






这里写目录标题
项目相关资源:
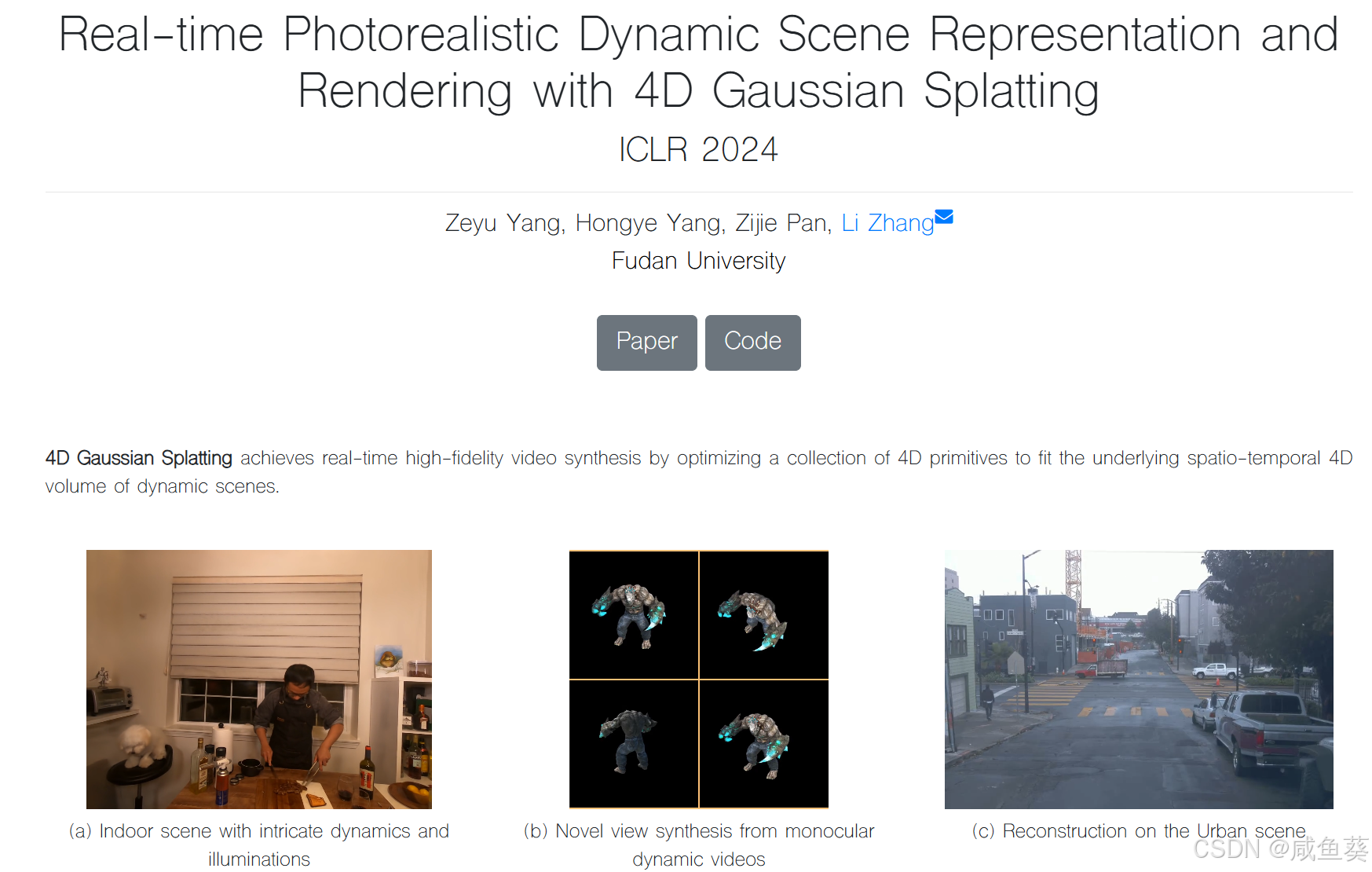
Real-time Photorealistic Dynamic Scene Representation and Rendering with 4D Gaussian Splatting
简介
4D Gaussian Splatting (4DGS) 是由复旦大学团队提出的一种高效动态场景建模与渲染技术,已发表在 ICLR 2024。它在实时动态场景渲染领域取得了革命性突破,解决了传统方法难以应对动态场景的复杂性和实时性问题。
主要特点:
- 动态场景建模:使用4D高斯原语(包含时间维度)统一表示时空特性。
- 实时高效渲染:结合GPU友好的光栅化方法,实现了每秒114帧的实时渲染速度。
- 高质量视觉效果:生成复杂动态场景中的高保真图像和视频。
核心创新:
- 4D高斯建模:通过联合参数化空间和时间维度捕获动态场景本质特性。
- 4D球柱谐函数:建模时间和视角依赖的外观变化,适应动态光影效果。
- 端到端训练:支持全流程训练和任意时间点的高效渲染。
应用场景:
- AR/VR:实时动态场景交互。
- 影视制作:动态场景的真实感建模。
