






1,SVD
源代码:svd.py
#Ver1.0
#Zero @2012.5.2
#
import math
import random
import cPickle as pickle
#calculate the overall average
def Average(fileName):
fi = open(fileName, 'r')
result = 0.0
cnt = 0
for line in fi:
cnt += 1
arr = line.split()
result += int(arr[2].strip())
return result / cnt
def InerProduct(v1, v2):
result = 0
for i in range(len(v1)):
result += v1[i] * v2[i]
return result
def PredictScore(av, bu, bi, pu, qi):
pScore = av + bu + bi + InerProduct(pu, qi)
if pScore < 1:
pScore = 1
elif pScore > 5:
pScore = 5
return pScore
def SVD(configureFile, testDataFile, trainDataFile, modelSaveFile):
#get the configure
fi = open(configureFile, 'r')
line = fi.readline()
arr = line.split()
averageScore = float(arr[0].strip())
userNum = int(arr[1].strip())
itemNum = int(arr[2].strip())
factorNum = int(arr[3].strip())
learnRate = float(arr[4].strip())
regularization = float(arr[5].strip())
fi.close()
bi = [0.0 for i in range(itemNum)]
bu = [0.0 for i in range(userNum)]
temp = math.sqrt(factorNum)
qi = [[(0.1 * random.random() / temp) for j in range(factorNum)] for i in range(itemNum)]
pu = [[(0.1 * random.random() / temp) for j in range(factorNum)] for i in range(userNum)]
print("initialization end\nstart training\n")
#train model
preRmse = 1000000.0
for step in range(100):
fi = open(trainDataFile, 'r')
for line in fi:
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
score = int(arr[2].strip())
prediction = PredictScore(averageScore, bu[uid], bi[iid], pu[uid], qi[iid])
eui = score - prediction
#update parameters
bu[uid] += learnRate * (eui - regularization * bu[uid])
bi[iid] += learnRate * (eui - regularization * bi[iid])
for k in range(factorNum):
temp = pu[uid][k] #attention here, must save the value of pu before updating
pu[uid][k] += learnRate * (eui * qi[iid][k] - regularization * pu[uid][k])
qi[iid][k] += learnRate * (eui * temp - regularization * qi[iid][k])
fi.close()
#learnRate *= 0.9
curRmse = Validate(testDataFile, averageScore, bu, bi, pu, qi)
print("test_RMSE in step %d: %f" %(step, curRmse))
