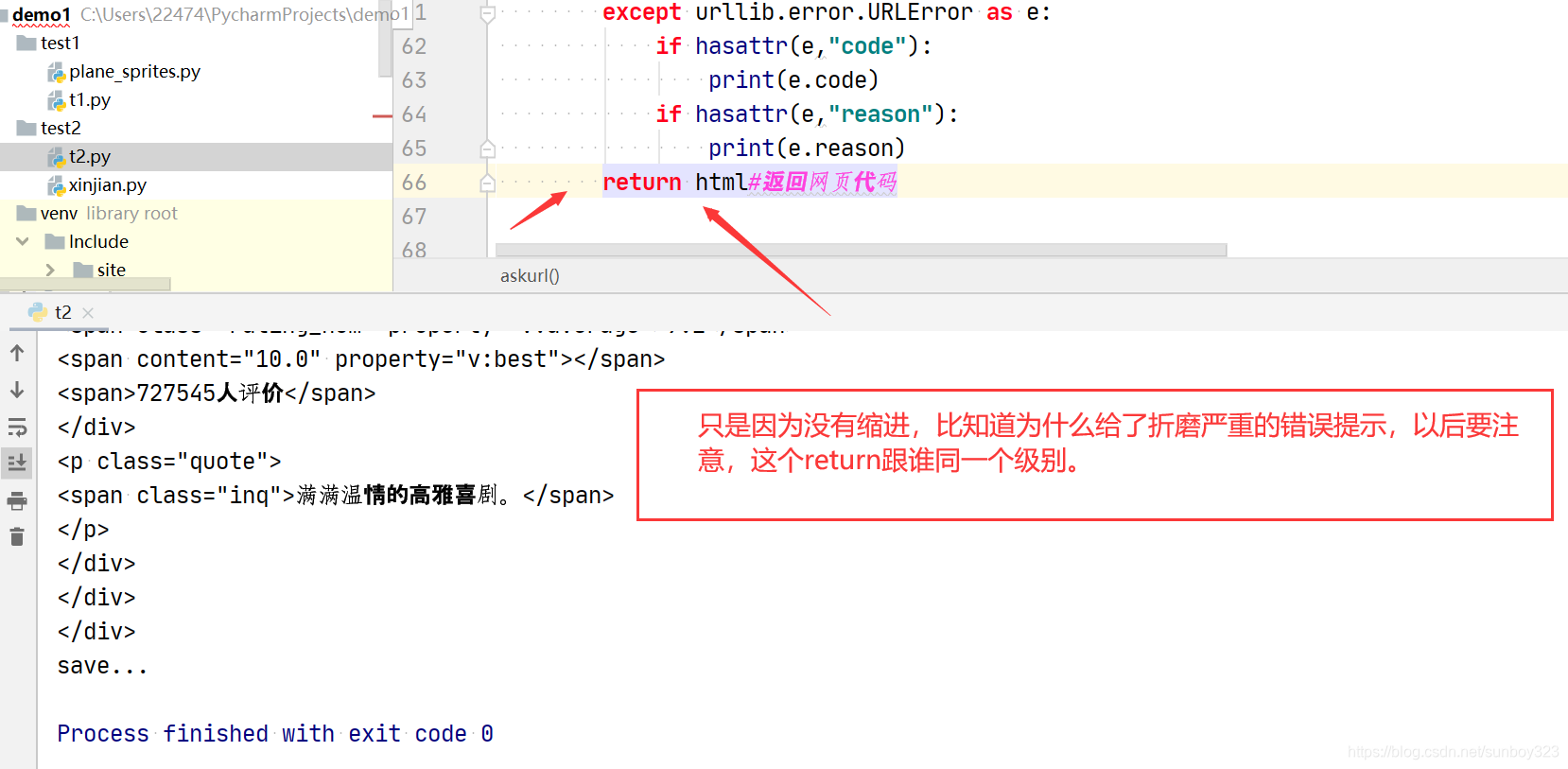
return html#返回网页代码
#保存数据
def saveData(savepath):
print("save...")
#当程序被执行
if __name__ == '__main__':
main()
python常见错误
1.一直只显示运行成功,啥都不输出。不可原谅,因为忘记了打印。只有打印print,才会输出。
2.这个会导致NAME XXX has not defined
Python中对错误NameError: name ‘xxx’ is not defined进行总结
3.Python: 编程遇到的一些问题以及网上解决办法?
