







15.分类与回归(=Location)任务应用详解

定位就是给框出来,用回归来做。

Location as regression:通过预测结果,不断拟合groudtruth的过程
一些技巧
对于某一任务,找合适的模型。一般,AlexNet和VGG就能够解决很多问题了。然后finetune。把别人训练好的已经很收敛的模型拿过来,结合自身任务进行finetune,方便快速收敛。
定位步骤:




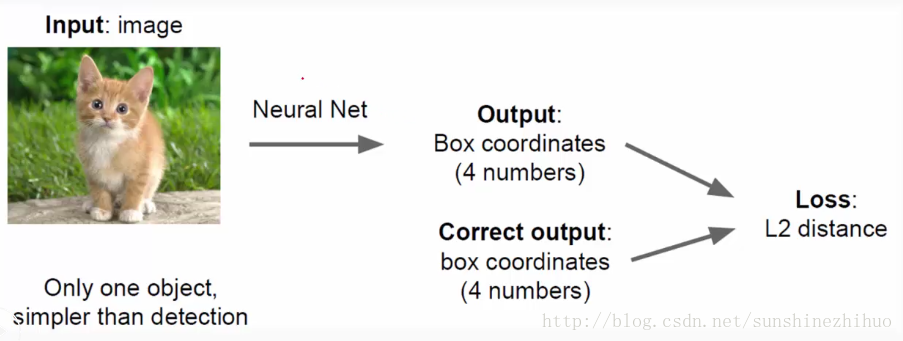
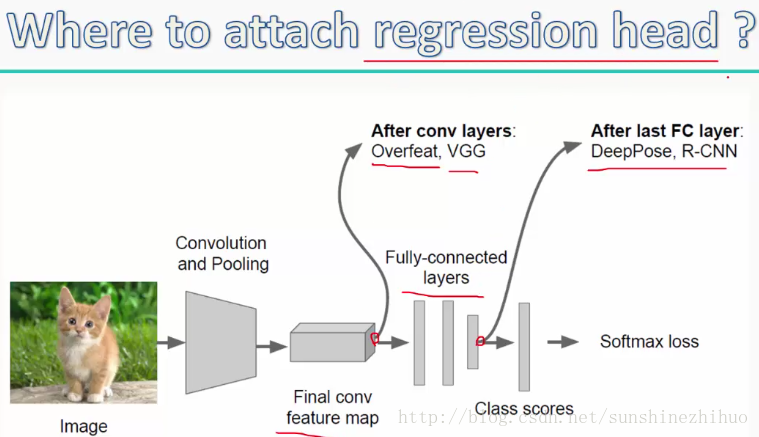
把回归模块加到哪个位置呢?放在哪个位置可以更好的完成回归任务呢?
滑动窗口:用滑动窗口在图像上进行移动,每次移动都得到一个区域。对这样的区域进行特征提取。
得分最高的区域就是Location的区域


16.物体检测实例

Region proposals:不再用滑动窗口找一些合适的位置了,也不做scale变换了,直接对图像生成合适的窗口。
那这些候选框是怎么弄出来的呢?Selective Search,简单的理解就是寻找有规律的特征,组合起来merge。至此,找出来有代表性的框。

RCNN固化特征:
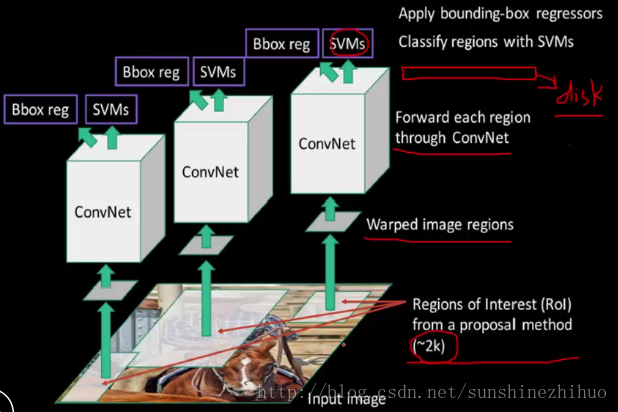
warped image regions: 把区域建议的框resize成相同大小。
R-CNN的做法:
用固化到disk上的特征,进行分类(SVM)和回归(linear model)。

