







1、Suppose you run a bookstore, and have ratings (1 to 5 stars) of books. Your collaborative filtering algorithm has learned a parameter vector theta(j) for user j, and a feature vector x(i) for each book. You would like to compute the “training error”, meaning the average squared error of your system’s predictions on all the ratings that you have gotten from your users. Which of these are correct ways of doing so (check all that apply)? For this problem, let m be the total number of ratings you have gotten from your users. (Another way of saying this is that 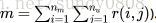
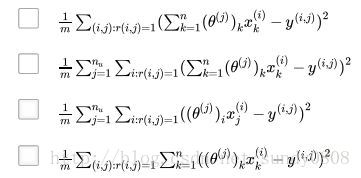
答案:AB
2、In which of the following situations will a collaborative filtering system be the most
appropriate learning algorithm (compared to linear or logistic regression)?
A. You manage an online bookstore and you have the book ratings from many users. For each user, you want to recommend other books she will enjoy, based on her own ratings and the ratings of other users.
B. You run an online news aggregator, and for every user, you know some subset of articles that the user likes and some different subset that the user dislikes. You’d want to use this to find other articles that the user likes.
C. You’ve written a piece of software that has downloaded news articles from many news websites. In your system, you also keep track of which articles you personally like vs. dislike, and the system also stores away features of these articles (e.g., word counts, name of author). Using this information, you want to build a system to try to find additional new articles that you personally will like.
D. You manage an online bookstore and you have the book ratings from many users. You want to learn to predict the expected sales volume (number of books sold) as a function of the average rating of a book.
答案:AB。
C一个人的喜好就不需要这个算法了吧,用logistic regression就好
D这是预测问题,用linear regression
3、You run a movie empire, and want to build a movie recommendation system based
on collaborative filtering. There were three popular review websites (which we’ll call A, B and C) which users to go to rate movies, and you have just acquired all three companies that run these websites. You’d like to merge the three companies’ datasets together to build a single/unified system. On website A, users rank a movie as having 1 through 5 stars. On website B, users rank on a scale of 1 - 10, and decimal values (e.g., 7.5) are allowed. On website C, the ratings are from 1 to 100. You also have enough information to identify users/movies on one website with users/movies on a different
website. Which of the following statements is true?
A. It is not possible to combine these websites’ data. You must build three separate recommendation systems.
B. You can merge the three datasets into one, but you should first normalize each dataset’s ratings (say rescale each dataset’s ratings to a 1-100 range).
C. Assuming that there is at least one movie/user in one database that doesn’t also appear in a second database, there is no sound way to merge the datasets, because of the missing data.
D. You can combine all three training sets into one without any modification and expect high performance from a recommendation system.
答案:B。肯定可以合并啊。只是需要统一scale。
4、Which of the following are true of collaborative filtering systems? Check all that apply.
A. To use collaborative filtering, you need to manually design a feature vector
for every item (e.g., movie) in your dataset, that describes that item’s most important properties.
B. When using gradient descent to train a collaborative filtering system, it is okay to initialize all the parameters (x(i) and theta(j)) to zero.
C. If you have a dataset of users ratings’ on some products, you can use these to predict one user’s preferences on products he has not rated.
D. Recall that the cost function for the content-based recommendation
system is
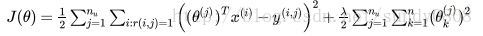
Suppose there is only one user and he has rated every movie in the training set. This implies that nu = 1 and r(i,j)=1 for every i,j. In this case, the cost function is equivalent to the one used for regularized linear regression.
答案:CD。
A错误,不需要,自动学习所有feature
B错误,需要初始化为很小的随机值避免学习参数平衡陷入死循环
C正确
D 正确。linear regression 和content-based recommendation system的cost function最大的不同就是recommendation system少除了一个m,也就是样本个数,当样本数为1的时候,两者自然相等。
5、Suppose you have two matrices A and B, where A is 5x3 andB is 3x5. Their product
is C=AB, a 5x5 matrix. Furthermore, you have a 5x5 matrix R where every entry is 0 or 1. You want to find the sum of all elements C(i,j) for which the corresponding R(i,j) is 1, and ignore all elements C(i,j) where R(i,j)=0. One way to do so is the following code:
C =A*B;
total =0;
for i =1:5
for j = 1:5
if (R(i,j)==1)
total = total + C(i,j);
end
end
endWhich of the following pieces of Octave code will also correctly compute this total?
Check all that apply. Assume all options are in code.
A. total = sum(sum((A * B) .* R))
B. C = A * B; total = sum(sum(C(R == 1)));
C. C = (A * B) * R; total = sum(C(:));
D. total = sum(sum(A(R == 1) * B(R == 1));
答案:AB














 2057
2057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









