







文章目录
摘要
- 深度学习方面,学习了kaggle竞赛的一些处理问题的方法、技巧。(未完)
- 文献方面,阅读了Transformer;在Transformer中,采用了位置编码+多头注意力机制,前者使用绝对位置信息代替了RNN中的时序信息,后者使得model能够更好的从数据中抓住有效信息,两者结合,使得model在处理时序信息时,能够并行化,相比RNN,Transformer训练速度更快且上限更高,但若参数设置的不够好,也会导致Transformer没法抓住很好的时序信息,使得其不如RNN。
- 项目方面:学习了区块链中,重点使用的docker容器技术;docker容器技术类似于虚拟机,但其使用了容器技术,可以将环境一块打包成镜像文件,且其可以调用已经存在的文件,避免了数据冗余,使得其镜像文件更小。
- 毕设方面: 指导学弟安装好了超级账本环境,指明了学习方向,并开始了学习;
一、深度学习:Kaggle竞赛
1.1 model的选择

1.2 常用包
- scikit-learn包:包中基本上所有model都有,只需要简单调用就可使用;例如:处理好输入x,label后,fit(x,label)就可完成训练;
- grnsim:自然语言处理包;可将word转变为vector;
- pandas:数据处理的包;
- matplotlib:绘图包;
1.3 解决问题流程
- 了解问题的场景及我们的目的
- 了解问题的评估准则
- 认知数据
- 数据预处理
- 特征工程
- 模型调参
- 模型状态分析
- 模型融合
注意:数据处理(特征工程,清洗等)>模型,只要数据处理做的足够好,简单的model也能达到很好的效果,且model可解释性非常高。
1.3.1 认知数据
- 数据质量分析
二、文献:Transformer
2.1 摘要
主流的序列转换模型是基于复杂的循环或卷积神经网络,包括编码器和解码器。性能最好的模型还通过注意机制连接编码器和解码器。我们提出了一种新的简单网络架构—Transformer,它完全基于注意力机制,摒弃了递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优,同时具有更强的并行性,需要的训练时间显著减少。我们的模型在WMT 2014英德翻译任务中获得28.4个BLEU,比现有的最佳结果(包括集合)提高了2个BLEU。在WMT 2014英法翻译任务中,我们的模型在8个gpu上经过3.5天的训练后,建立了一个新的单模最先进的BLEU得分为41.8,这只是文献中最好的模型训练成本的一小部分。我们通过将Transformer成功地应用于具有大量和有限训练数据的英语分组解析,表明它可以很好地推广到其他任务。
2.2 介绍
RNN特别是LSTM作为主流的序列建模已经是公认的了,但是存在以下缺点:
- 数据必须是按顺序输入,限制了训练的并行化,训练速度慢;
- 当时序比较长时,很早的时序信息会被遗忘;于是作者提出了完全基于注意力机制的model—tramsformer,无顺序约束,训练速度快,效果也好。
注意力机制
2.3 Transformer架构
2.3.1 全局分析Transformer
- transformer被发明的时候是用来做机器翻译的,从全局角度看如下图;

- TRM可分为两个部分,encoder模块、decoder模块;

- 其中encoder模块都是由n个encoder组成,decoder模块是由n个decoder组成;

- 其中每个encoder和decoder是怎样的?(如下图)
左边是encoder模块,右边是decoder模块,运行顺序从1-2-3…,E表示encoder,D表示decoder,2`等表示残差。

2.3.2 细分Transformer
encoder里面是什么东西呢?
分为三个部分,1-输入部分;2-多头注意力机制部分;3-前馈神经网络。

- 输入部分:分为两个小两部分:

第一部分:Input Embedding对输入的word进行编码,将其转换为vector;
第二部分:Positional Encoding—位置编码,该部分利用位置编码,替代找出输入的时序信息,运用的是sin-cos编码,公式如下图:
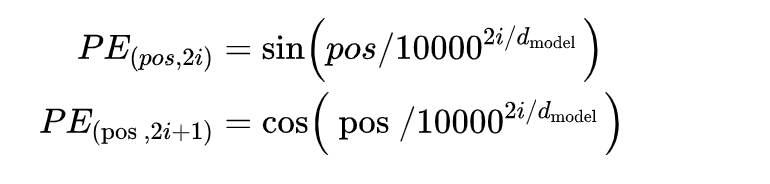
上式中pos指的是句中字的位置,取值范围是[0, 𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ),i指的是字嵌入的维度, 取值范围是[0, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛)。 就是𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛的大小。
第一部分+第二部分得到的数据作为最终的输入; - 多头注意力机制:公式如下:
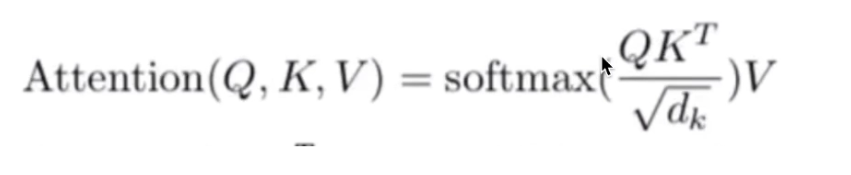
其中Q、K、V是怎么来的呢?以翻译为例:

上图的输入是一个单词,而实际操作中,可输入多个单词,并行训练,如下图:

目前使用的参数只是一套参数,只能叫做单头注意力机制,我们可以使用多套参数,作者实验这样效果很好,可以认为多套参数将数据映射到不同的空间,从而更多的保存了数据中的信息(以两套为例如下图):

- 前馈神经网络:前馈神经网络没什么好说的,一般就是RELU层;
注意:每一层都有残差连接;
Decoder里面是什么东西呢?
Decoder与Encoder有很多相似的地方,不同的地方有两部分,如下图:

4. mask多头注意力机制,为什么需要mask,在Transformer中,由于用注意力代替了时序信息,若在训练时,不加mask,那么会导致其在训练时,能看到未来的数据,如下图:

故需要加mask,使得未来数据的权重为0:

5. Encoder中与Decoder交互的多头注意力层:
所有Encoder的输出和每个Decoder进行交互;具体是如何交互呢?Encoder生成K、V矩阵,Decoder生成的Q矩阵(如下图),和前面一样,三者用多头注意力公式得到结果:

2.4 总结
在Transformer中,采用了位置编码+多头注意力机制,前者使用绝对位置信息代替了RNN中的时序信息,后者使得model能够更好的从数据中抓住有效信息,两者结合,使得model在处理时序信息时,能够并行化,相比RNN,Transformer训练速度更快且上限更高,但若参数设置的不够好,也会导致Transformer没法抓住很好的时序信息,使得其不如RNN。
三、项目:Docker容器技术
为了方便复习,这块写在另一篇笔记中。
Docker容器技术















 5556
5556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









