







ACL2020_Improving Low-Resource Named Entity Recognition using Joint Sentence and Token Labeling
论文
Abstract
因为token级标签的标注成本很高,所以利用易于获取的句子级标签是改进低资源命名实体识别(NER)的可行方法之一。现有的句子和token标签联合学习模型仅限于二分类。这篇论文的亮点主要是提出了一个支持多分类的联合模型,并对attention机制进行了探究实验,发现使用自学习的比例因子效果更好。与基线模型BiLSTM-CRF 相比,本文的模型在电子商务产品标题(三种不同的低资源语言:越南语、泰语和印度尼西亚语)上,F1值均有提升。
Introduction
在这篇论文中将多任务学习和预训练结合起来,利用具有足够多标记数据的辅助任务的训练信号。
引用文本
多任务学习是一种归纳迁移机制,主要目标是利用隐含在多个相关任务的训练信号中的特定领域信息来提高泛化能力,多任务学习通过使用共享表示并行训练多个任务来完成这一目标。本文的工作目标是利用辅助任务即句子分类来创建预先训练的表示并作为正则化器来提高主任务NER的性能。
这篇论文的工作目标是利用辅助任务(句子分类)来创建预先训练的表示并作为正则化器来提高主任务(NER)的性能。
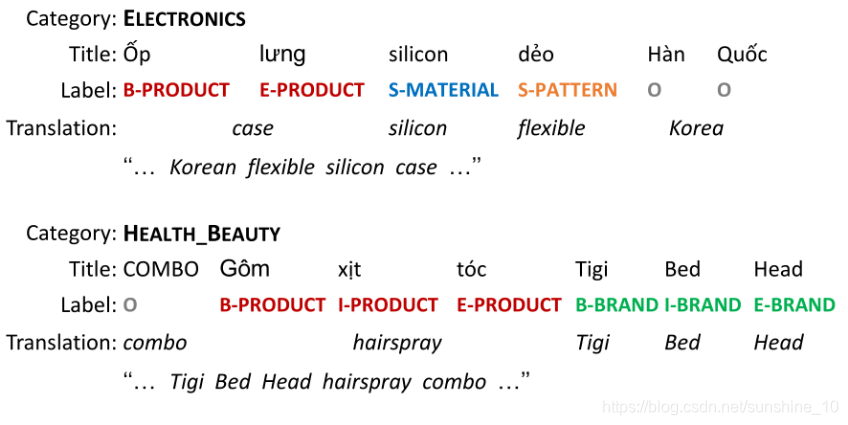
上图显示了越南语电子商务网站上的产品名称示例。虽然带NER标注的产品名称是有限的,但是卖家标注的产品类别(如电子产品)的产品名称非常丰富,可以用来训练句子级分类器。一个关键的挑战是将有用的训练信号从句子级分类传递到词级别NER。
Joint learning framework for multi-class classification
下图是联合句子和token标注模型的体系结构。
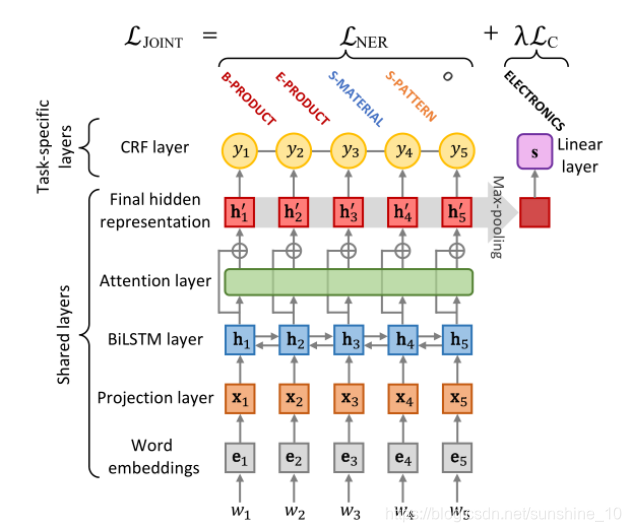
联合模型是基于hard parameter共享,其中隐藏层在两个任务之间共享。特定任务的层包括用于NER的条件随机场(CRF)层和用于句子分类的线性层。Attention layer是可选的,可以跳过或替换为所需的方法。不像标准的MTL,它同时训练多个任务,并期望模型在所有任务上表现良好,工作的目的是使用辅助任务(句子分类)和pre-trained来改善主要任务(NER)的性能。
Shared layers

