






很多人都在苦恼微信公众号的链接怎样提取出来?并且可以点击链接直接进入公众号内容页面,以查看历史文章并关注。
其实方法特别简单!
下面我们就来做详细介绍,一共分为两部分:第一部分内容是提取公众号链接,第二部分内容是将公众号链接生成二维码。
**
一, 如何提取公众号链接?
**
第一步,找到一个公众号
就拿二维彩虹二维码生成器来举例吧。
第二步,找到一篇历史文章
任何一篇历史文章都可以。然后复制文章的链接,在电脑端浏览器打开。

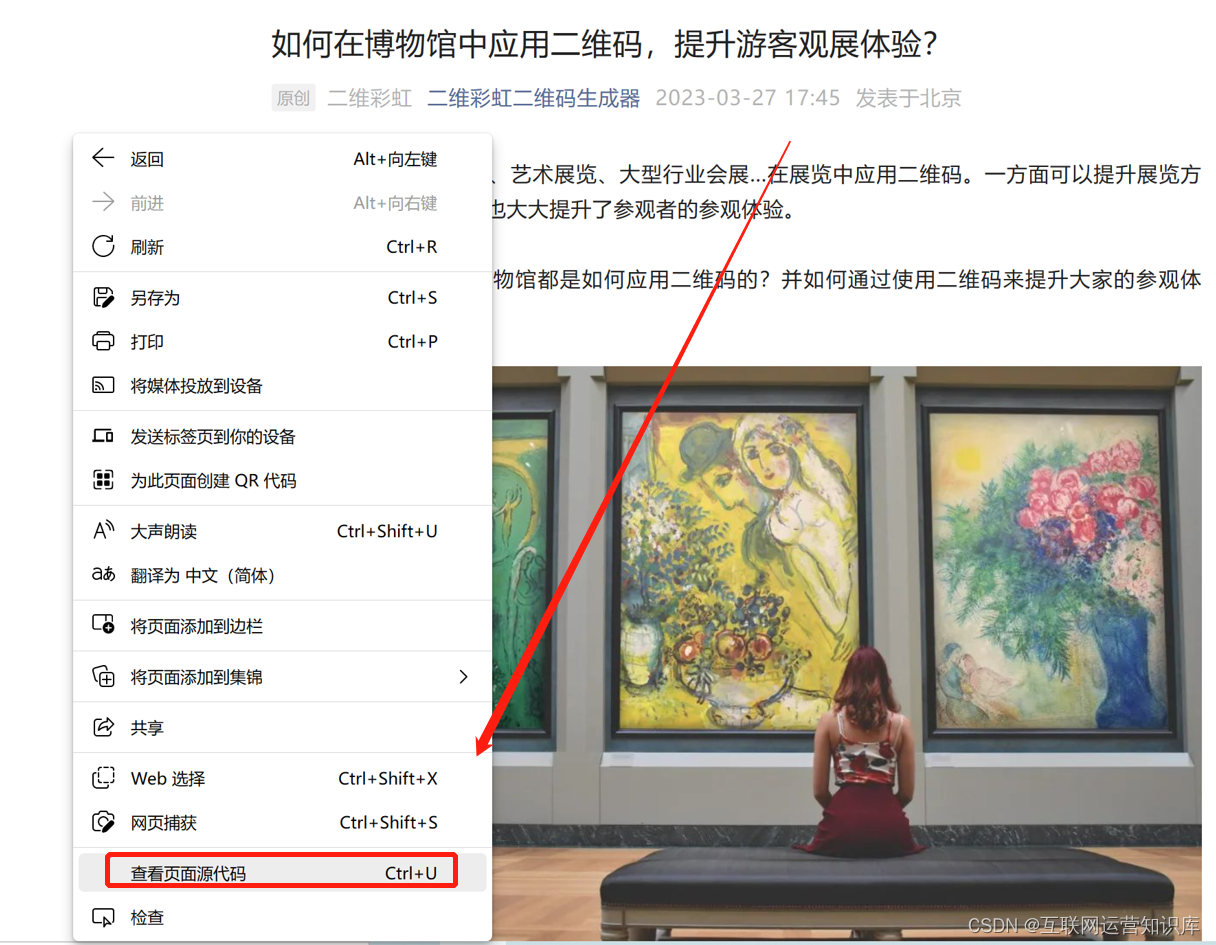
第三步,查看网页源代码
在浏览器打开文章之后,鼠标右键单击,并选择【查看页面源代码】。
第四步,查找Biz 值
在页面源代码界面,按住ctrl+F 快捷键,搜索Biz, 找到如下的位置:
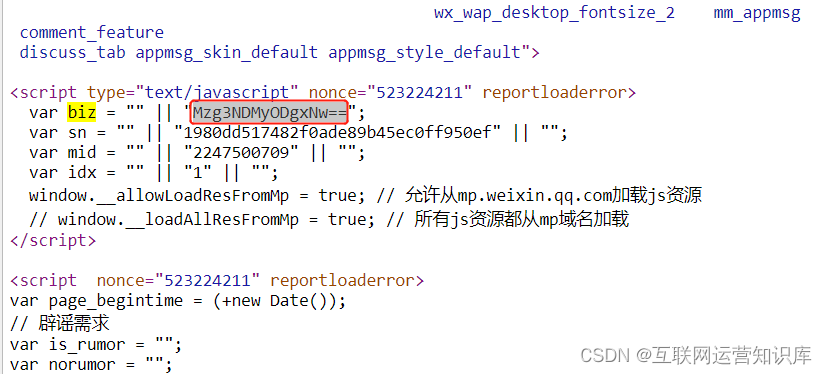