4.python常见错误:IndentationError: unexpected indent
【问题】
一个python脚本,本来都运行好好的,然后写了几行代码,而且也都确保每行都对齐了,但是运行的时候,却出现语法错误:IndentationError: unexpectedindent
【解决过程】1.对于此错误,最常见的原因是,的确没有对齐。但是我根据错误提示的行数,去代码中看了下,没啥问题啊。都是用TAB键,对齐好了的,没有不对齐的行数啊。
2.以为是前面的注释的内容影响后面的语句的语法了,所以把前面的注释也删除了。结果还是此语法错误。
3.后来折腾了半天,突然想到了,把当前python脚本的所有字符都显示出来看看有没有啥特殊的字符。当前用的文本编辑器Notepad++,好像有个设置,可以显示所有的字符的。找到了,
在:视图> -> 显示符号 -> 显示空格与制表符
5.python 错误 SyntaxError: invalid character in identifier

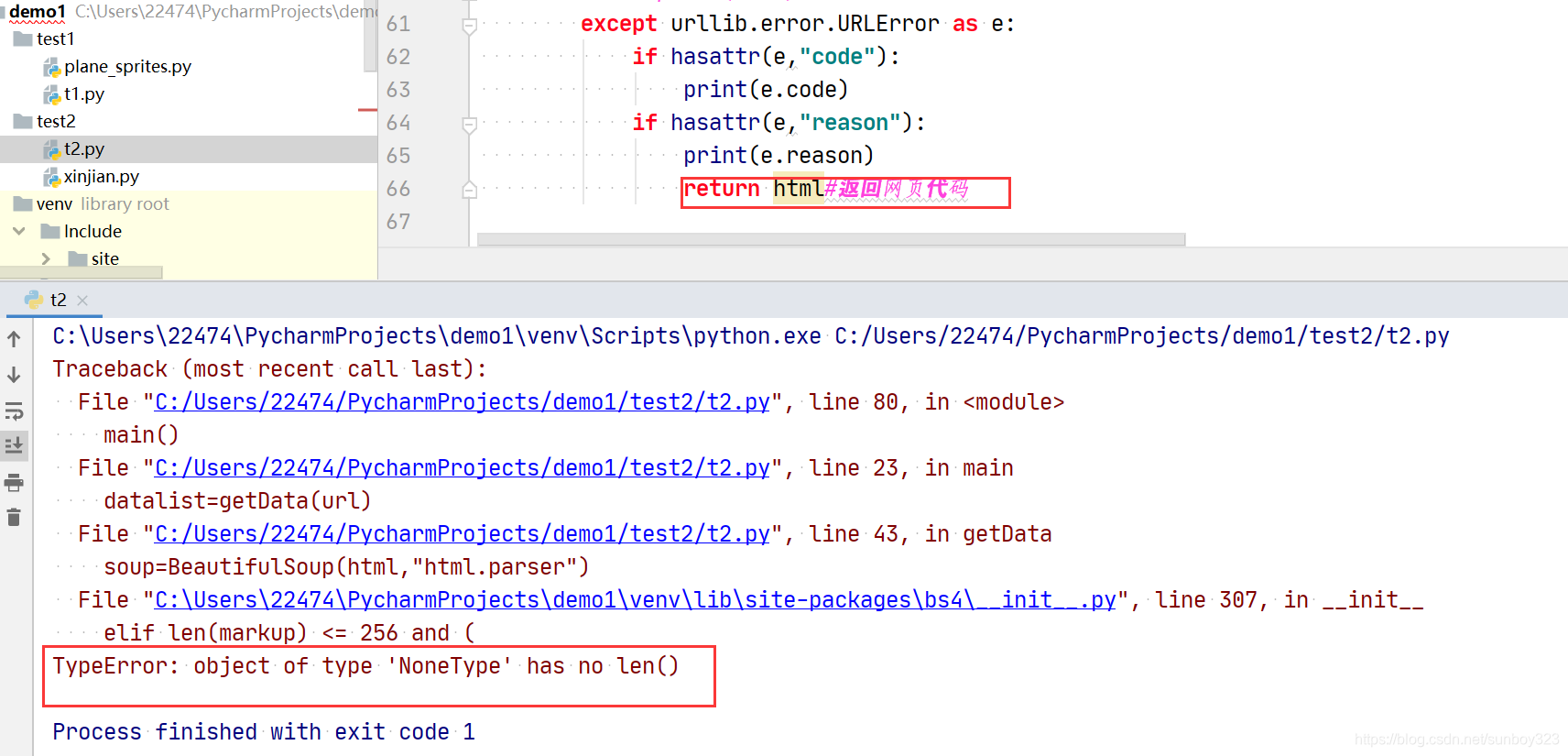
6. line 307, in init elif len(markup) <= 256 and TypeError: object of type ‘NoneType’ has no len()