- 机器人与自动驾驶:用于动态环境的感知与决策。
论文解读
1. 背景
-
任务定义:
- 重建动态三维场景并生成任意时间的多视角图像,是计算机视觉和图形学领域的重要任务,广泛应用于AR/VR。
- 现有方法在静态场景渲染上(如NeRF)取得显著成果,但在动态场景中,物体运动和时间动态性增加了复杂性。
-
现存问题:
- 6D全光函数直接建模动态场景时存在时空结构不足的问题。
- 对场景运动或形变的显式建模在复杂场景下难以扩展。
2. 贡献
- 提出了一种以4D高斯为核心的动态场景建模方法:
- 通过优化一组4D高斯原语,统一建模动态场景的时空特性。
- 支持任意时间点的视角合成。
- 提出了新的时间与空间联合表示:
- 使用4D旋转捕获动态场景的本质运动。
- 引入4D球柱谐函数(4D Spherindrical Harmonics)表示时间和视角依赖的颜色变化。
- 在多种基准数据集上实现了实时、高质量的动态场景渲染,显著提升了性能。
3. 创新点
-
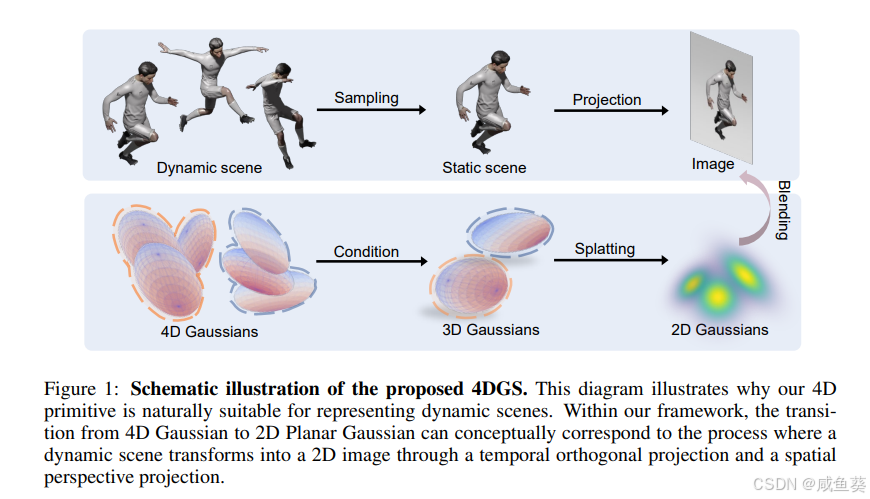
4D高斯建模:
- 动态场景被视为4D时空体,使用4D高斯(包含时间分量)表示几何和外观。
- 引入4D旋转矩阵参数化高斯的协方差矩阵,从而支持时空统一优化。