并复制图中这个双引号里面的信息: Mzg3NDMyODgxNw==
Biz值,一般出现在大段的蓝色代码下面。
第五步,获得公众号链接
公众号链接有一个万能替换公式,你只需要将前面复制的Biz 值,放入下面这个链接里面正确的位置就好了。
万能公式:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=替换biz的值&scene=124#wechat_redirect
将前面获得的biz值(Mzg3NDMyODgxNw==)替换到上面这个万能公式里面的(替换biz值),就可以获得一个完整的公众号链接了。
第六步,在微信中打开公众号链接
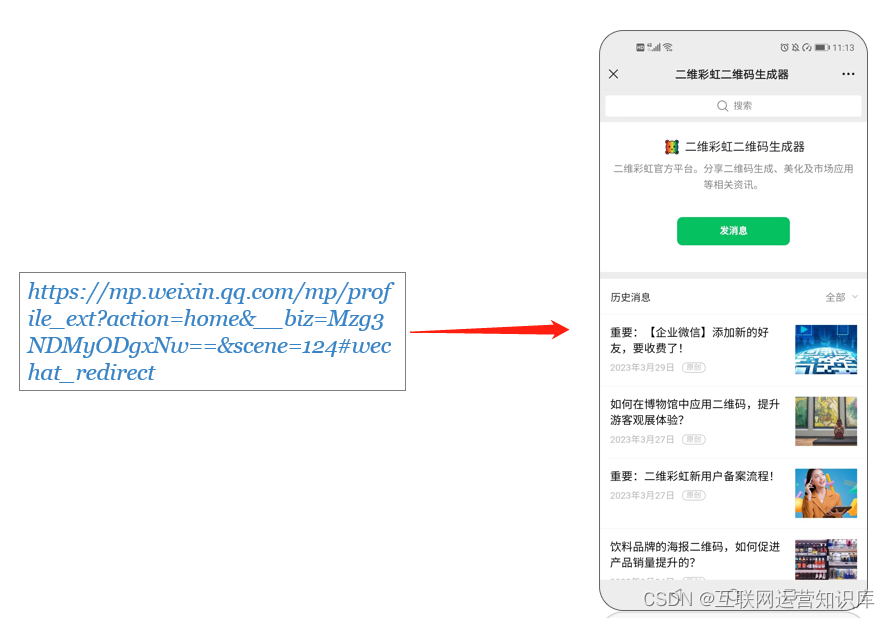
好了,现在我们已经成功获取了一个微信公众号的链接。你可以在文章中、短信里、以及其他无法展示二维码的场景中使用此链接。
**
二, 如何将公众号链接生成一个二维码?