我真的快吓傻了,这则膜处理,百度上都是蛇魔回答,我都蒙了,快来记录一下,没有笔记记录,真的不行,一定会忘得。
7.TypeError: ‘set’ object is not subscriptable
要不就是你用错符号了。比如g={ },写元组,要用( )。
再就是不能索引
A=“l”不能
A=“sdf”可以
8.PermissionError: [Errno 13] Permission denied: ‘はじめまして.xls’
1.你有可能已经打开了这个文件,关闭这个文件即可
2. open 打开一个文件夹(目录),而不是文件
pycharm小技巧必备
1.多行注释CTRL+? 单行注释#
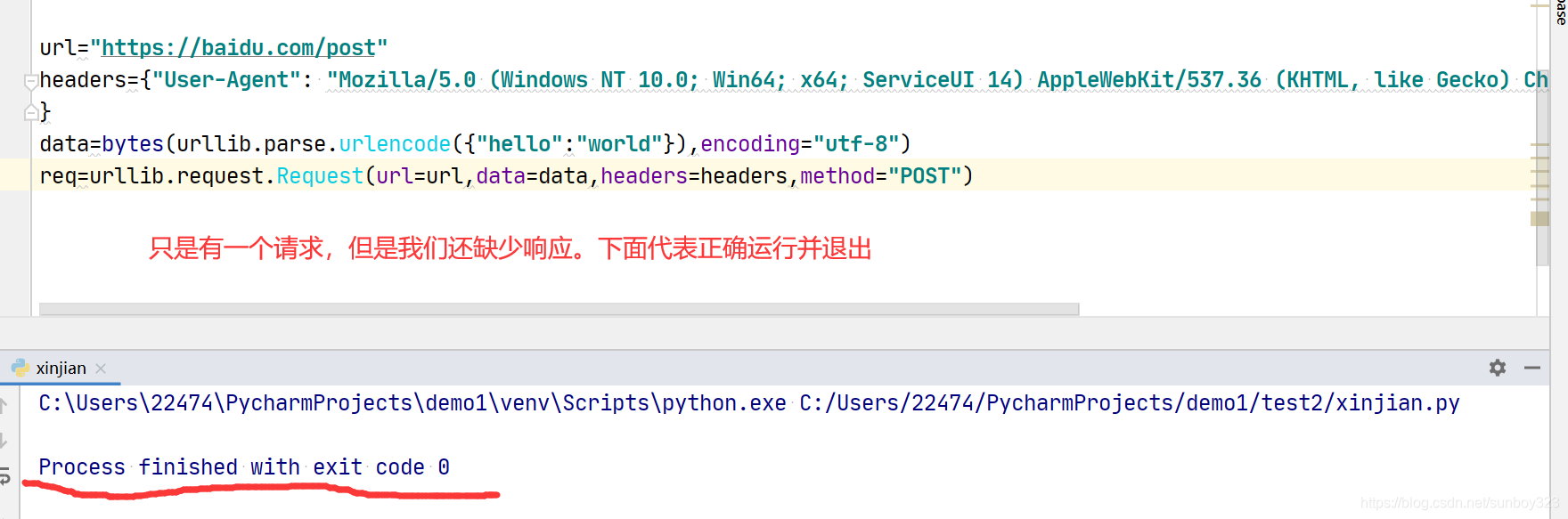
2.data=bytes() 数据转化为二进制包
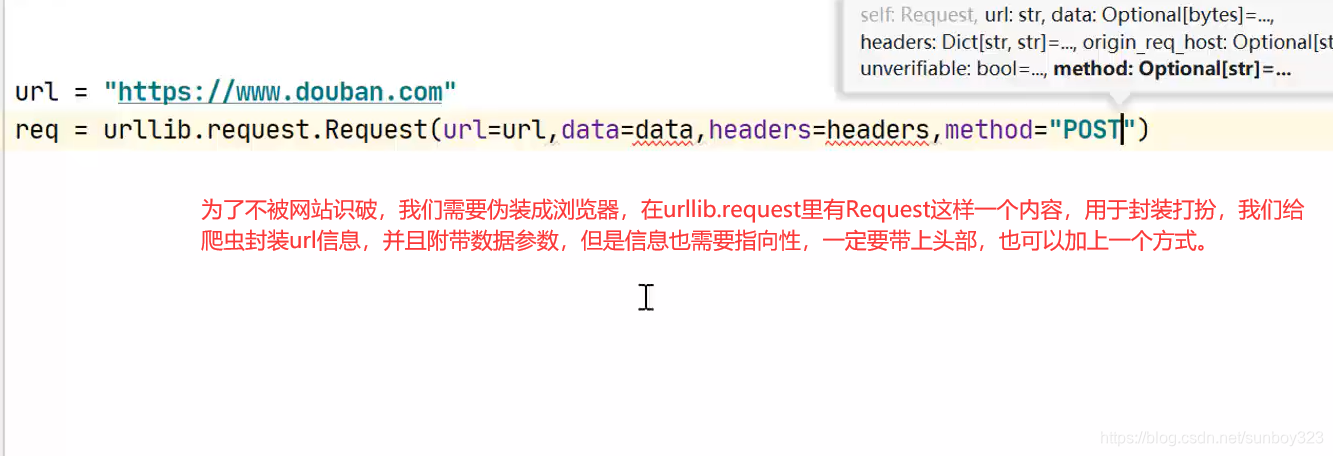
3 import urllib.parse 解析器,解析出的数据转变为2进制,封装到data数据包里面
4.添加固定信息
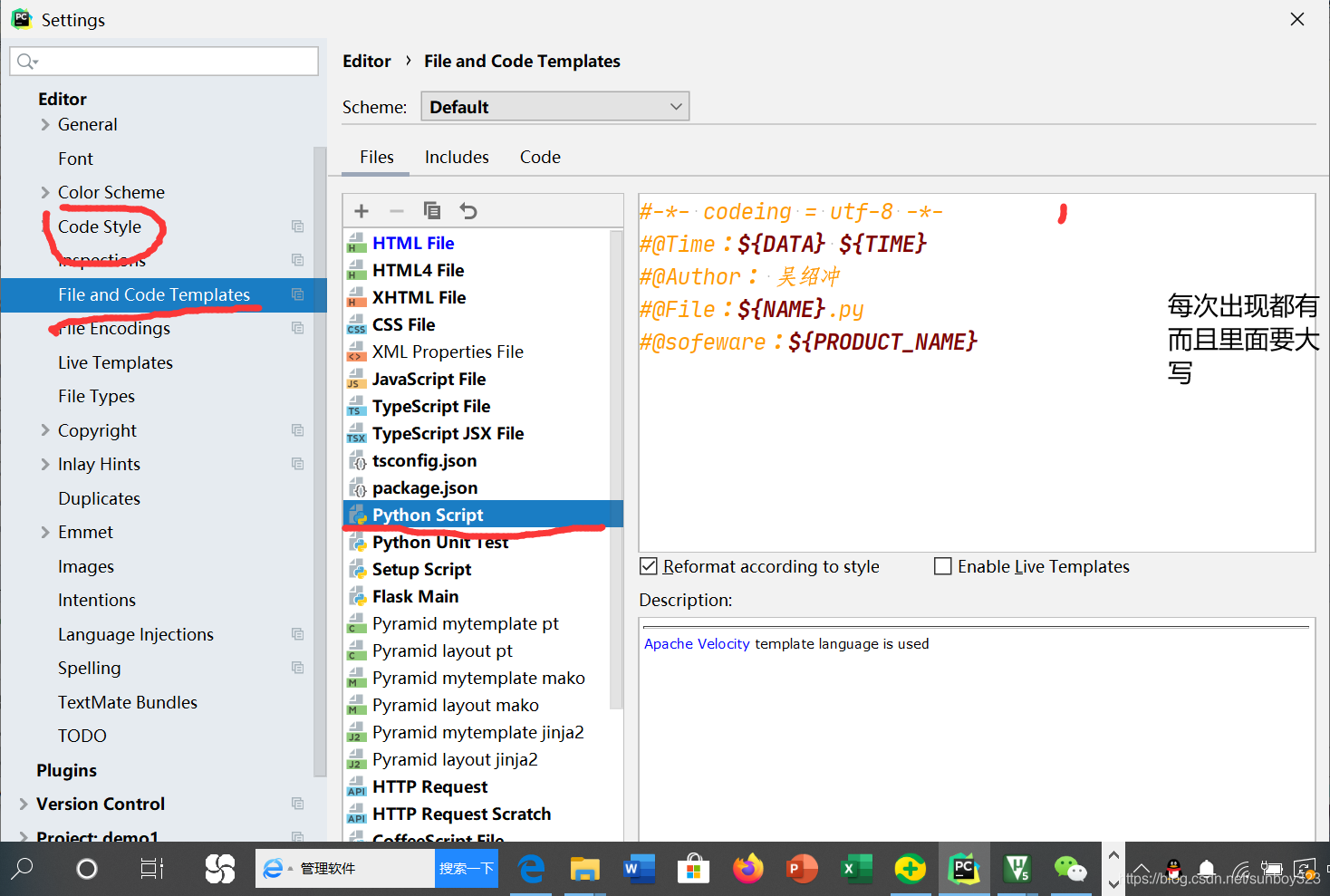
5.装模块
