







ECCV 2024 Oral! Meta新发布人体视觉基础模型 Sapiens: Foundation for Human Vision Models!
支持2D 姿态估计、身体部位分割、深度估计和表面法线预测四大任务,性能得到显著提高!

项目链接: https://github.com/facebookresearch/sapiens
论文链接: https://arxiv.org/abs/2408.12569
Huggingface在线运行Demo: https://huggingface.co/collections/facebook/sapiens-66d22047daa6402d565cb2fc
文章目录
介绍了一系列名为 Sapiens 的模型,专注于四个主要的人类视觉任务:2D姿态估计、身体部位分割、深度估计 和 表面法线预测。主要内容可以分为以下几个方面:
1. 研究背景与挑战
近年来,生成逼真的2D和3D人类模型取得了显著进展,但在真实世界(“in-the-wild”)数据中,准确估计如2D关键点、精细的身体分割、深度信息和表面法线依然充满挑战。标注真实数据的难度限制了这些模型的推广。
2. Sapiens模型的特点
Sapiens模型旨在为人类相关的视觉任务提供高性能的统一框架:
通用性:模型具备很强的泛化能力,能在不同场景中表现良好。
高适应性:只需少量微调即可用于特定任务。
高保真度:输出高分辨率、精确的结果,尤其适合人类图像的生成和处理。
3. 预训练和数据集
Sapiens使用一个庞大的数据集进行预训练,称为 Humans-300M,包含3亿张真实世界中的人类图像。这些图像经过过滤以确保质量(去除水印、文本等干扰),并使用自监督预训练方法(如 Masked Autoencoder (MAE))在1K分辨率的图像上进行处理。
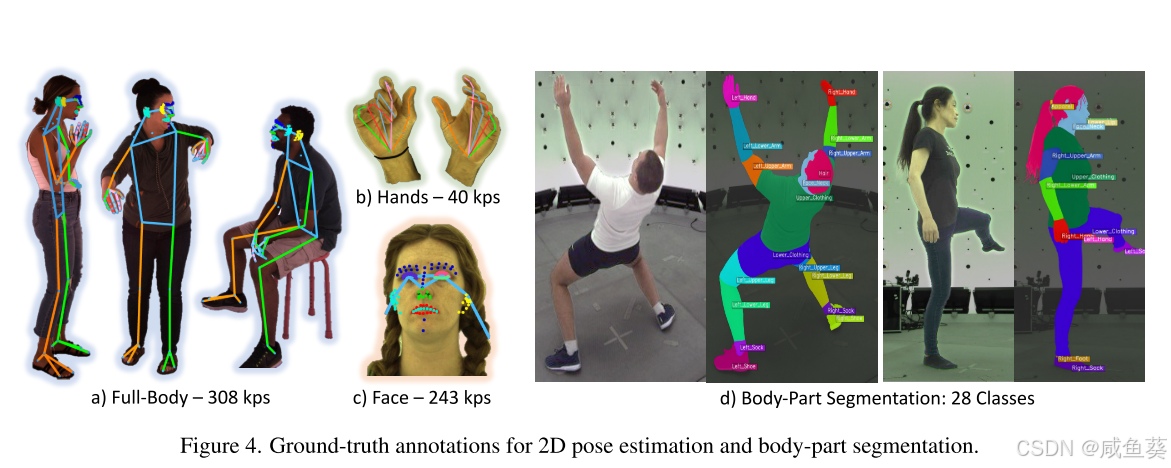

4. 四个主要任务
2D姿态估计:检测人体关键点的位置,改进了现有的骨架系统(增加到308个关键点,包括面部、手部等细节),使得模型在细致程度上有了显著提升。

身体部位分割:通过对身体各部位像素分类,Sapiens在分割类别上增加到了28个,超越了以往的数据集,如精细的嘴唇、牙齿等。

深度估计:通过单张图像预测深度信息,Sapiens模型在真实世界和合成数据上均表现出色。

表面法线预测:预测每个像素的表面法线,用于人类的3D数字化任务。

5. 实验结果
Sapiens模型在多个人类视觉任务基准上取得了显著的性能提升。例如,在 Humans-5K 骨架任务上提升了 7.6 AP,在 Humans-2K 分割任务上提升了 17.1 mIoU,在 Hi4D 数据集的深度任务上相对RMSE降低了22.4%,在 THuman2 数据集上的法线任务相对角度误差降低了53.5%。
6. 模型规模和性能
Sapiens模型通过增加参数规模(从0.3B到2B参数),显示出模型大小与性能的直接关联。最大规模的模型 Sapiens-2B 展现了最高的精度,尤其在推理分辨率达到1K的情况下,实现了更高的图像质量。
7. 结论
Sapiens模型的研究表明,通过对大规模、高质量的真实世界人类图像进行预训练,能够在多个下游任务中达到先进水平。Sapiens模型为未来的3D和多模态任务奠定了基础。
这篇论文的创新点包括对 人类相关任务的专注预训练、高分辨率处理 和 模型的可扩展性,并在多个baseline上取得了显著的突破。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









