







RocketMQ的安装与启动
一、基本概念
1、消息(Message)
消息是指,消息系统所传输信息的物理载体,生产与消费数据的最小单位,没条消息必须属于一个主题。
2、主题(Topic)
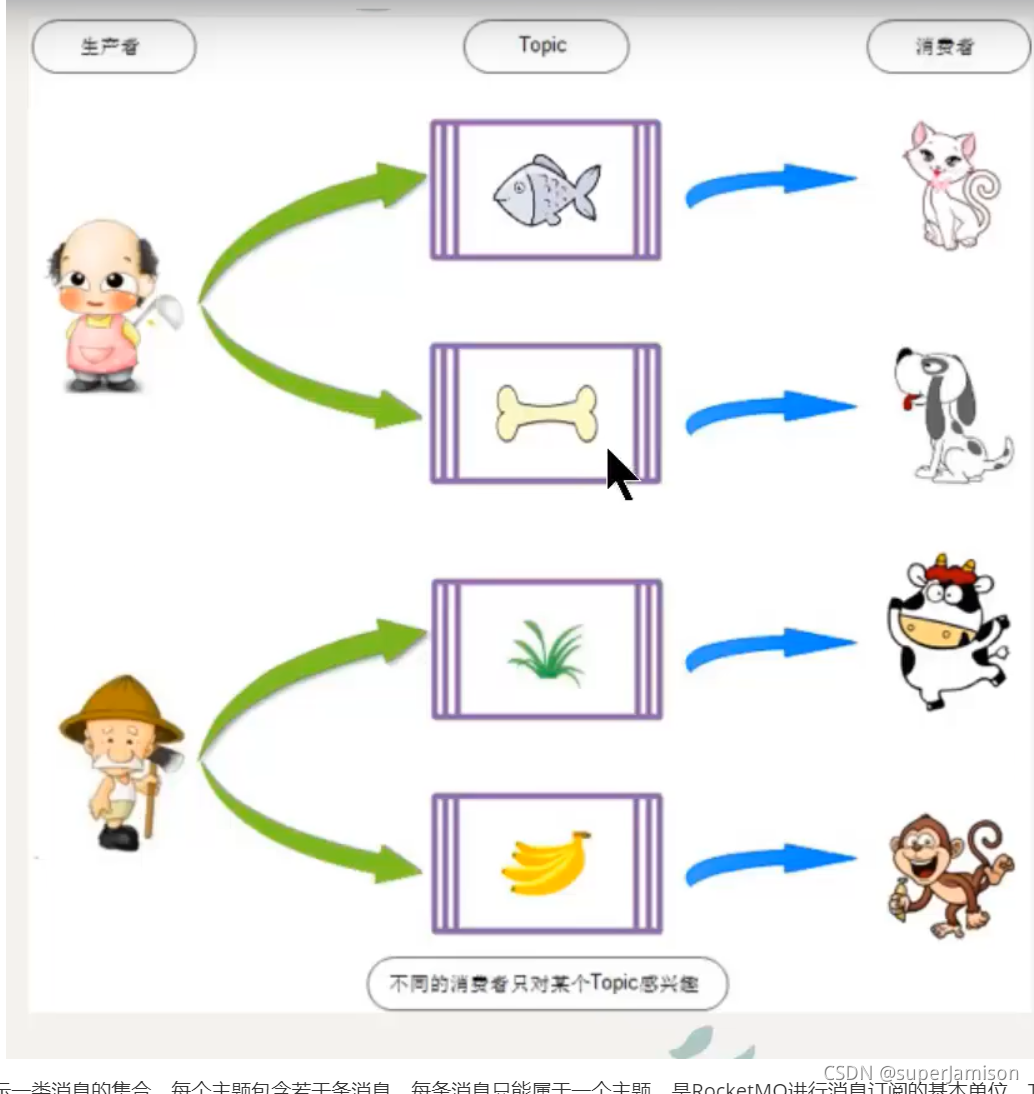
Topic表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。Topic:Message 1:n Message:Topic 1:1
一个生产者可以同时发送多种Topic的消息,而一个消费者只对某种特定的Topic感兴趣,即值可以订阅和消费一种Topic的消息。 Product:Topic 1:n Consumer:Topic 1:1
3、标签(Tag)
为消息设置的标签,用于统一主题下区分不同类型的消息。来自统一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效的保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现不同主题的不同消费逻辑,实现更好的扩展性。
4、队列 (Queue)
存储消息的物理实体。一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
一个Topic的Queue中的消息只能被一个消费者组中的一个消费者消费。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R7TNUxO9-1630034007413)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818073253904.png)]](https://img-blog.csdnimg.cn/5e3c5253482441d08af9ab074063250c.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
一个Topic的Queue仅仅可以被一个消费者组中的一个消费者消费。一个Topic的Queue可以被不同消费者组中的各自的某一个消费者消费。多个Topic可以被同一个消费者组中的同一个消费者消费。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zyp5qLDH-1630034007414)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818073444535.png)]](https://img-blog.csdnimg.cn/3f129c56e2ac443ab57b1d0e8ca626c7.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
在学习参考其它相关资料时,还会看到一个概念:分片(Sharding)。分片不同于分区。在RocketMQ中,分片指的是存放相应Topic的Broker。每个分片中会创建出相应数量的分区,即Queue,每个Queue的大小都是相同的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vLEwo05l-1630034007416)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818073953047.png)]](https://img-blog.csdnimg.cn/09966273209440359f5271da0c2838cd.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
5、消息的表示(MessageId/Key)