-
时间演化外观建模:
- 使用4D球柱谐函数建模颜色的时间演化和视角变化。
- 结合傅里叶级数和球谐函数,保证计算效率。
-
实时性:
- 结合GPU友好的光栅化方法和稀疏高斯密度控制,优化了渲染效率。
4.方法介绍
-
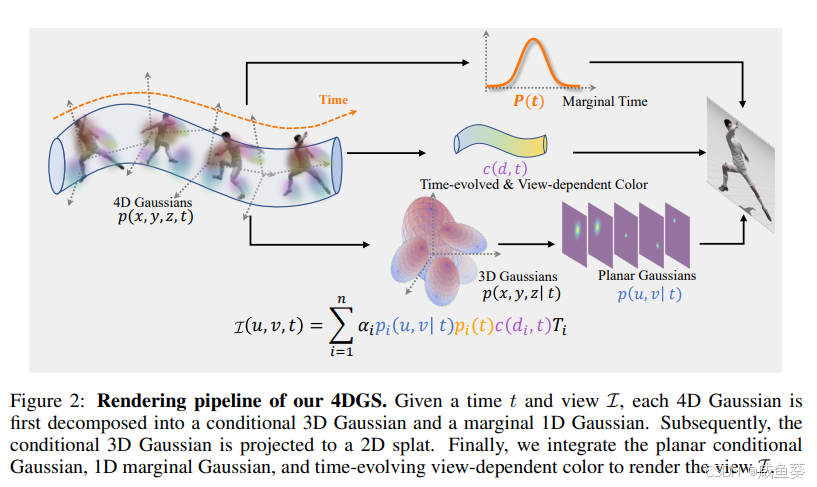
核心概念:
- 场景由一组4D高斯原语表示,每个高斯由位置、协方差矩阵和时间依赖的外观系数表示。
- 渲染时,通过条件分布投影到2D平面。
-
优化流程:
- 端到端训练,通过渲染损失监督优化。
- 实施动态的高斯稠密化与稀疏化,以自适应场景变化。
-
4D高斯参数化:
- 均值向量包含三维空间位置和时间维度。
- 协方差矩阵包含空间和时间的联合旋转和缩放参数,增强了动态运动的建模能力。
-
训练策略:
- 跨时间批量采样优化,避免时序抖动。
- 在时间维度上引入高斯分裂控制,改善密度分布。
5. 实验结果
- 数据集:
- Plenoptic Video(多视图真实场景)。
- D-NeRF(单视图合成场景)。
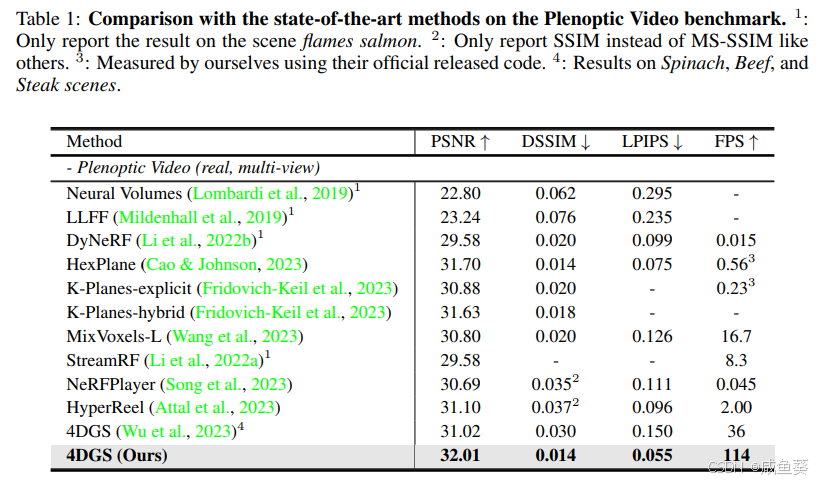
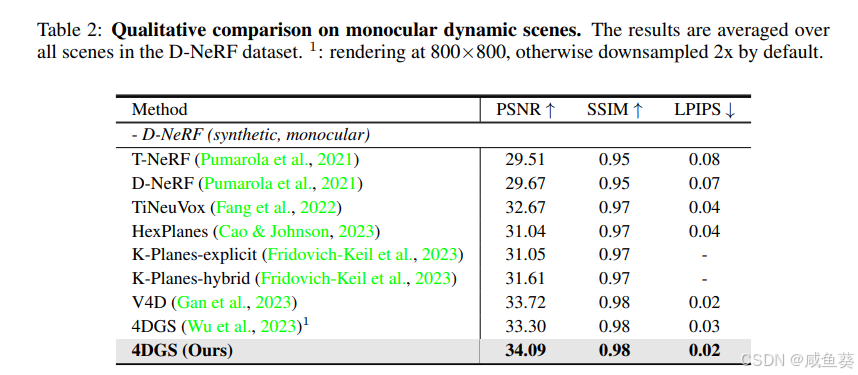
