






在之前的文章中,我展示过如何用一个简单的基于文本格式来存储记录,并且对于读/写这些记录又意味着什么。在这样一个系统中搜索意味着你有相当多的工作要做,因为你需要扫描整个文件。
它不会真的为我们工作。所以,我们需要引入索引。索引其实是一个很简单的概念。鉴于我们有原始文件,我们将有以下用户名的索引:

基本上,该索引第一列的值是用户名,并且这些值是排序的,所以搜索索引有一个O(logN)与之复杂性相关联。一旦我们做到了,我们有记录编号,并且我们可以用它来找到文件中的位置和读取整个记录。
总的来说,这是最基本的,对吧?所以为什么我将整篇文章围绕这个主题?
恩,如果我们打算只做一次,索引的问题将非常简单。但是我们想更新它们,这会导致某些问题。虽然索引上面只显示几个记录,而实际的数据大小我们这里讨论的是一百万条记录。这给我们大约16 MB的总索引大小。如果我们需要添加一个新用户名,接下来会发生什么?在这种情况下,一个忠实的球迷,他的用户名是“棒球”吗?
为了维持秩序,我们不得不把它放在前两个条目之间。这将需要我们移动其余的相同数量的数据。实际上,为了向索引中添加一个条目,我们不得不写16MB。
换句话说,因为文件不允许我们从没有大量昂贵的I/O中间文件中动态地添加/删除数据,我们真的不能为此使用平面文件。这不是一个惊喜,但是我想从最低限度开始,并且在复杂层次结构中,我们会发现我们为什么需要这些东西。
因此,我们需要找到一个文件格式,将允许我们更新的东西不用每次洗牌整个文件。看文献,我可以采用比较平面文件的方法来有一个排序数组,并且它也存在同样的问题。典型的解决方案是使用一个二叉搜索树。通过这种方式,我们始终在文件的开头有树的根,并且根据我们需要去的地方,使用偏移量在文件中跳转。
在这种文件中,搜索的代码看起来像这样︰
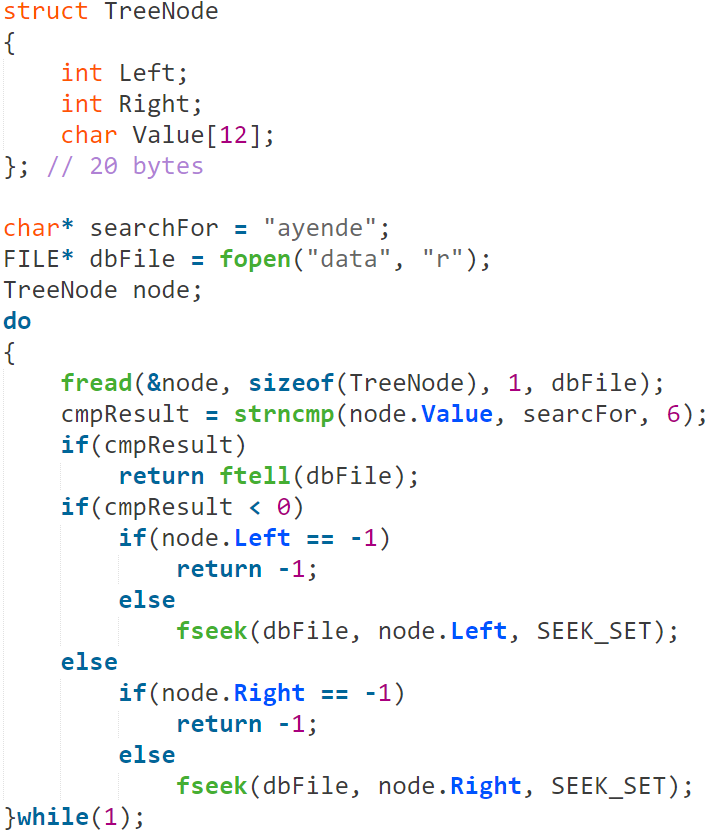
请注意,这里所有的错误处理会被删除,虽然它给了我们想要的,但是这种解决方案存在几个问题。
首先,如果我们想要拥有良好的性能,我们需要在平衡树上插入/删除,这可能很复杂。不仅如此,这也意味着,我们实际执行文件操作的数量是相当高的。然而这样不是很好,因为文件会驻留在硬件上(很慢),所以我们可能不想使用。
相反,我们需要找到一些东西可以让我们在文件中做更少的寻找(在标准硬盘上大约需要10-20毫秒),并能更好地处理并发工作(不会争夺磁头的太多位置)。我们还需要在确保工作量同时,所做的修改是最小的。在平衡树结构中,工作量平衡它可以是非常高的,并且周围跳转地方的数量是令人难以置信的。
原文:The Guts’n’Glory of Database Internals: Searching Information and File Format (译者/孙思)














 4551
4551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