RocketMQ中每个消息拥有唯一的Messageld,且可以携带具有业务标识的Key,以方便对消息的查询。不过需要注意的是,Messageld有两个:在生产者send()消息时会自动生成一个Messageld (msgId),当消息到达Broker后,Broker也会自动生成一个Messageld(offsetMsgId)。msgId、offsetMsgIld与key都称为消息标识。
-
msgld:由producer端生成,其生成规则为:
producerIp +进程pid + Messagec1ientIDsetter类的c1assLoader的hashcode +当前时间+ AutomicInteger自增计数器 -
offsetMsgld:由broker端生成,其生成规则为: brokerIp +物理分区的offset (Queue中的偏移量)
-
key:由用户指定的业务相关的唯一标识
二、系统架构

RocketMQ架构主要分为四部分构成:
1、Producer
消息的生产者,负责生产消息。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息的投递,投递的过程支持快速失败并且低延迟。
例如,业务系统产生的日志写入到MQ的过程,就是消息的生产过程
再如,电商平台中用户提交的秒杀请求写入到MQ的过程,就是消息的生产过程
RocketMQ中的消息生产者都是以生产者组(ProDec而 Group)的形式出现的。生产者组是同一类生产者的集合,这类Prodecer发送相同Topic类型的消息。一个生产者组可以同时发送多个主题的消息。
2、Consumer
消息消费者,负责消费消息。一个消息消费者会从Broker服务器中获取到消息,并对消息进行像个业务处理。
例如 ,Qos系统从MQ中读取日志,并对日志进行解析处理的过程就是消息消费的过程。
再如,电商平台的业务系统从MQ中读取到秒杀请求,并对请求进行处理的过程就是消息消费的过程。
RockerMQ中消息消费者都是以消费者组(Consumer Group)的形式出现的。消费者组是同一类型的消费者的集合,这类Consumer消费的是同一个Topic类型的消息。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。

消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的Consumer将不能消费消息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WwzRwjpB-1630034007420)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818093809456.png)]](https://img-blog.csdnimg.cn/7397ea6ec6dd4ceaabc1874e7c5e02a8.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
不过,一个Topic类型的消息可以被多个消费者组同时消费。
注意:
1)消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息。
2)一个消费者组中的消费者必须订阅完全相同的Topic。
3、Name Server
功能介绍
NameServer是一个Broker与Topic路由的注册中心,支持Broker的动态注册与发现。
RocketMQ的思想来自于Kafka,而Kafka是依赖了Zookeeper的。所以,在RocketMQ的早期版本中,即在MetaQ v1.0与2.0版本中,依赖的仍是Zookeeper。从MetaQ v3.0,即RocketMQ开始去掉了Zookerper依赖,使用了自己的NameServer。
主要包括两个功能:
- Broke管理:接受Broker集群的注册信息并且保存下来作为路由信息的基本数据;提供心跳检测机制,检查Broker是否存活。
- 路由信息管理:每一个NameServer中都保存着Broker集群的整个路由信息和用于客户端查询的队列信息。Producer和Consumer通过NameServer可以获取整个Broker集群的路由信息,从而进行消息的投递和消费。
路由注册
NameServer通常也是以集群的方式部署的,不过,NameServer是无状态的,即NameServer集群中的各个节点建是无差异的,各节点之间相互不进信息的通信。那各节点间是如何进行数据的同步的呢?在Broker节点启动时,轮询NameServer列表,与每个NameServer节点建立长连接,发起注册请求。在NameServer内存维护一个Broker列表,用来童泰存储Broker信息。
注意,这是与其他想Zookeeper、Eureka、Nacos等注册中心不同的地方。
这种NameServer的无状态方式,又是优缺点:
优点:NameServer集群的搭建非常的建东,扩容简单,只需要启动一个NameServer即可。
缺点:对于Broker,必须明确指出所有的NameServer地址。否则未指出的将不会去注册。也正是因为如此,NameServer并不能随便的扩容。因为,若Broker不重新配置,新增的NameServer对于Broker来说是不可见的,其不会向这个NameServer进行注册。
Broker节点为了能证明自己还是活着的,为了维护与NameServer间的长连接,会将最新的信息以心跳包的方式报给NameServer,每30秒发送一次心跳。心跳包包含了BrokerId、Broker的地址(IP + Port)、Broker名称、Broker所属集群的名称等待。NameServer在接受到心跳包后,会更新心跳时间戳,记录这个Broker的最新存活时间。
路由剔除
由于Broker关机、宕机或网络抖动等原因,NameServer没有收到Broker的心跳,NameServer可能会将其从Broker列表中剔除。
NameServer中有一个定时任务,每个十秒就会扫描一次Broker表,查看每一个Broker的最新心跳时间戳记录当前时间是否超过120秒,如果超过了,则会判定Broker失效,然后将其从Broker列表中剔除。
扩展:对于RockerMQ的日常运维工作中,例如broker升级,需要停掉Broker的工作。OP需要怎么做?
OP需要将Broker的读写权限禁掉。一旦Client(Consumer或Producer)向Broker发起请求,都会收到Broker的NO_PERMISSION的响应,然后Client会进行对其他的Broker的重试。
当OP观察到这个Broker没有流量后,再关闭它,实现Broker从NameServer中剔除。
OP:运维工程师
SRE:Site Reliability Engineer,现场可靠性工程师
路由发现
RocketMQ的路由发现采用的是Pull模型。当Topic路由信息出现变化时,NameServer不会自动推送个客户端,而是客户端定时拉去主题最新的路由。默认客户端没30秒回拉去一次最新的路由。
扩展:
1)Push模型:推送模型。其实时性较好,是一个“发布-订阅”模型,需要维护一个长连接。而长连接的维护是需要资源成本的。该模型适合的场景:
- 实时性要求较高
- Client数量不多,Server数据变化较频繁
2)Pull模型:拉取模型。存在问题是,实时性较差。
3)Long Polling模型:长轮询模型。其实对Push与Pull模型的整合,充分的利用了这两种模型的优点,屏蔽了他们的劣势。
客户端NameServer选择策略
这里的客户端是指Producer与Consumer
客户端在配置是必须要写上一个NameServer集群的地址,那么客户端到底连接的是哪一个NameServer呢?