- 性能对比:
- 在Plenoptic Video数据集上,PSNR达到32.01,比现有方法更高,同时渲染速度远超实时(114 FPS)。
- 在D-NeRF数据集上,PSNR达到34.09,同样优于所有对比方法。
- 定性结果:
- 合成结果保留了动态区域的精细细节,如火焰纹理和运动中的手指。
- 对光影和体积效果有良好表现。


总结
1. 优点
- 高质量和高效率:
- 渲染速度显著优于现有方法,可实时生成高保真动态视频。
- 统一的时空建模:
- 消除了时间与空间独立建模的局限性,能够捕获复杂的场景运动。
- 易用性:
- 方法简单、模块化,可直接应用于不同类型的动态场景。
2. 局限性
- 背景场景建模的不足:
- 在远背景区域,尤其是初始点云稀疏时,容易出现欠拟合现象。
- 对初始数据的依赖:
- 静态和动态部分需要初始点云的较高质量输入。
- 在极端动态场景中的表现:
- 对快速复杂运动的处理仍有提升空间,可能需要更高的时间采样密度。
实验记录
https://github.com/fudan-zvg/4d-gaussian-splatting?tab=readme-ov-file#environment
参阅这个进行实验配置
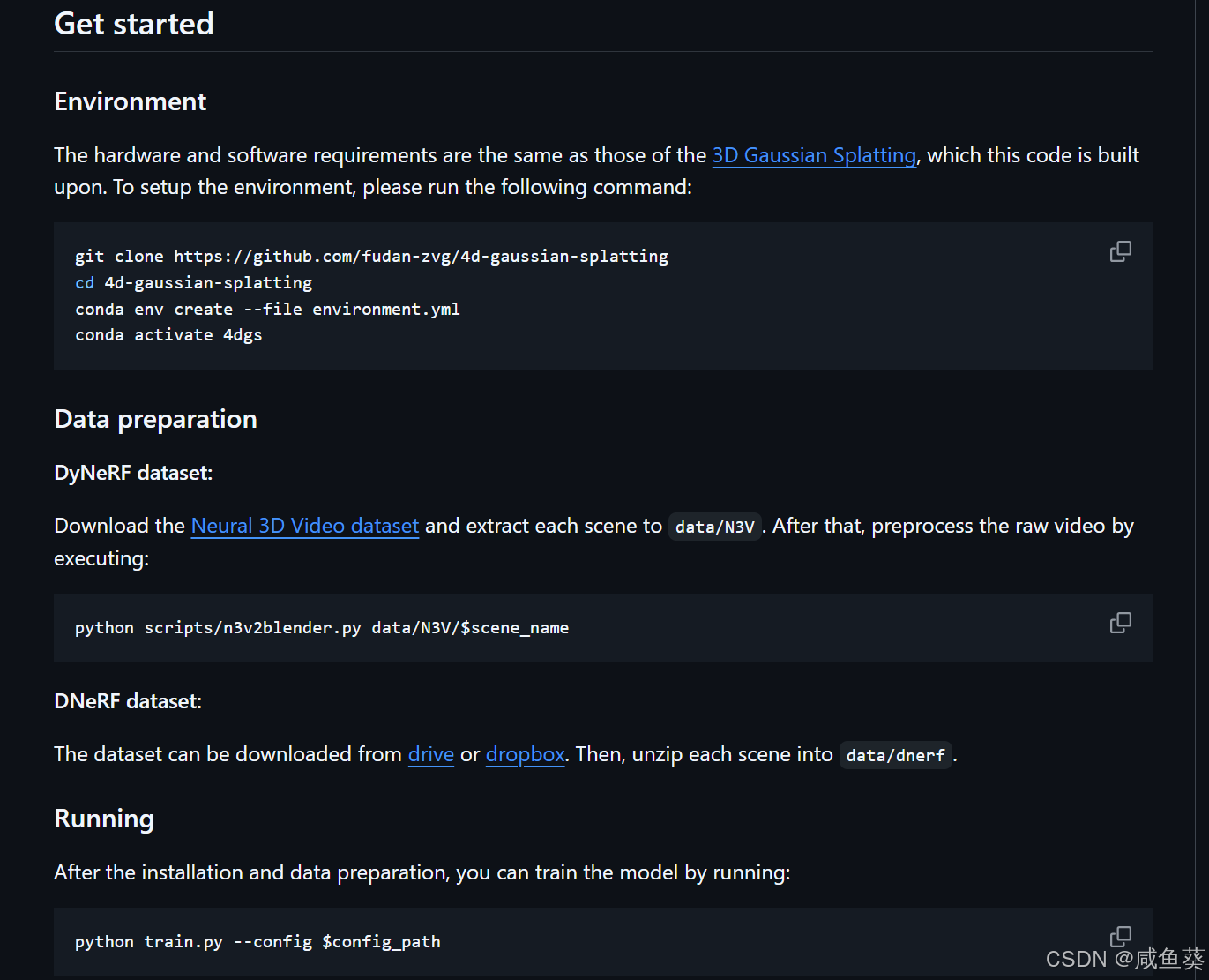
Get started
Environment
The hardware and software requirements are the same as those of the 3D Gaussian Splatting, which this code is built upon. To setup the environment, please run the following command:
git clone https://github.com/fudan-zvg/4d-gaussian-splatting
cd 4d-gaussian-splatting
conda env create --file environment.yml
conda activate 4dgs
Data preparation
DyNeRF dataset:
Download the Neural 3D Video dataset and extract each scene to data/N3V. After that, preprocess the raw video by executing:
