







问题:根据学生的百分制成绩计算5级分制成绩,成绩在5个等级上的分布规律:
| 分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
| 所占比例 | 5% | 15% | 40% | 30% | 10% |
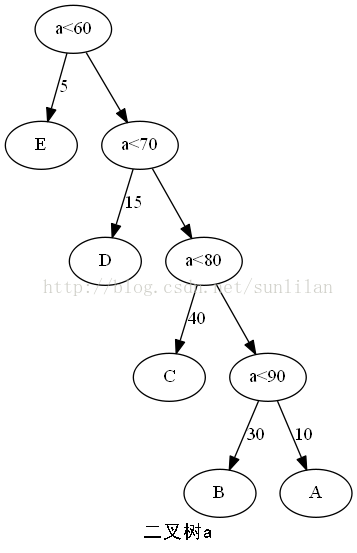
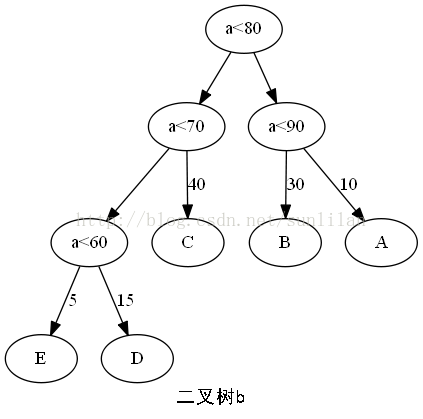
树的路径长度是从树根到每一个结点的路径长度之和。
二叉树a的树的路径长度:1+1+2+2+3+3+4+4=20
二叉树b的树的路径长度:1+2+3+3+2+1+2+2=16
结点的带权路径长度:从树根到该结点的路径长度与结点上权的乘积
树的带权路径长度(WPL):树中所有叶子结点的带权路径长度之和。
WPL最小的二叉树称为赫夫曼树
二叉树a的WPL:5×1+15×2+40×3+30×4+10×4=315
二叉树b的WPL:5×3+15×3+40×2+30×2+10×2=220
这意味着如果有10000个学生的百分制成绩需要计算五级分制成绩,用二叉树a的判断方法,需要31500次比较,而二叉树b的判断方法需要22000次比较。
那么二叉树b是最优的吗?赫夫曼树是如何建立的?
构造赫夫曼树的算法:
1.根据给定的n个权值{w1,w2,w3···wn}构成n棵二叉树的集合F={T1,T2···Tn},其中每个二叉树Ti中只有一个带权为Wi的根节点,左右子树均为空。
2.在F中选取两棵根节点权值最小的树作为左右子树构造一棵新的二叉树,置二叉树的根节点的权值为左右子树上根节点的权值之和。
3.在F中删除这两棵树,同时将新得到的二叉树加入F中。
4.重复2和3步骤,直到F中只含一棵树为止。这棵树是赫夫曼树。
以上面的问题为例。
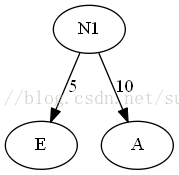
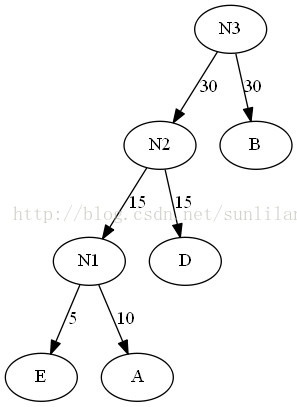
1.列出有权值的叶子结点,排序。E5,A10,D15,B30,C40
2.选出头两个最小权值的结点作为新结点的子结点,注意相对较小的是左结点。新结点的权值为两个子结点的权值之和。
3.将N1插入有序序列中,删除A和E。即N1(15),D15,B30,C40
4.重复2。
5.将N2插入有序序列中,删除N1和D。即N2(30),B30,C40
6.重复2。
7.将N2插入有序序列中,删除N2和B。即C40,N3(60)
8.重复2。
9.将N4插入有序序列,删除C和N3。此时序列中只含一棵树,该树就是赫夫曼树。
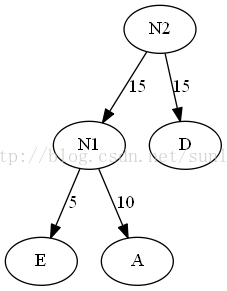
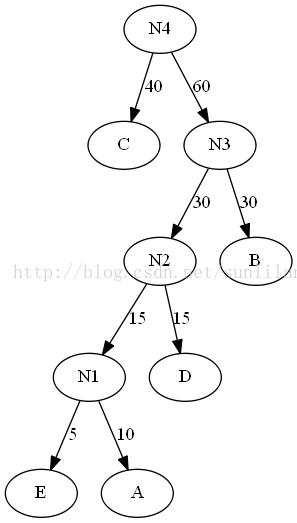
计算这棵树的WPL:40×1+5×4+10×4+15×3+30×2=205。与之前的二叉树b的220相比还要小。
不过现实比理想复杂,该赫夫曼树每次判断都要两次比较,比如N4判断的是a<80&&a>=70,所以总体性能上反而不如二叉树b。不过这不是我们讨论的重点了。
赫夫曼编码
当初研究这种最优树并不是为了转化成绩的,而是解决远距离通信的数据传输的最优化问题。
假设我们要传递的文字只有6个字母A、B、C、D、E、F。可以按照下表进行编码。
| 字母 | A | B | C | D | E | F |
| 二进制字符 | 000 | 001 | 010 | 011 | 100 | 101 |
假设六个字母的频率为A27,B8,C15,D15,E30,F5,合起来是100%。按照赫夫曼树来规划。
将树的左分支的权值改为0,右分支改为1。
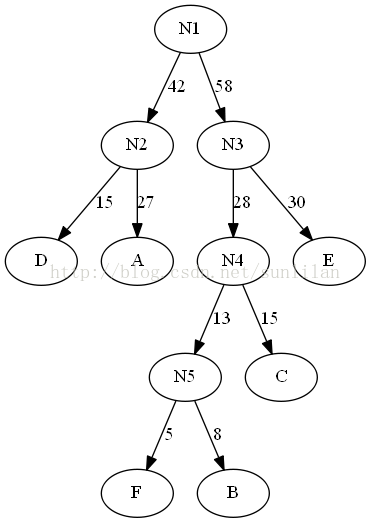
可以得到新的编码规则。

| 字母 | A | B | C | D | E | F |
| 二进制字符 | 01 | 1001 | 101 | 00 | 11 | 1000 |
对文字内容BADCADFEED编码
原编码二进制串:001000011010000011101100100011
新编码二进制串:1001010010101001000111100
所以数据被压缩了
解码的时候还要用到赫夫曼树,即发送方和接收方必须约定好同样的赫夫曼编码规则。
若要设计长短不等的编码,则必须任一个字符的编码都不是另一个字符的编码的前缀,这种编码称为前缀编码。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









