







在压缩算法中,熵编码是其中重要的无损压缩步骤。熵编码算法根据香农定理,对出现概率大的源符号用较少的编码符号进行编码,对概率小的源符号用较多的编码符号进行编码,尽可能地逼近压缩的极限。
目前各类压缩工具使用的熵编码算法主要有Huffman encoding,Arithmetic encoding, Range encoding和新出的Asymmetric Number System这几种算法。其中Huffman encoding由于只能在各个数据出现的概率固定为2的-n次方时才能达到最大,因此对于很多应用场景不适用。在视频编解码中,常用的是Arithmetic encoding和Range encoding,对于任意概率分布的符号流都能达到理论最优而且还适用于马尔可夫过程(概率可变,但只和过去的概率相关,和未来的概率无关)。它们二者本质上是同一种算法,但是对于算法中的概念有着不同的阐释。现实中Arithmetic encoding经常被一些专利保护着,比如CABAC,因此开源项目往往青睐于自行编写Range encoding算法进行熵编码。本文主要介绍Range encoding工程上的原理和实现。
示例步骤格式说明
<执行原因> -> <执行内容1>;<执行内容2>... //注释
基本实现
Range encoding算法持有一个整数Range(范围)作为其自身的状态,并对于每种符号按其概率大小比例对Range划分。编码时对于每一个输入的符号,将当前Range更新为该符号所落入的原Range的划分;在编码的最后当前范围的起始值作为编码结果。解码时检查编码结果,它落在哪个划分中就输出哪个符号,并取该划分为当前Range,不断迭代直至编码结果与当前范围的起始值相等。
举一个例子
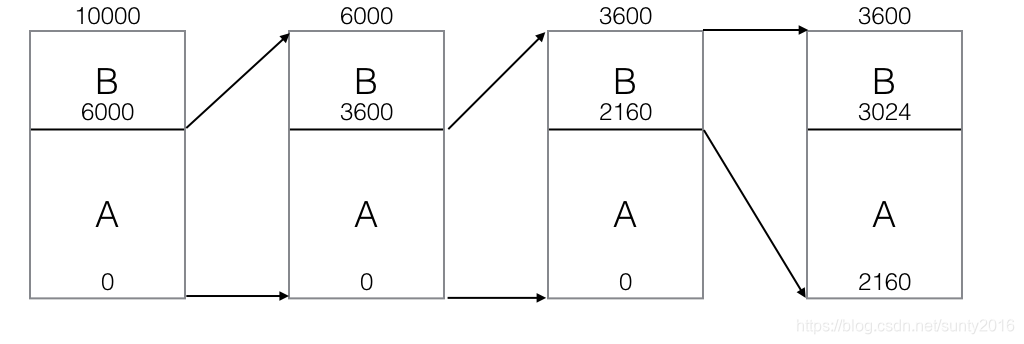
令输入符号集合为{A B},概率为60%、40%,初始Range为[0, 10000),源符号流为AAB
则编码算法进行如下步骤:
initial -> range = [0, 10000);
update -> rangeA = [0, 6000); rangeB = [6000, 10000) //A占60%,B占40%
input A -> range = [0, 6000)
update -> rangeA = [0, 3600); rangeB = [3600, 6000)
input A -> range = [0, 3600)
update -> rangeA = [0, 2160); rangeB = [2160, 3600)
input B -> range = [2160, 3600)
update -> rangeA = [2160, 3024); rangeB = [3024, 3600)
end of input -> output 2160; end
如图所示:
解码算法进行如下步骤,假设输入的编码结果为上例中的2160:
initial -> range = [0, 10000);
update -> rangeA = [0, 6000); rangeB = [6000, 10000)
2160 in rangeA -> range = [0, 6000); output A
update -> rangeA = [0, 3600); rangeB = [3600, 6000)
2160 in rangeA -> range = [0, 3600); output A
update -> rangeA = [0, 2160); rangeB = [2160, 3600)
2160 in rangeB -> range = [2160, 3600); output B
update -> rangeA = [2160, 3024); rangeB = [3024, 3600)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