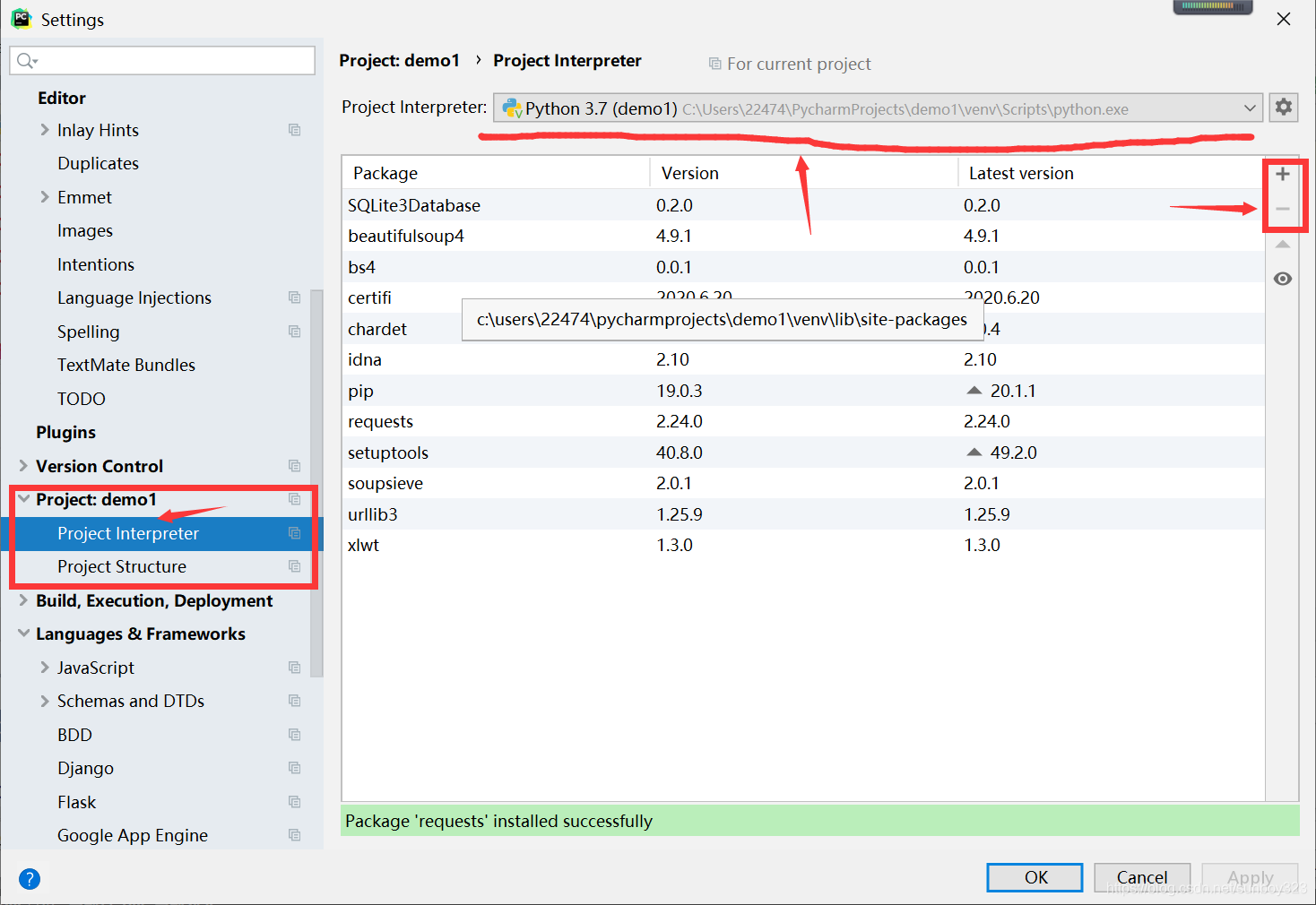

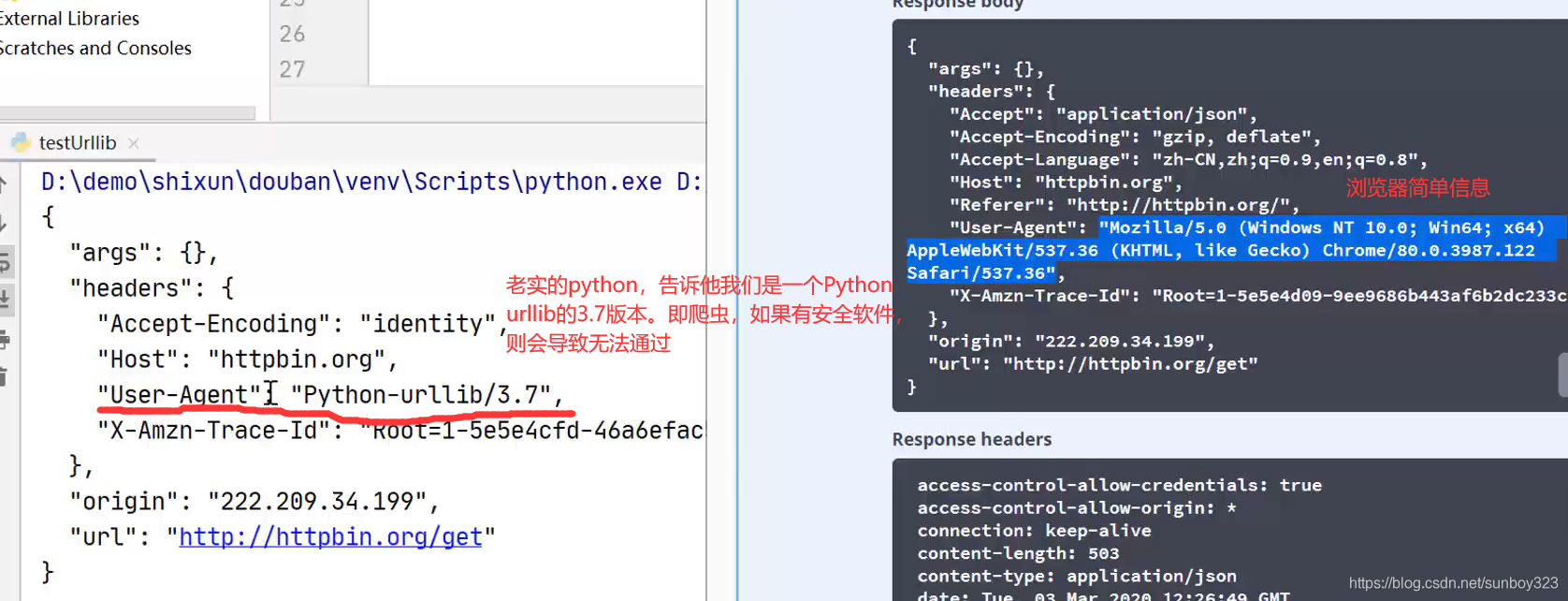
上图,import 是搬运模块的意思,
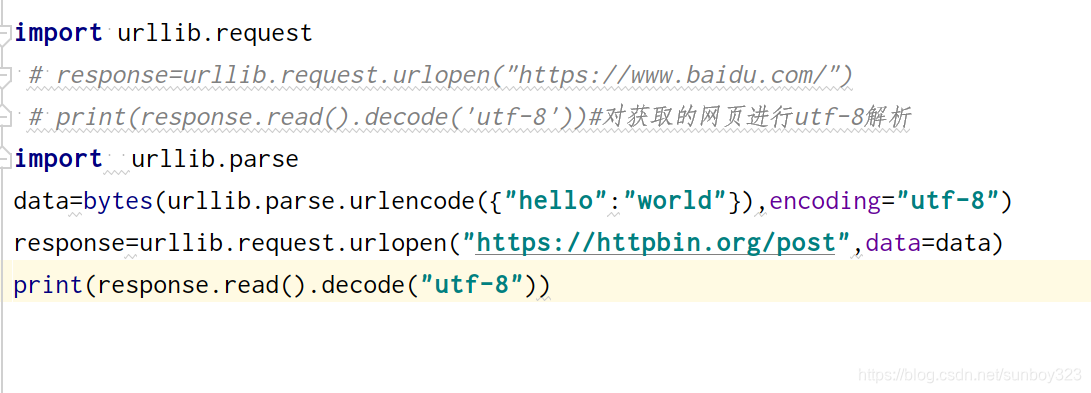
post方式,我们用data来传达参数,data参数使用bytes字节文件封装进去
URL 了解
链接: https://baike.baidu.com/item/统一资源定位系*统/5937042?fromtitle=URL&fromid=110640&fr=aladdin.