if curRmse >= preRmse:
break
else:
preRmse = curRmse
#write the model to files
fo = file(modelSaveFile, 'wb')
pickle.dump(bu, fo, True)
pickle.dump(bi, fo, True)
pickle.dump(qi, fo, True)
pickle.dump(pu, fo, True)
fo.close()
print("model generation over")
#validate the model
def Validate(testDataFile, av, bu, bi, pu, qi):
cnt = 0
rmse = 0.0
fi = open(testDataFile, 'r')
for line in fi:
cnt += 1
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
pScore = PredictScore(av, bu[uid], bi[iid], pu[uid], qi[iid])
tScore = int(arr[2].strip())
rmse += (tScore - pScore) * (tScore - pScore)
fi.close()
return math.sqrt(rmse / cnt)
#use the model to make predict
def Predict(configureFile, modelSaveFile, testDataFile, resultSaveFile):
#get parameter
fi = open(configureFile, 'r')
line = fi.readline()
arr = line.split()
averageScore = float(arr[0].strip())
fi.close()
#get model
fi = file(modelSaveFile, 'rb')
bu = pickle.load(fi)
bi = pickle.load(fi)
qi = pickle.load(fi)
pu = pickle.load(fi)
fi.close()
#predict
fi = open(testDataFile, 'r')
fo = open(resultSaveFile, 'w')
for line in fi:
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
pScore = PredictScore(averageScore, bu[uid], bi[iid], pu[uid], qi[iid])
fo.write("%f\n" %pScore)
fi.close()
fo.close()
print("predict over")
if __name__ == '__main__':
configureFile = 'svd.conf'
trainDataFile = 'u1.base'
testDataFile = 'u1.test'
modelSaveFile = 'svd_model.pkl'
resultSaveFile = 'prediction'
#print("%f" %Average("u1.base"))
SVD(configureFile, testDataFile, trainDataFile, modelSaveFile)
#Predict(configureFile, modelSaveFile, testDataFile, resultSaveFile)
配置文件svd.conf:
3.528350 6040 3900 10 0.01 0.05
averageScore userNum itemNum factorNum learnRate regularization 实验结果:
数据集一:movielen(u1.base/u1.test)
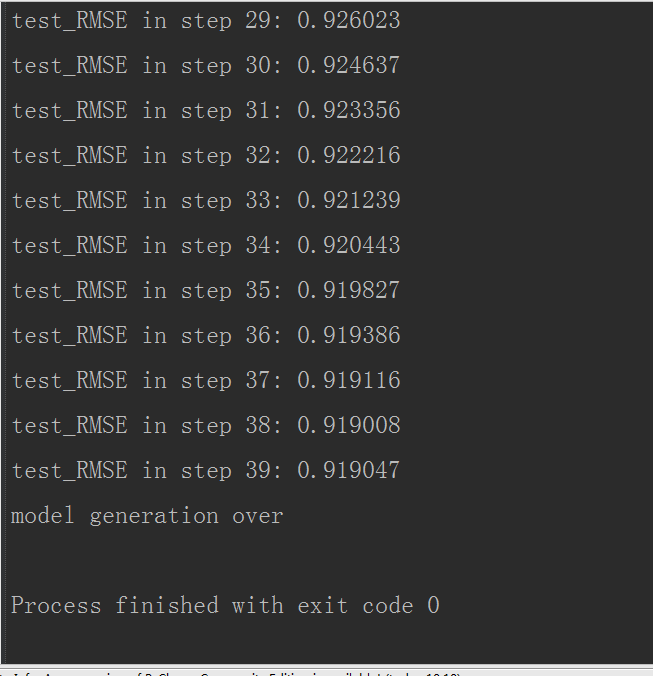
迭代了39次,最终的RMSE=0.919047
数据集二:movielen(u2.base/u2.test)
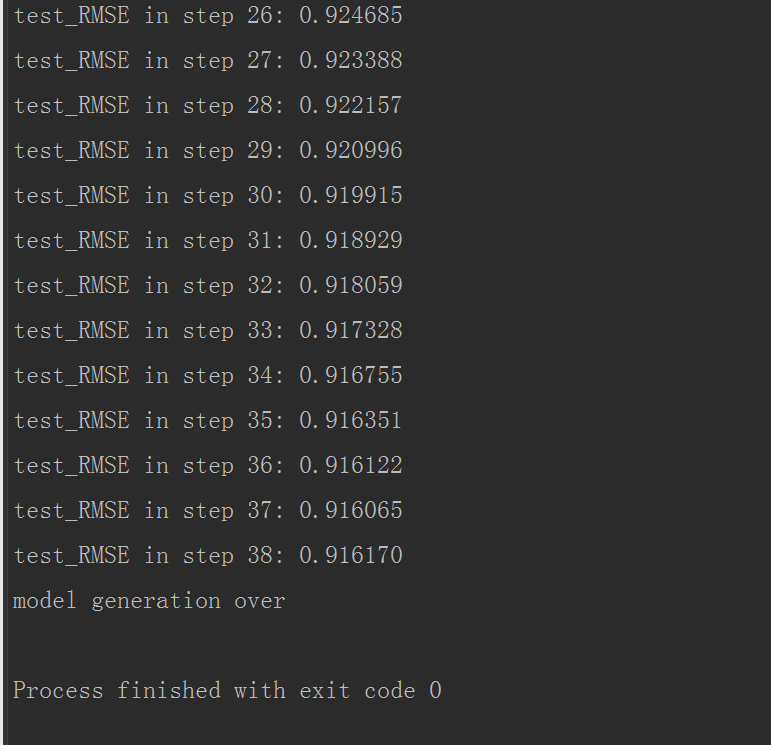
迭代了38次,最终的RMSE=0.916170
注:跑程序之前,记得在SVD.conf中修改

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