客户端首先会产生一个随机数,然后再与NameServer节点数量取模,此时得到的就是所要选择连接的节点索引,然后就会进行连接。如果连接失败,则会采用round-robin策略,逐个尝试着去练剑其它节点。
首先采用的是随机策略进行选择,失败后采用轮询策略。
4、Broker
功能介绍
Broker充当这消息的中转角色,负责存储消息,转发消息。Broker在RocketMQ系统中负责接受并存储从生成者发送来的消息,同时为消费者的拉取请求做准备。Broker同时也存储这消息相关的元数据,包括消费者组消费进度offset、主题、队列等。
kafka 0.8之后是存放在Broker中的,之前版本是存放在Zookeeper中的。
模块构成
下图是Broker Server的功能模块示意图。
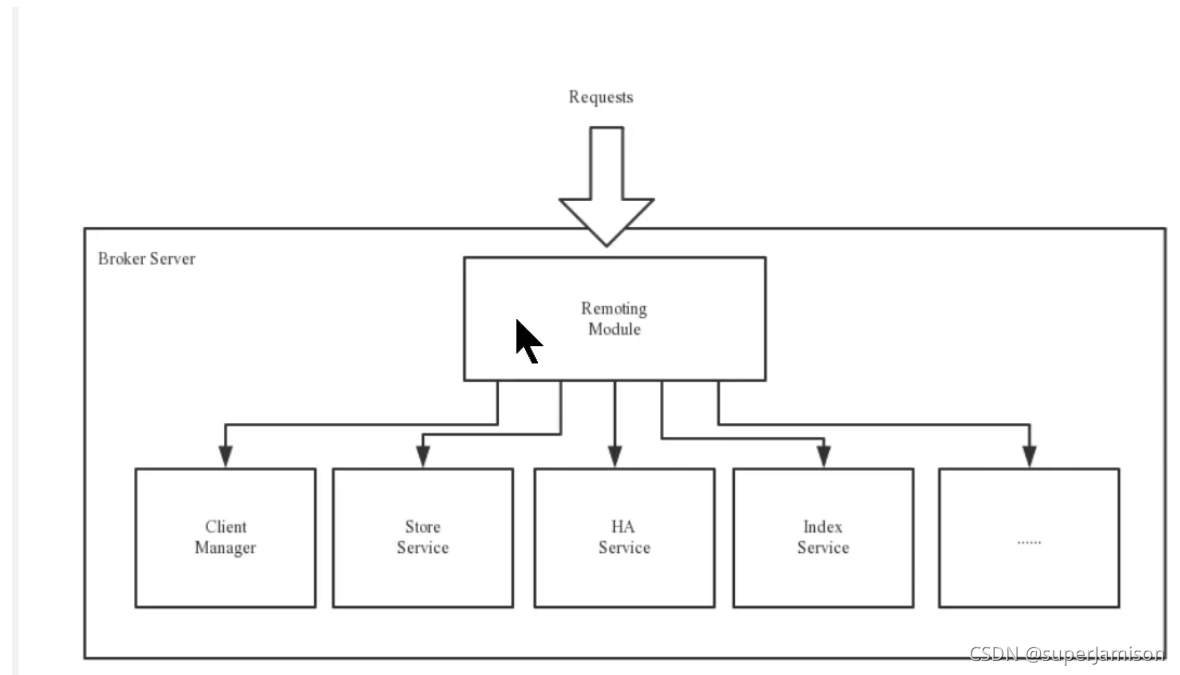
Remoting Module:整个Broker的实体,负责处理来自clients端的请求。而这个Broker实体则由以下模块构成。
Client Manager:客户端管理器。赋值接受、解析客户端(Producer/Consumer)请求,管理客户端。例如,维护Consumer的Topic订阅信息。
Stoere Service:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘和消息查询功能。
HA Service:高可用服务,提供Master Broker和Slave Broker之间的数据的同步功能。
Index Service:索引服务。根据特定的Message Key,对投递到Broker的消息进行索引的服务,同时提供根据Message Key对消息进行快速查询的功能。
集群部署
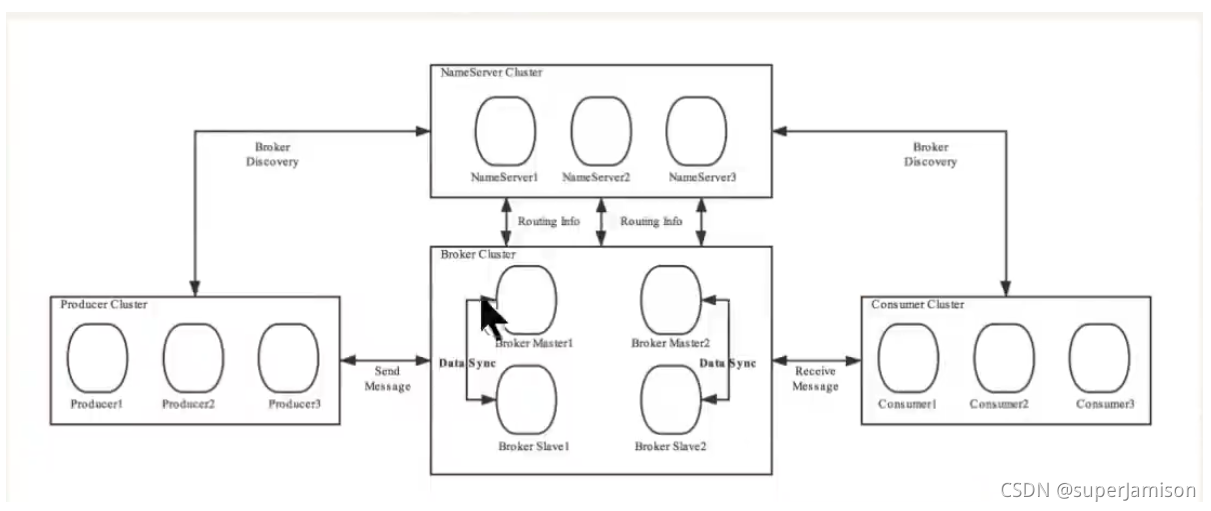
为了增强Broker性能与吞吐量,Broker一般都是以集群形式出现的。各集群节点中可能存放着相同Topic的不同Queue。不过,这里有个问题,如果某Broker节点宕机,如何保证数据不丢失呢?其解决方案是,将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群,解决单点问题。
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。所以这个Broker集群是主备集群。一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。
Master与Slave的对应关系是通过指定相同的BrokerName、不同的Brokerld来确定的。Brokerld为0表示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
5、工作流程
具体流程