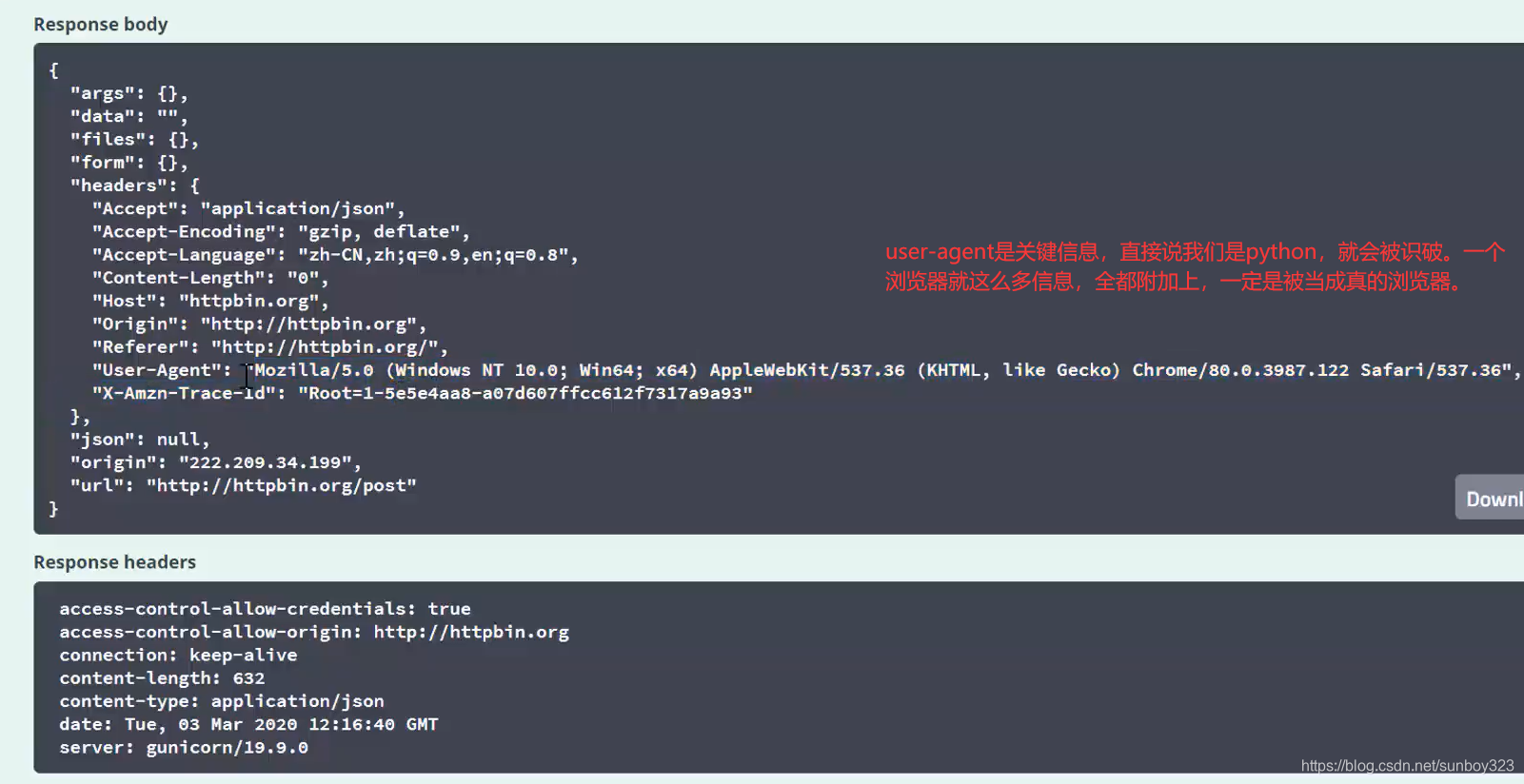
**read ()***读取的信息封存到***response***中,***decode***用于解码,采用***utf-8***方式,使解码不出现乱码。
测试

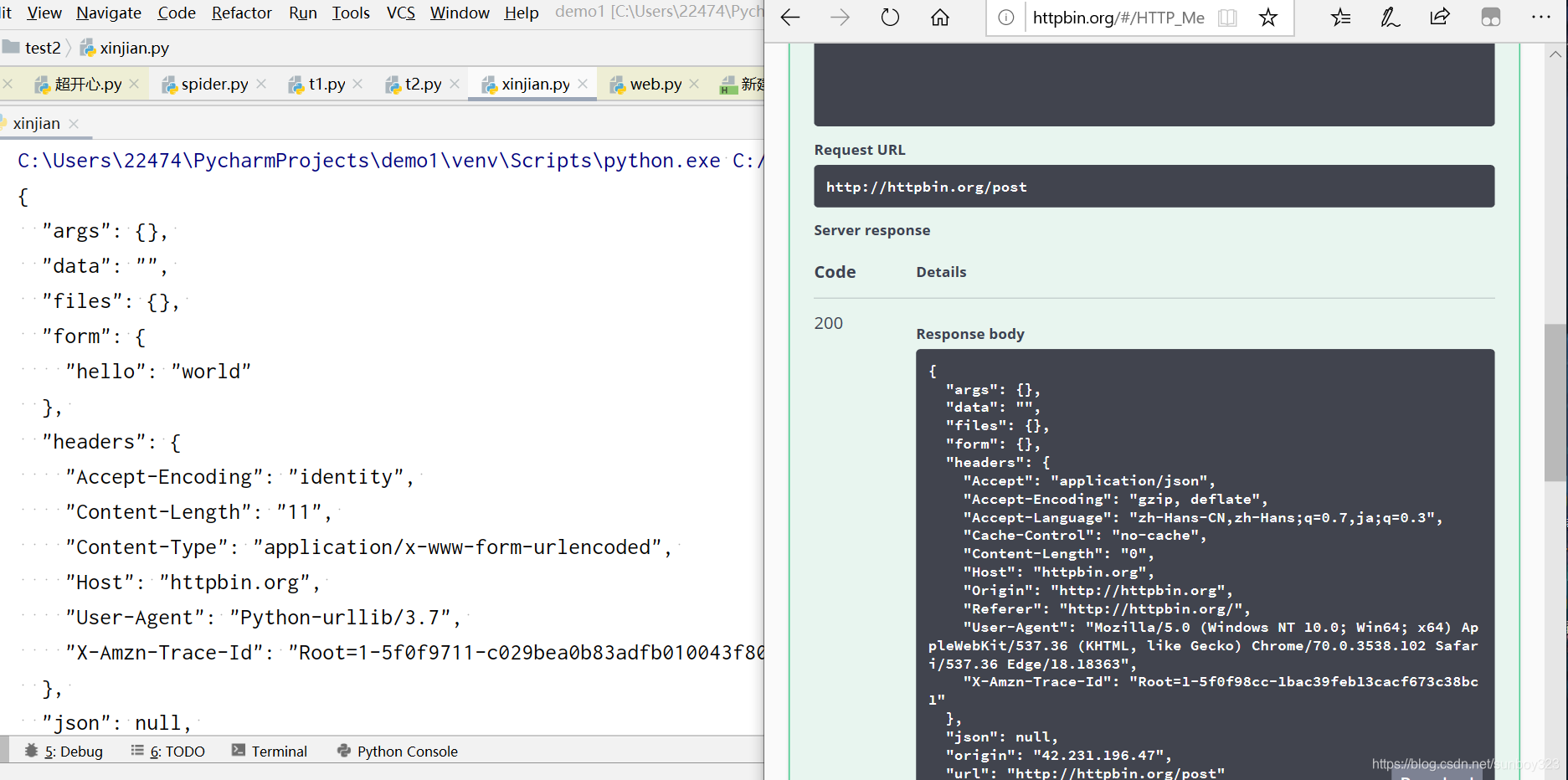
post测试,点击post,Execute代表执行
pycharm颜色设定
异常处理
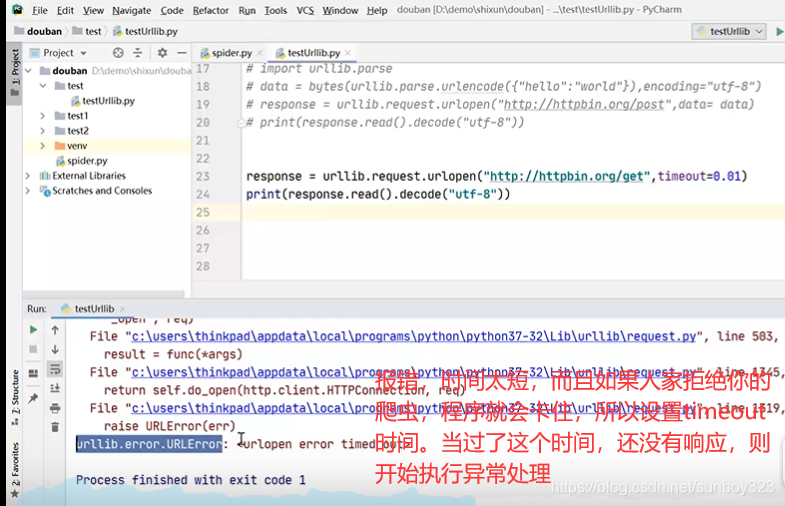

错误类型也可能是其他,多写几个,用逗号分隔·。还有如果链接是死链接,或者确实出现排斥的现象,那么先放过这一个页面,最后通过报错来集中处理。时间1,2秒吧***成功***
状态码
状态码
404找不到
418(我是一个茶壶)对方发现你是一个爬虫
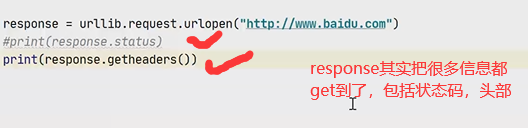
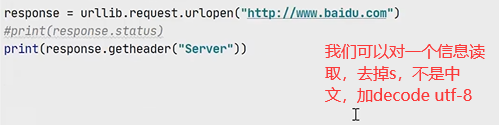
打开控制台
如果你的F12是调节亮度的话,Fn+F12
[链接: https://editor.csdn.net/md/?articleId=107355677.
](https://editor.csdn.net/md/?articleId=107355677)
下面我们来爬取豆瓣的信息。
[爬虫基础入门爬取网页为什么要 选择requests库 而不是选择urllib库呢?
这是因为requests对于处理网页认证和Cookies时 更加 方便 更加 强大!!!
](https://blog.csdn.net/weixin_43930694/article/details/89963102)
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