python scripts/n3v2blender.py data/N3V/$scene_name
DNeRF dataset:
The dataset can be downloaded from drive or dropbox. Then, unzip each scene into data/dnerf.
Running
After the installation and data preparation, you can train the model by running:
python train.py --config $config_path
实验复现
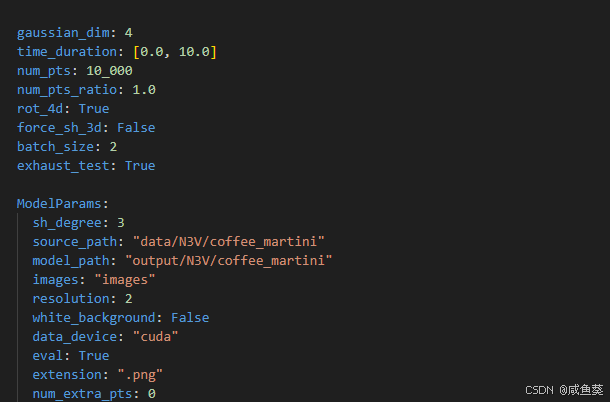
拿coffee_martini举例
首先借助chatgpt安装好其他需要的环境(上面没提到的),主要是openh264
然后正常运行
python train.py --config configs/dynerf/coffee_martini.yaml
可以在configs/dynerf/coffee_martini.yaml里进行实验设置的修改,比如我这里为了加快实验显示,修改了点的数量30_000–>10_000