可直接将隐藏状态序列H用于NER或句子分类,也可以加入attention帮助模型聚焦于特定的标签。
Sentence classification
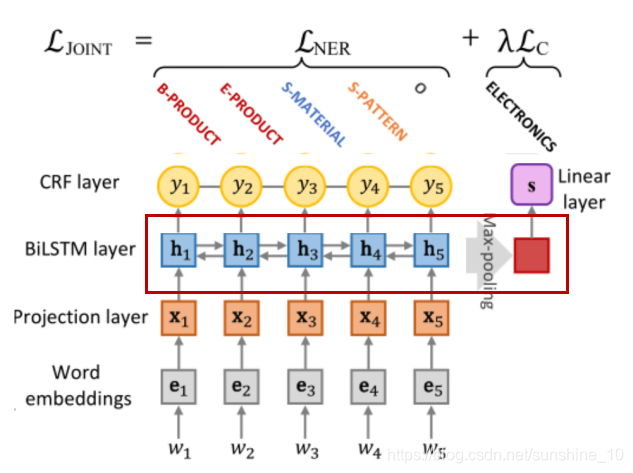
将隐藏状态序列H直接用于句子分类任务,在H上用最大池化来创建一个固定大小的向量,让模型可以捕捉到隐藏状态编码中最有用的局部特征,将固定大小的向量输入到线性层,得到每个类别的非归一化预测分数。文中不仅对句子分类模型和NER模型进行联合训练,而且使用足够多的到标签的样本对句子分类模型进行预训练。
设K为类别数量,Sk是经过SoftMax函数后第k个归一化 预测分数,t∈RK是one-hot编码的true标签。训练句子分类模型,使多类交叉熵最小化:
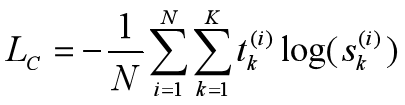
其中i是句子索引,N是训练示例的数量。
NER
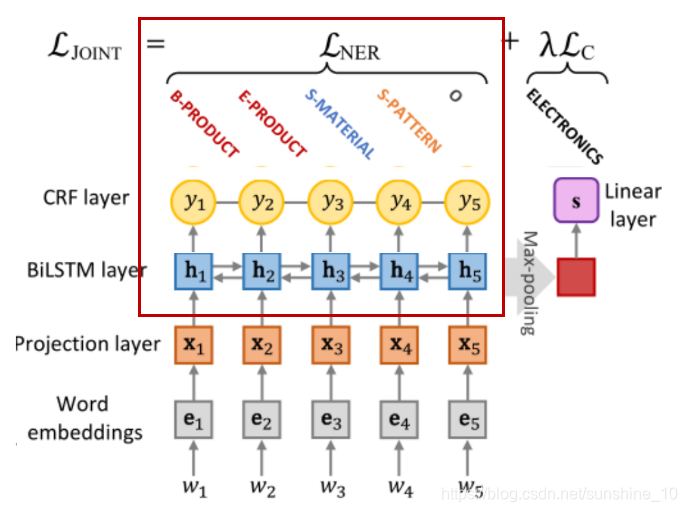
将隐藏层状态序列H输入到CRF层得到标签序列y的概率。
训练NER模型,将训练集上正确的标签序列的负对数似然最小化:
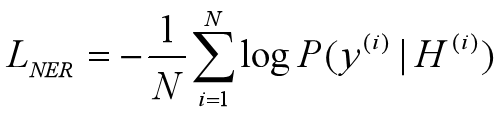
联合模型的损失函数:
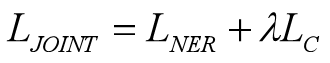
其中λ为平衡参数,LC作为正则项防止主要任务NER过拟合。
Revisiting attention mechanisms
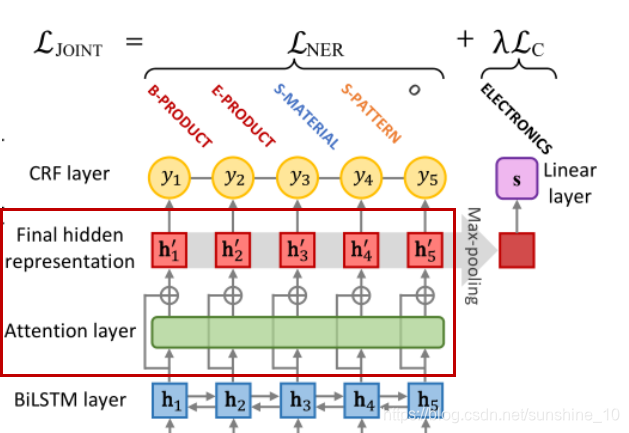
因为句子中token上的注意分布α∈RT是根据最终的隐藏表示H来计算的,而没有考虑隐藏状态之间的关系,因此加attention是有效的。最终的表示如下所示:
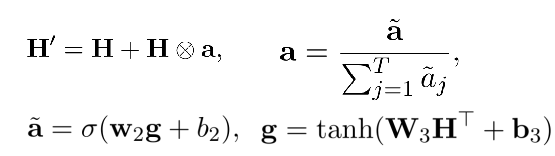
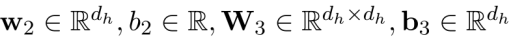
其中,⊗表示按列进行的矩阵-向量乘法。
为了进一步探讨了考虑隐藏状态之间关系的注意机制,本文引入了Transformer里面的多头注意力机制。
将公式变为:
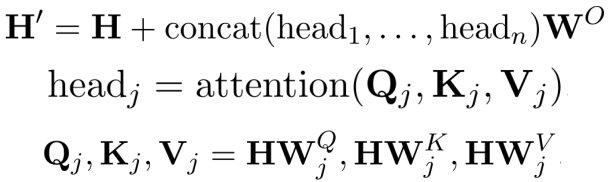
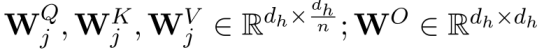
其中,n为平行头的数量。
一般来说attention的操作如下所示: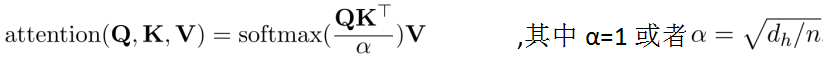