Finetune:结合自身任务,修改参数。
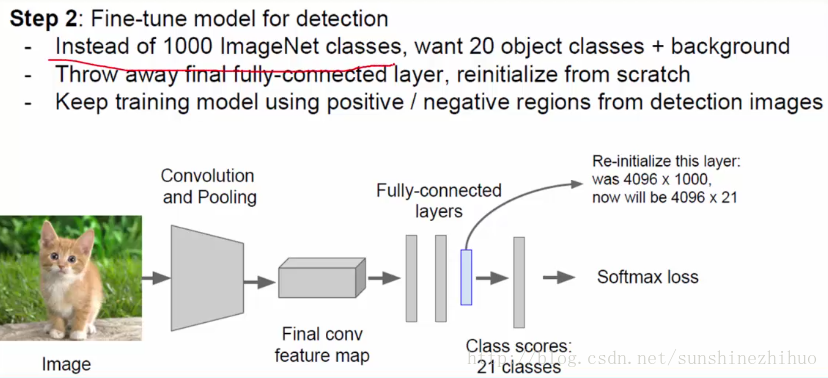
接下来是卷积提取特征的过程

有特征之后就可以进行分类了,20类,就用20个SVM分类器来完成任务。

因为是检测嘛,所以不光要有分类,还要有回归的操作。回归需要训练线性模型。

Fast R-CNN:训练速度极大提升,模型更小了。

实现了end-to-end:从输入到输出,网络是可以完成所有的事情的,中间无需任何操作。模型的可靠性更高。


Selective Search的时间太长了,这也是Fast R-CNN的缺点,那么如何减少这部分时间?
为节省时间,可否用卷积神经网络找到框,而不使用selective research呢?
Faster R-CNN
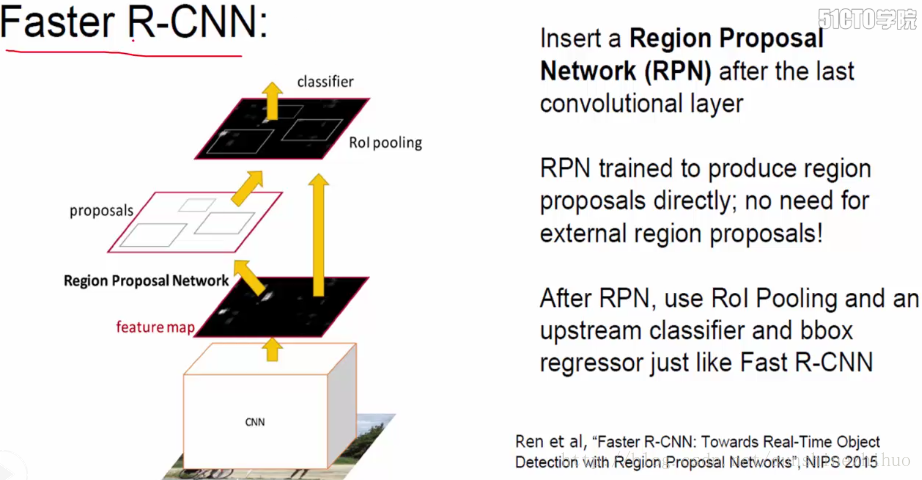
在Fast R-CNN中,找框的操作太耗时间了。。。在Faster R-CNN中,把找框的操作整合到了整个网络中。用卷积之后的特征图来生成框。此外,所有的训练和测试都是用的这一网络,没有其他分支,end-to-end。
Faster R-CNN的最大改进:Region Proposal Network
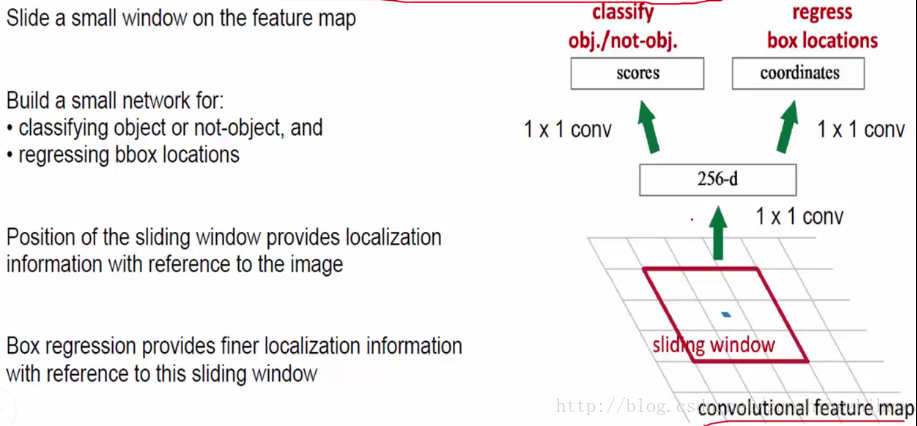
在feature map上用滑动窗口找一系列的框。