还有batch_size从4改到了2
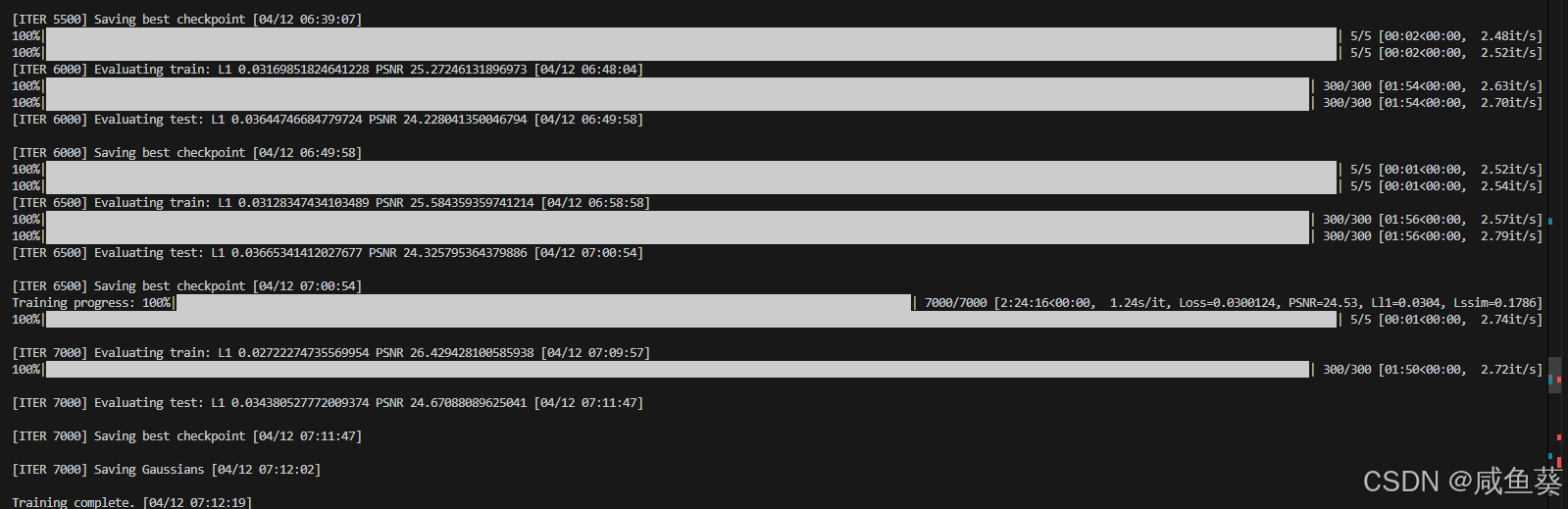
得到结果chkpnt_best.pth 还有 chkpnt_7000.pth
对于可视化结果问题,可以参考这个https://github.com/fudan-zvg/4d-gaussian-splatting/issues/12
就是运行
python render.py --model_path output/N3V/coffee_martini/ --loaded_pth=output/N3V/coffee_martini/chkpnt_best.pth
然后等待结果

下面是渲染结果和GT对比
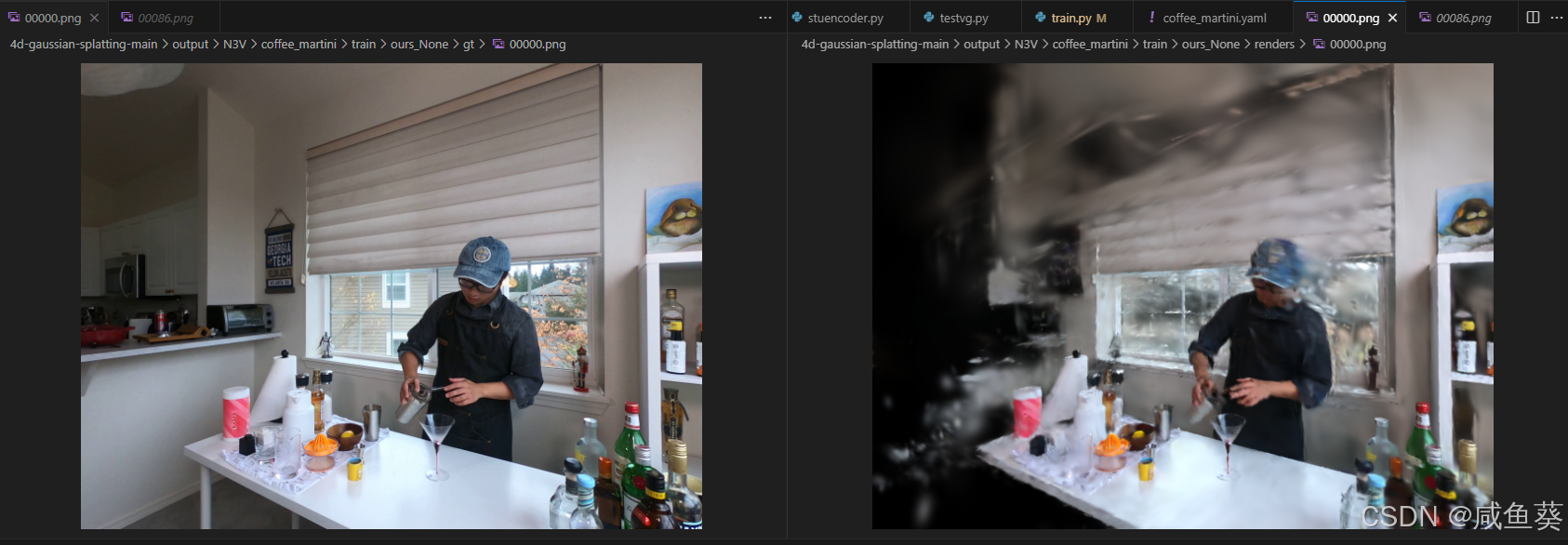
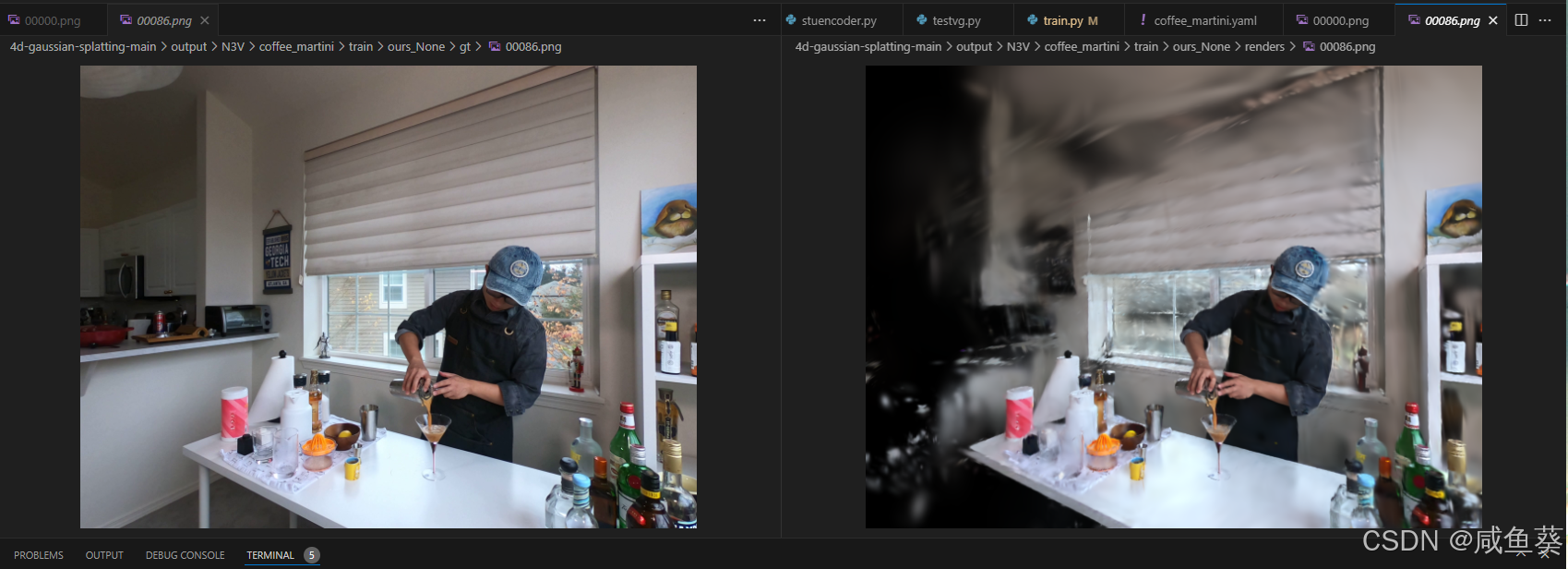
总结
4D Gaussian Splatting 为动态场景建模和渲染提供了一种全新的解决方案,结合高效率和高质量的特点,在多领域具有广阔的应用前景。


















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