在本研究中,将比例因子α视为softmax temperature,该temperature允许调整softmax输出的概率分布。使用更高的temperature会产生更soft的注意力分布。但是,更sharp的注意力分布可能更适合NER,因为句子中只有几个token被命名为实体。
本文建议学习每个token的比例因子δ∈RT,将attention修改为:
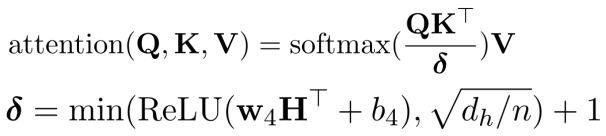
这使得模型能够动态地适应δ,而不增加太多的计算成本。
Experiments
Datasets
实验中使用的数据是2019年5-6月期间从东南亚国家主要电子商务网站获得的产品信息。它们涵盖越南语(VI)、泰语(TH)和印尼语(ID)。在注释之后,获得了每种语言的2000个产品标题,使用6个产品属性NER标记,包括产品、品牌、消费者组、材料、图案和颜色。将数据分为1000/500/500 —train/Dev/test。
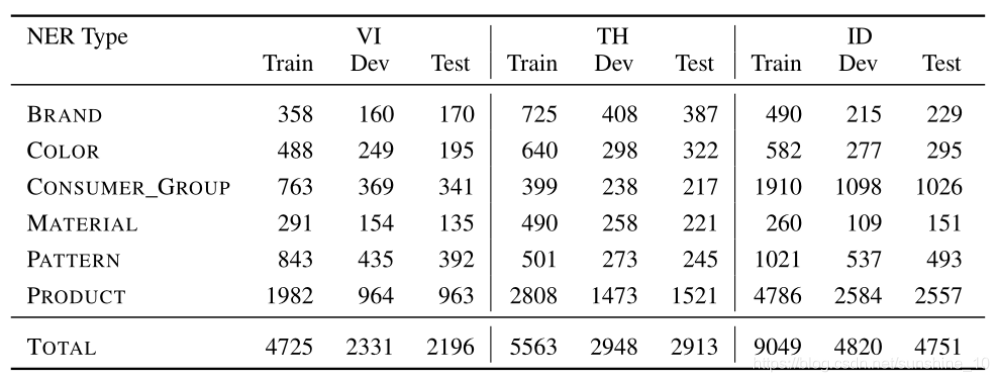
对于某些NER标签,尤其是PRODUCT,标签的数量远远大于所使用样本的数量。原因如下:
1、撰写产品标题的卖方倾向于包含多个引用同一实体的表达方式(近义词),目的可能是从潜在客户那里获得更多点击量。

蓝色的元素是3个PRODUCT实体,红色的是2个CONSUMER_GROUP实体
2、在一个产品标题中,经常会出现在同一种语言中重复相同的表达,以及在英语中出现相同的实体词。

带下划线的元素指的是同一商品(t恤),多次出现以越南语和英文撰写。
Training details
作者在Flair框架上实现模型,使用了IOBES标记方案,对每种语言使用维度为300的fastText 进行词编码和隐藏单元512个的单层BiLSTM,在BiLSTM层前后以及在残差连接之前的attention输出上使用固定概率为0.5的dropout,对于多头self-attention层,采用了“带注释的Transform”,并使用其默认的超参数。使用batch size为32,learning rate为0.001, gradient clipping为5的Adam对所有模型进行训练。通过抽样U(−0.1,0.1)来初始化所有模型参数。将式联合模型损失函数中的λ设为1。对所有语言使用相同的参数设置。使用early stopping训练,如果Dev集上的F1分数没有提高3倍,则学习速率衰减0.5,训练直到学习率下降到0.00001以下,或者训练迭代次数达到100。