sliding window size 3*3,对这个3*3大小的东西生成n个anchors。当n=9时,意味着对这个3*3大小的区域,生成9个大小不一,形状不等的候选框,框有一定比例,以尽可能的框住物体。
在提取了框后,可以做很多事情:分类+回归。
一般情况下,做分类任务需要保持特征维度不变,但现在的问题是anchor框大小不一样。如何把这9个大小不同,形状不一的框映射为相同的特征图呢?(ROI pooling)
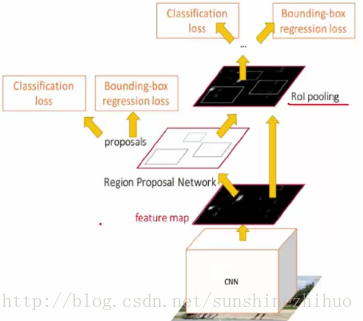
ROI pooling:对大小不同的框都进行Pooling操作,对所有9个框特征压缩,压缩到一个固定的大小(固定尺度)。用这个固定的大小做分类和回归的任务。
特点:

17.如何巧妙设计网络结构
感受野:对于特征图上的小单元,该小单元的感受野是对应原始图像的区域大小。卷积层数越多,后面特征图上单元的感受野就越大。conv1:3*3 conv2:5*5

想要得到7*7的感受野,
3个3*3的卷积的感受野等于一个7*7的卷积的感受野。但是所需参数不同。提倡使用3个3*3,拥有更少的参数和更强的非线性。

以下两个网络的表达效果相同,但参数量不同。A也是深度残差网络ResNet中用到的。

设计网络能够用到的小技巧:
卷积小技巧:

池化小技巧:
pooling,对特征图进行压缩,方便网络能够更快收敛,方便进行计算,使得网络能够训练起来。进行完pooling后,filter个数要进行翻倍。
size:224X224 ——- 112X112
filter:56——112
18.训练技巧之数据增强
Data Augmentation是在训练卷积神经网络的过程中能够用到的小技巧。让输入数据能够成倍增长,是数据预处理的一种常见方法。
在训练网络之前,需要对输入数据做数据增强的变换。Transform image.

常见的变换方式:
Horizontal flips(基本是在数据预处理中必做的),
Random crops/scales

crops和scales往往是一起用的。对不同scales进行random crops。
此外还有

translation(平移), rotation(对整个图像进行旋转), stretching(拉伸), shearing(修剪), lens distortions
实际中,上述变换是有值得,每次变换要把这些操作都做一遍,不过,数据增强是随机取值的,不要人为。应该进行随机组合,如translation=[-10,2],rotation=15等。
19.训练技巧之Transfer Learning
应用于数据不足的情况。用的模型后缀是.caffemodel.
没有太多合适的数据,data 增强也做了。但还是数据不足。
在进行transfer learning的时候,要将学习率设置的更小一些,一般是小10-100倍。已经拿过来使用的部分不宜做大的参数学习。

找与本任务相近的模型,model zoo
https://github.com/BVLC/caffe/wiki/Model-Zoo,
用这种transfer learning的方法可以使得网络收敛的更快。
20.深度学习框架Caffe简介
caffe官网:http://caffe.berkeleyvision.org/
caffe model zoo:https://github.com/BVLC/caffe/wiki/Model-Zoo
在model zoo中,AlexNet, VGG, GoogLeNet, ResNet, and so on.

