







spark运行模式
1、application program组成
Job:包含多个Task 组成的并行计算,跟Spark action对应
Stage:Job 的调度单位,对应于TaskSet
Taskset:一组关联的、相互之间没有shuffle 依赖关系的任务组成的任务集
Task:被送到某个executor 上的工作单元

2、运行流程(以standalone为例)

程序提交,spark driver内部RDD graph形成RDd相关联图,提交job到DAG scheduler,DAG scheduler将stage分片成taskset提交到spark worker node的Task Threads,由task thread执行tast任务,block manager监控数据块信息。

DAGScheduler:构建Stage—碰到shuffle就split,记录哪个RDD 或者Stage 输出被物化,重新提交shuffle 输出丢失的stage,将Taskset 传给底层调度器spark-cluster TaskScheduler
yarn-cluster YarnClusterScheduler,yarn-client YarnClientClusterScheduler
TaskScheduler:为每一个TaskSet 构建一个TaskSetManager 实例管理这个TaskSet 的生命周期,数据本地性决定每个Task 最佳位置(process-local, node-local, rack-local and then and any),提交taskset( 一组task) 到集群运行并监控,推测执行,碰到straggle 任务放到别的节点上重试,出现shuffle 输出lost 要报告fetch failed 错误。
ScheduleBacked:实现与底层资源调度系统的交互(YARN,mesos等),配合TaskScheduler实现具体任务执行所需的资源分配(核心接口receiveOffers)

3、运行模式

4、standalone运行模式

首先,worker向master注册,然后app向master申请资源如cpu数等。Master启动worker上的executor,准备好后app提交task到worker。


1)集群配置
slaves–指定在哪些节点上运行worker
spark-defaults.conf—spark提交job时的默认配置
spark-env.sh—spark的环境变量
2)提交
./bin/spark-submit --master spark://client:7077 --class org.apache.spark.examples.SparkPi lib/spark-examples-1.6.1-hadoop2.6.0.jar
3)HA
Standby masters with Zookeeper
./start-all.sh启动后,再选择一个节点启动master,./start-master.sh
Single-Node Recover with Local File System
5、Local模式
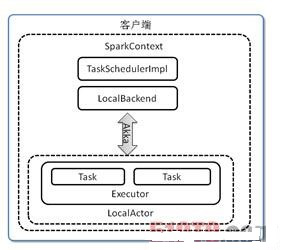
Local,本地模式,默认情况是本地模式运行,如运行的spark-shell。LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值[N]直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现
6、local cluster模式

伪分布式模式启动两个Worker,每个Worker管理两个CPU核和1024MB的内存。LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值[N]直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现
7、spark on yarn
安装配置:配置HADOOP_CONF_DIR或者YARN_CONF_DIR环境变量,让Spark知道Yarn的配置信息。有三种方式:
配置在spark-env.sh中,在提交Spark应用之前export,配置到操作系统的环境变量中
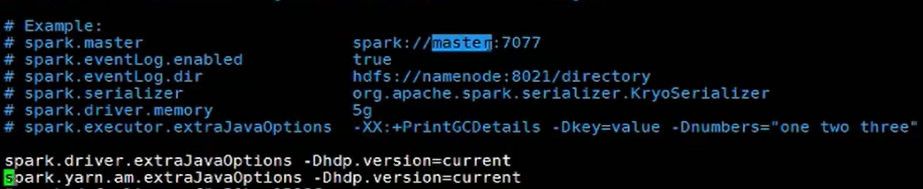
如果使用的是HDP,请在spark-defaults.conf中加入:
spark.driver.extraJavaOptions -Dhdp.version=current
spark.yarn.am.extraJavaOptions -Dhdp.version=current
运行:登陆安装Spark那台机器,./spark-shell --master yarn
提交作业:./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]
例子:
./spark-submit --master yarn --class com.dajiangtai.spark.MyWordCout ~/learning-saprk-1.0-SNAPSHOT.jar /tmp/test /tmp/output
架构:1)Yarn standalone/yarn cluster
调度器是yarn-cluster(YarnClusterScheduler),Driver和AM运行在起,Client单独的
./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]

Spark Driver首选作为一个ApplicationMaster在Yarn集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,
由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能再客户端显示(可以在history server中查看)

2)Yarn client
调度器:yarn-client(YarnClientClusterScheduler)
Client和Driver运行在一起(运行在本地),AM只用来管理资源
./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode client [options] [app options]

Spark driver和client在本地。在Yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个
8、其他配置
环境变量:
spark-env.sh
spark.yarn.appMasterEnv.[EnvironmentVariableName]
配置:–conf PROP=VALUE,为单独的app指定个性化参数


特别注意
在cluster mode下,yarn.nodemanager.local-dirs对 Spark executors 和Spark driver都管用, spark.local.dir将被忽略
在client mode下, Spark executors 使用yarn.nodemanager.local-dirs, Spark driver使用spark.local.dir
–files and –archives支持用#映射到hdfs
–jars
spark-submit























 2398
2398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