1)启动NameServer,NameServer启动后开始监听端口,等待Broker、Producer、Consumer连接。
2)启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后没30秒向NameServer定时发送心跳包。
3)收发消息前,可以先创建Topic,创建Topic是需要指定该Topic要存储在那个Broker上,当然,在创建Topic是也会将Topic与Broker的关系写入到NameServer中。不过,这不是可选的,也可以在发送消息的时候自动创建Topic。
4)Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取路由信息,即当前发送的Topic的Queue与Broker地址(IP + Port)的映射关系。然后根据算法策略从中选择一个Queue ,与队列所在的Broker建立长连接发送消息。当然,在获取到路由信息之后,Producer会首先将路由信息缓存在本地,再每30秒从NameServer更新一次路由信息。
5)Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取其所订阅的Topic的路由信息,然后根据算法策略从路由信息中获取到其所要消费的Queue,然后直接跟Broker建立长连接,开始消费其中的消息。Consumer在获取到路由信息后,同样也会每30秒从NameServer更新一次路由信息。不过不同于Producer的是,Consumer还会向Broker发送心跳,以确保Broker的存活状态。
Topic的创建模式
手动创建Topic时,有两种模式:
- 集群模式:该模式下创建的Topic在该集群中,所有的Broker中的Queue数量是相同的。
- Broker模式:该模式下创建的Topic在该集群中,每一个Broker的数量可以不同。
自动创建Topic时,默认采用的是Broker模式,会为每一个Broker默认创建4个Queue。
读写队列
从物理上来讲,读/写队列是同一个队列。所以,不存在读/写队列数据同步问题。读/写队列是逻辑上进行区分的概念。一般情况下,读/写队列数量是相同的。
例如,创建Topic是设置的写队列数量为8个,读队列数量为4,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到8个队列中,但Consumer只会消费0 1 2 3这4个队列中的消息,4 5 6 7中的消息是不会被消费的。
再如,创建Topic是设置的写队列数量为4个,读队列数量为8,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到4个队列中,Consumer会消费0 1 2 3 4 5 6 7 这8个队列中的消息,但是4 5 6 7 这4个队列是没有消息可消费的。
也就是说,当读/写队列数量设置不同是,总是有问题。那么为什么要这样设计呢?