几个重要组成部分:
Blob:
将data和label封装在blob中,用blob进行传输data和label。
Layer:
如卷积层,池化层,激活函数层,全连接层,等等。
Net:
所有层的组合。
Solver:
进行梯度更新。

从上图可知,caffe不需要写一个代码就可以训练网络。
但是,需要做到:
数据转换(对输入数据进行一系列的数据预处理,如取中值,resize到固定大小),把数据转换成所需要的格式LMDB,HDF5.
Define net:编写prototxt写网络
Define solver:编写prototxt定义参数,如学习率,输出模型保存位置,GPU/CPU,权重的衰减(正则化项),是控制超参数的。
Train:训练.sh文件
sh train.sh~
网络的Prototxt
对于网络而言,要知道每一层是什么,干了些什么事。
prototxt先写数据源,再写网络的整体架构。
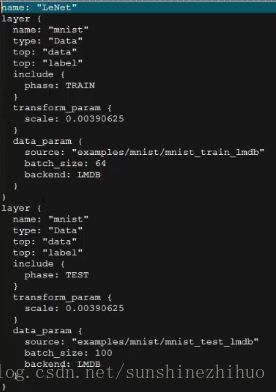
对于数据源来说,一个是train的数据源,再一个是test的数据源,他们的样本是完全不一样的。
bottom:输入
top:输出
一般top和name写一样的东西。
对于卷积而言,一般要指定filter的大小(kernel_size)和个数(numoutput)。
weight_filter是指的权重初始化的方式,更常见的是用高斯进行初始化。对于偏置项b也有初始化的方式。方式用type:指定,如type:“constant”。
卷积层后面接什么层完全是自己定义的。接卷积层conv也行,接池化层pooling也行。
啊,像流水线似的写layer。。。
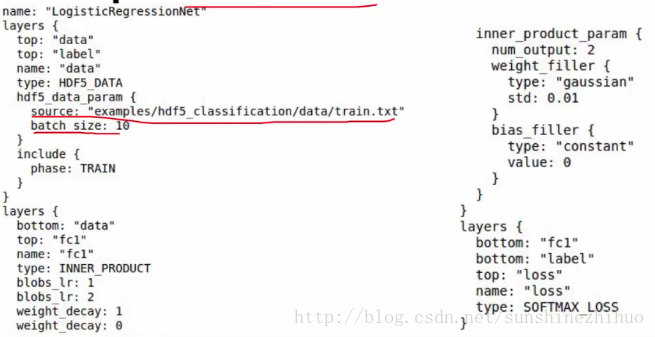
全连接层type:InnerProduct。
最后一层的num_output一定要和最后分类的个数紧密相连。
之后呢,还有两个层,一个是计算准确率的,再一个是计算loss的。
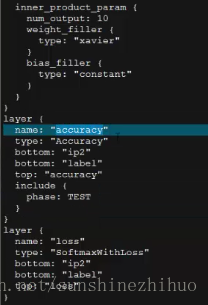
Solver的prototxt
指定一些超参数。如迭代的次数,最多的迭代次数,快照snapshot(每迭代n次,把训练好的模型进行保存),指定保存的位置。设置学习率base_lr,定义权重衰减项 weightdecay,动量momentum
在训练的时候,调用一个caffe的脚本即可。train_lenet.sh要到caffe的安装路径上(caffe接口),调用它的一个train操作。再把之前定义好的solver找到,然后就可以开始整个网络的训练了。


LMDB的读取速度快,便于整个神经网络的训练。大概格式是txt中写path label(空格哟),label是对应的类别编号0,1,2。label必须是数字。(对给定输入打上一个标签)
HDF5应用广泛,label值不仅仅是0,1,2的数字(分类),它可能是一个坐标值呀(回归任务)。
应该结合具体的任务转换成caffe支持的数据格式。

在训练的时候可能要指定一些参数,weights是应对于transfer learning的情况。

21.Caffe训练过程
.sh文件把所需要的操作都封装好了。
网络训练的过程就是让loss降低的过程。
数据分为两部分。Train和test,这里test实际上是指的验证集了。Train loss是进行迭代的。Test loss才是最终需要关注的,在用验证集进行验证时的loss的情况。
当发生过拟合时的解决方法(过拟合:train loss小 test loss几乎不变):数据增强,调整学习率,改变整体网络,选择其他数据,dropout率设置更高些。
22.Caffe接口使用实例
当训练好网络后,怎么使用训练好的网络模型?
其实,在官网中有Examples(如何train网络)和 Notebook Examples(IPython的网页版,展示如何去用之前训练好的模型)。
Caffe中,图像顺序是BGR,而非RGB。















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