Pre-trained classification models
作者收集了每种语言的未标注的产品名称,并将其分为6个主要类别,包括时尚、健康美容、电子产品、家居家具、汽车和其他。由于不同语言的产品标题数量不同,可以分别为VI、TH和ID创建360k/30k、1.2M/60k、864k/60k 培训/开发集。由于TH中没有对产品名称进行切分,因此使用从Kruengkrai等人的混合模型简化而来的基于字符聚类的方法对其进行切分。实现了基于CRF suite的分词系统,并利用最佳语料库对模型进行训练。我们预先训练每种语言的分类模型。由于批处理规模相对于训练数据规模较小,发现训练2个epoch就足够了。VI、TH和ID在开发集上F1得分分别为90.08%、89.79%和91.91%。利用预先训练好的模型参数对投影层和BiLSTM层进行初始化。
Main results
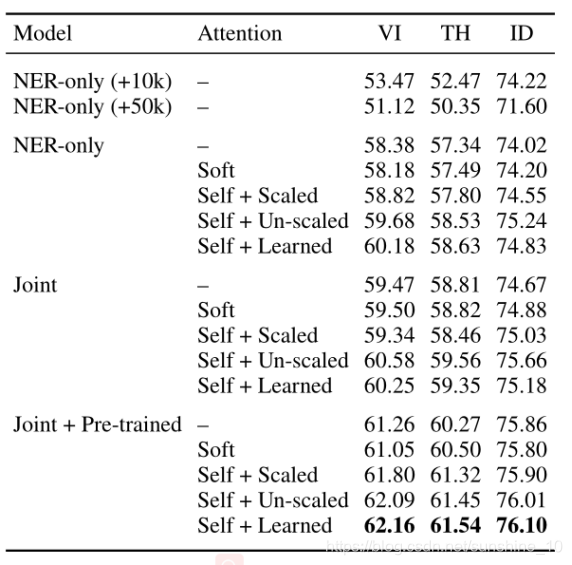
表中显示了测试集上各种模型的结果。另外使用简单的数据扩充进行了实验。表中的“+10k”和“+50k”行表示使用从训练集创建的字典自动标记的附加训练示例的数量,效果并不好。Joint模型F1值比NER-only模行有所改进,而Joint+Per-trained模行进一步提高F1值。这些结果表明,所提出的框架对这三种语言都是有效的。
model ablations

消融实验把注意力输出输入到CRF层而不保留残差连接,会导致F1分数的持续下降,尽管它对TH的影响不那么明显。结果表明,残差连接在本文体系结构中是一个有用的组成部分。将注意力输出添加到隐藏表示中而不应用locked dropout(即,将dropout概率设置为0)会损害F1在VI和TH上的分数,但显示ID有所改善,这表明微调dropout有助于提高F1分数。
Conclusion
实验证明,文中所提出的联合句子和标记标记模型对于三种不同语言的低资源NER是非常有效的:越南语、泰语和印尼语。模型支持多类分类,其中句子和token标签可以是弱相关的,这表明了本文的模型在许多其他实际应用中的潜力。



















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











