







因为有需求,所以自己就稍微琢磨了一下这个东西,然后代码是从网上找的,目前我已经自测过是可以使用的,而且非常方便省事,这里分享给大家!
直接上代码:
# _*_ coding: utf-8 _*_import poplibimport emailimport osfrom email.parser import Parserfrom email.header import decode_headerfrom email.utils import parseaddrdef decode_str(s):value, charset = decode_header(s)[0]if charset:if charset == 'gb2312':charset = 'gb18030'value = value.decode(charset)return valuedef get_email_headers(msg):headers = {}for header in ['From', 'To', 'Cc', 'Subject', 'Date']:value = msg.get(header, '')if value:if header == 'Date':headers['Date'] = valueif header == 'Subject':subject = decode_str(value)headers['Subject'] = subjectif header == 'From':hdr, addr = parseaddr(value)name = decode_str(hdr)from_addr = u'%s <%s>' % (name, addr)headers['From'] = from_addrif header == 'To':all_cc = value.split(',')to = []for x in all_cc:hdr, addr = parseaddr(x)name = decode_str(hdr)to_addr = u'%s <%s>' % (name, addr)to.append(to_addr)headers['To'] = ','.join(to)if header == 'Cc':all_cc = value.split(',')cc = []for x in all_cc:hdr, addr = parseaddr(x)name = decode_str(hdr)cc_addr = u'%s <%s>' % (name, addr)cc.append(to_addr)headers['Cc'] = ','.join(cc)return headersdef get_email_content(message, savepath):attachments = []for part in message.walk():filename = part.get_filename()if filename:filename = decode_str(filename)data = part.get_payload(decode=True)abs_filename = os.path.join(savepath, filename)attach = open(abs_filename, 'wb')attachments.append(filename)attach.write(data)attach.close()return attachmentsif __name__ == '__main__':# 账户信息email = 'sunn@nfu.edu.cn'password = 'SUNxxx'pop3_server = 'imap.exmail.qq.com'# 连接到POP3服务器,带SSL的:server = poplib.POP3_SSL(pop3_server)# 可以打开或关闭调试信息:server.set_debuglevel(0)# POP3服务器的欢迎文字:print(server.getwelcome())# 身份认证:server.user(email)server.pass_(password)# stat()返回邮件数量和占用空间:msg_count, msg_size = server.stat()print('message count:', msg_count)print('message size:', msg_size, 'bytes')# b'+OK 237 174238271' list()响应的状态/邮件数量/邮件占用的空间大小resp, mails, octets = server.list()for i in range(1, msg_count):resp, byte_lines, octets = server.retr(i)# 转码str_lines = []for x in byte_lines:str_lines.append(x.decode())# 拼接邮件内容msg_content = '\n'.join(str_lines)# 把邮件内容解析为Message对象msg = Parser().parsestr(msg_content)headers = get_email_headers(msg)attachments = get_email_content(msg, r'/Users/sun/Desktop')print('subject:', headers['Subject'])print('from:', headers['From'])print('to:', headers['To'])if 'cc' in headers:print('cc:', headers['Cc'])print('date:', headers['Date'])print('attachments: ', attachments)print('-----------------------------')server.quit()
这里主要说明2点:
-
对应代码中的69-71行,需要分别改成自己的邮箱、邮箱密码、邮箱对应的收件POP3服务器。

比如,我使用的是腾讯企业邮箱,那么我的pop3_server就是:
a、收件服务器:imap.exmail.qq.com,使用SSL,端口号993b、发件服务器:smtp.exmail.qq.com,使用SSL,端口号465
https://m.dingtalk.com/qidian/help-keyword-4088
-
第二个需要更改的地方就是对应代码的99行,改成你需要保存的文件的本地路径。

经过本人测试,可正常运行程序!
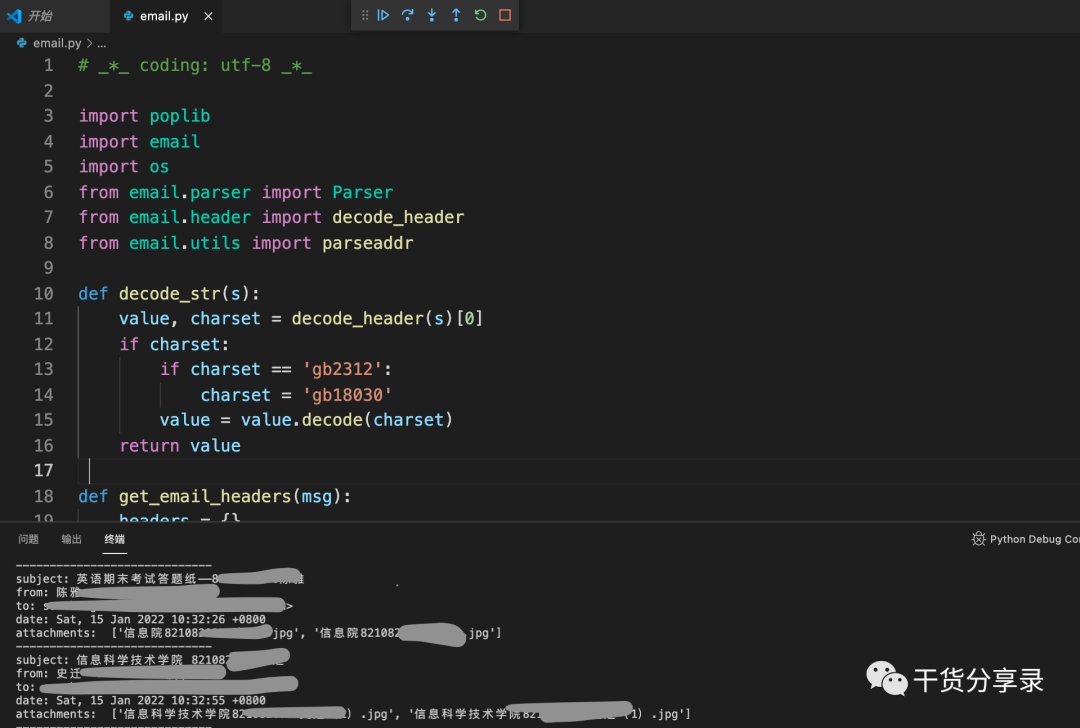
以上如何附件中的文件命名后缀名都是规范的话,不是出现解码出错的问题,但是我下载的附件中我发现有一个.JPG,是大写字母的话好像就无法正确解码。
发生异常: UnicodeDecodeError'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
总结,文件规范命名基本上不会出现这样的下载错误。
最后附上代码的源作者:感谢作者,如有侵权,立刻删!
https://blog.csdn.net/ghostresur/article/details/81875574?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-2.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-2.pc_relevant_default&utm_relevant_index=5大家觉得还不错的话给个小❤️❤️~~~


















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