**
通过应用二维彩虹二维码生成器,你可以:
1, 速将一个公众号链接生成一个网址链接二维码。
可以自定义美化设计这个二维码的样式、样色等。
2,还可以将很多个公众号的链接生成一个二维码。
3,也可以将公众号的链接和其他社交媒体账号主页链接放在一个社交媒体二维码中。
如:公众号、视频号、微博、知乎、抖音、小红书、淘宝店铺……下面我们来介绍具体的操作步骤。
(1)登录二维彩虹二维码生成器官网
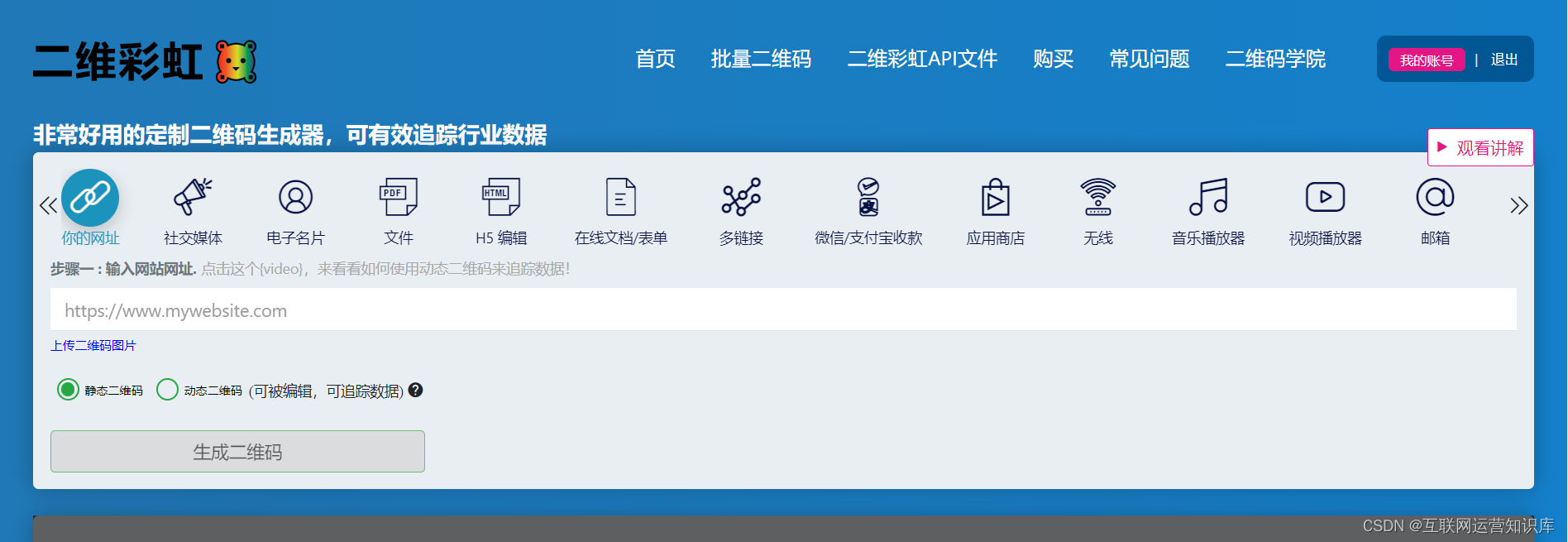
(2)选择“社交媒体”选项
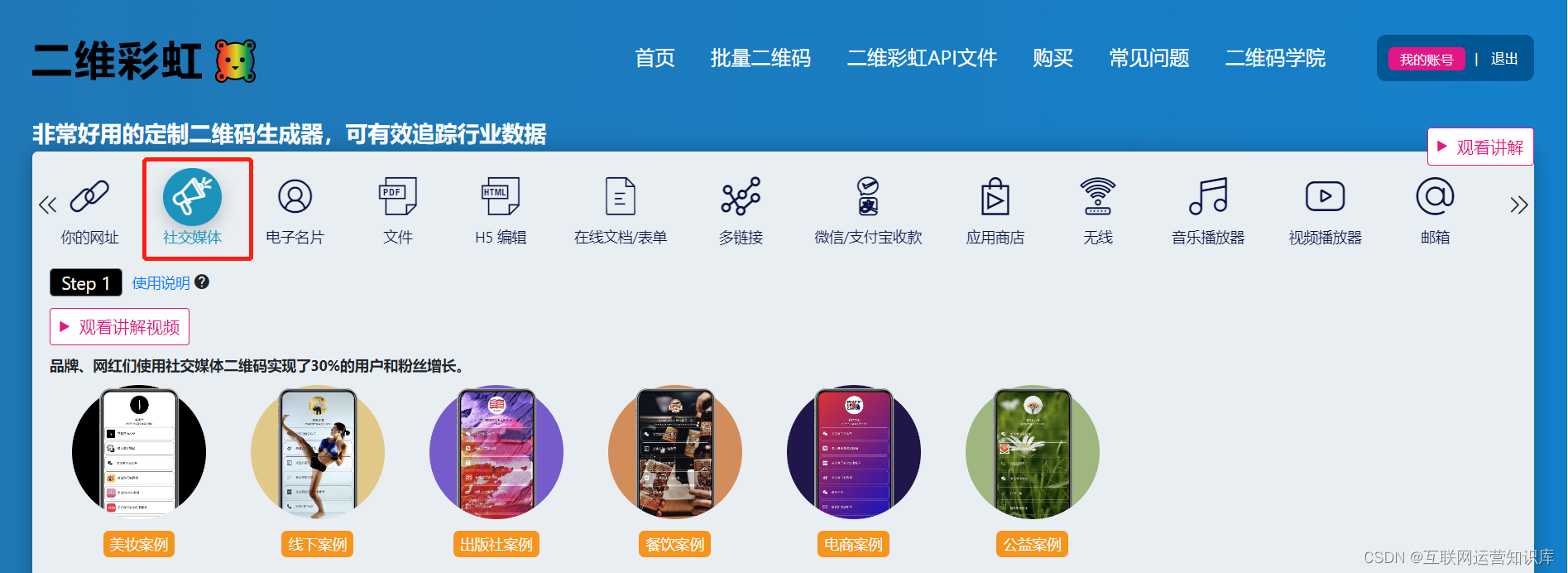
然后填写信息:上传头像、设置背景、编辑文字、填写各个链接,最后点击生成二维码,进入下一步美化。
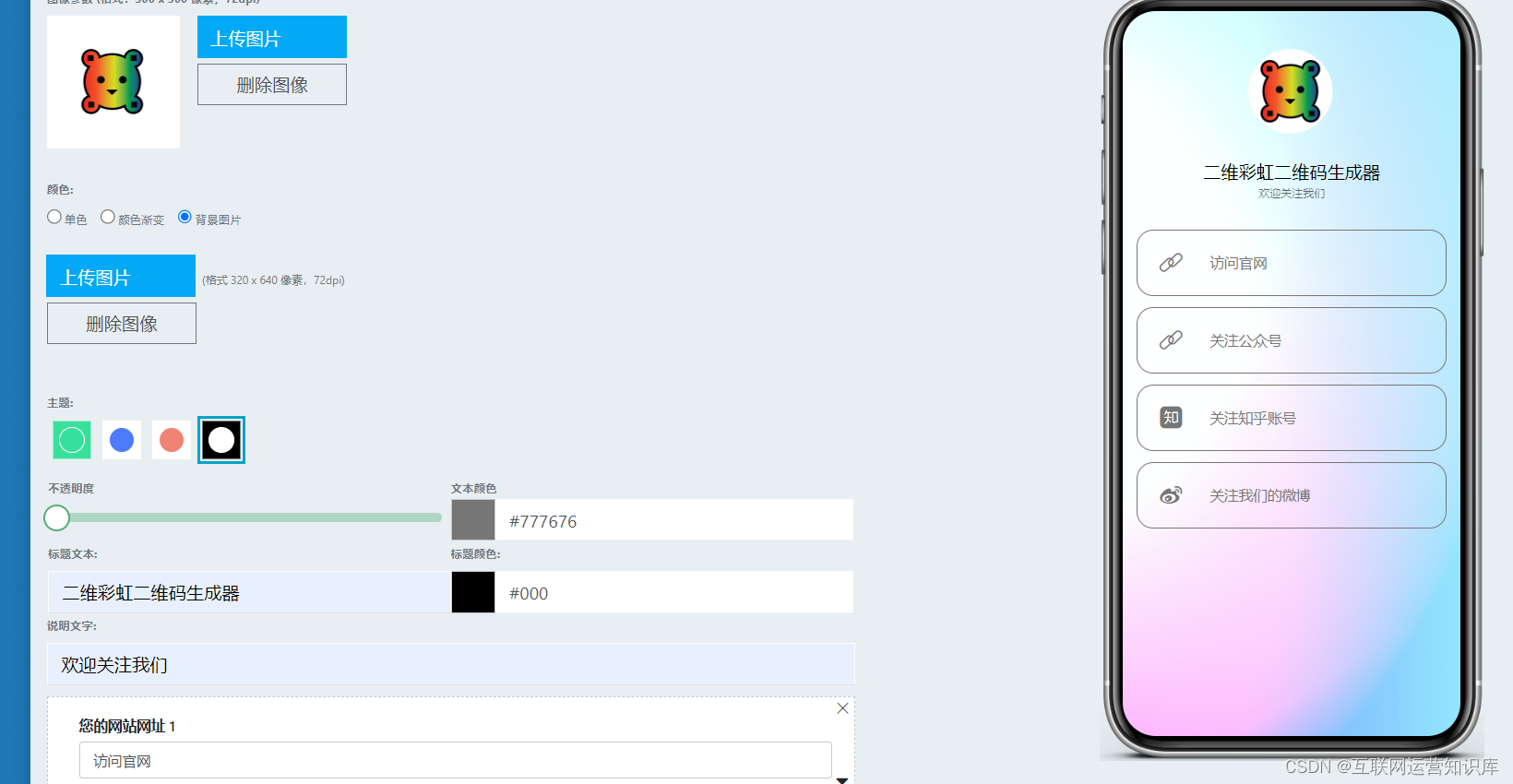
(3)自定义美化
(4)扫描测试
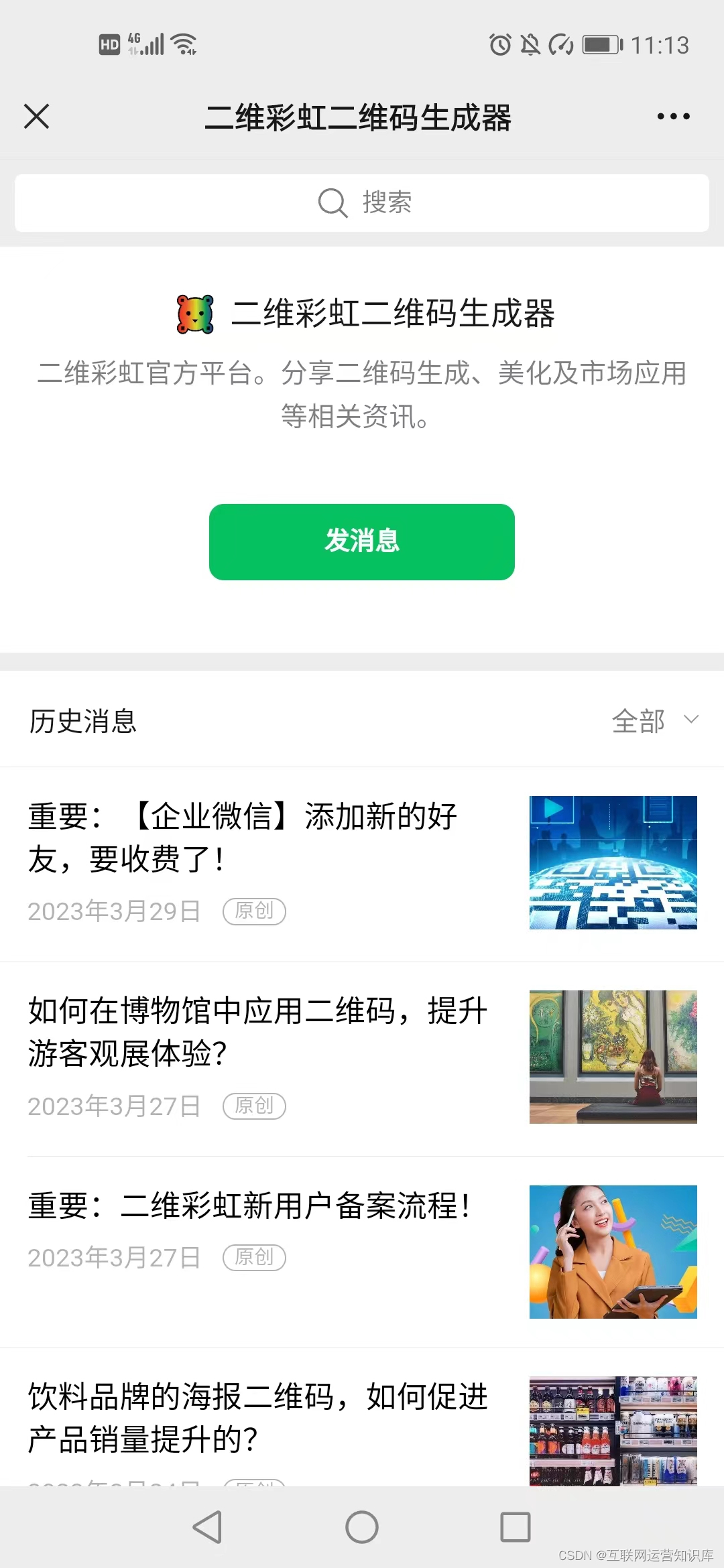
到这里,社交媒体二维码就制作完成了。你可以扫描测试,并点击其中的选项按钮,就能直接跳转到相应的社交媒体账号主页了。
**
三,社交媒体二维码有什么特点?
**
(1)社交媒体二维码UI界面可自定义设计
背景可以设置成单色、渐变色、或者使用自己设计的图片作为背景。其中的按钮格式一共有4种样式可供选择。还支持插入一个B站视频展示。
(2)可追踪扫描数据
社交媒体二维码不仅支持追踪总的扫描数据,还能查看每个渠道(按钮)的点击次数。比如公众号按钮的点击次数、微博按钮的点击次数等。
(3)可随时更新UI界面内容
在保持社交媒体二维码不替换的情况下,二维码里面的内容可以随时做更新。比如换一下背景色、更新一些文字信息等。
(4)二维码样式自定义美化
以上便是我们今天的所有内容了。
原文阅读:
教程:如何提取微信公众号链接?非常简单!

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