其这样设计的目的是为了,方便Topic的Queue的缩容。
例如,原来创建的Topic中包含16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息?可以动态修改写队列数量为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列数量动态设置为8。整个缩容过程,没有丢失任何消息。
perm用于设置对当前创建Topic的操作权限:2表示只写,4表示只读,6表示读写。
三、RocketMQ的安装与启动
1、基础环境的搭建
centos7、JDK1.8的环境
2、下载RocketMQ安装包
http://rocketmq.apache.org/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3fZUGx35-1630034007423)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818160556553.png)]](https://img-blog.csdnimg.cn/1e1d1fdb0be2407f980ac75657e305de.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
选择二进制源码包安装
点击下载链接
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IOMQii9C-1630034007424)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210818160759412.png)]](https://img-blog.csdnimg.cn/79ef64707d3a4228996cc61b1f988405.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
上传到linux上
## 新建项目路径
[root@rocketmqOS01 rocketmq_install]# pwd
/rocketmq/rocketmq_install
## 将下载的安装包上传到linux上
[root@rocketmqOS01 rocketmq_install]# rz -E
rz waiting to receive.
[root@rocketmqOS01 rocketmq_install]# ls
rocketmq-all-4.9.0-bin-release.zip
## 解压,安装zip解压工具
[root@rocketmqOS01 rocketmq-all-4.9.0-bin-release]# yum install unzip
[root@rocketmqOS01 rocketmq-all-4.9.0-bin-release]# unzip rocketmq-all-4.9.0-bin-release.zip
[root@rocketmqOS01 rocketmq_install]# ls
rocketmq-all-4.9.0-bin-release rocketmq-all-4.9.0-bin-release.zip
3、修改初始内存
## 将-Xms4g -Xmx4g -Xmn2g改小一点
[root@rocketmqOS01 bin]# vim runserver.sh
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
## 同样的道理修改:runbroker.sh
[root@rocketmqOS01 bin]# vim runbroker.sh
JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m"
4、启动RocketMQ
参照官网的启动,官网地址:http://rocketmq.apache.org/docs/quick-start/
## Start Name Server
> nohup sh bin/mqnamesrv &
> tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
## Start Broker
> nohup sh bin/mqbroker -n localhost:9876 &
> tail -f ~/logs/rocketmqlogs/broker.log
The broker[%s, 172.30.30.233:10911] boot success...
注意:此时官方的版本存在一个bug,就是会报Error when measuring disk space usage, file doesn’t exist on this path: /root/store/consumequeue的错误。网上也有些人说明了问题。例如下面这个人的博客就说明了问题:
https://blog.csdn.net/qq23ue/article/details/112764507
经过我的测试,我们只要在他提示的/root/store/路径下创建 consumequeue/commitlog目录报错就好了。
5、发送和接受消息
启动之后我们就可以发送和接受消息了,
## 暴露9876端口
> export NAMESRV_ADDR=localhost:9876
## 批量生产消息
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
SendResult [sendStatus=SEND_OK, msgId= ...
## 接收消息
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
ConsumeMessageThread_%d Receive New Messages: [MessageExt...
6、关闭服务
> sh bin/mqshutdown broker
The mqbroker(36695) is running...
Send shutdown request to mqbroker(36695) OK
> sh bin/mqshutdown namesrv
The mqnamesrv(36664) is running...
Send shutdown request to mqnamesrv(36664) OK
四、RocketMQ-Console安装、使用详解
1、rocketmq-console下载、部署
进入https://github.com/apache/rocketmq-externals的github地址。
下载到本地,打开修改一些application.properties 配置
server.contextPath=/rocketmq
server.port=8080
rocketmq.config.namesrvAddr=192.168.80.60:9876
在pom.xml添加依赖
<!--jaxb-->
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.3.0.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
把项目打成jar包,启动
$ mvn clean package -Dmaven.test.skip=true
$ java -jar target/rocketmq-console-ng-1.0.0.jar
#如果配置文件没有填写Name Server的话,可以在启动项目时指定namesrvAddr
$ java -jar target/rocketmq-console-ng-1.0.0.jar --rocketmq.config.namesrvAddr='localhost:9876'
#因为本文在打包时配置了namesrvAddr,故而执行如下命令
$ java -jar target/rocketmq-console-ng-1.0.0.jar
执行成功后。访问: http://localhost:9000/rocketmq
其实你也可以自己在idea中打开,再配置后启动。
默认的四个Queue
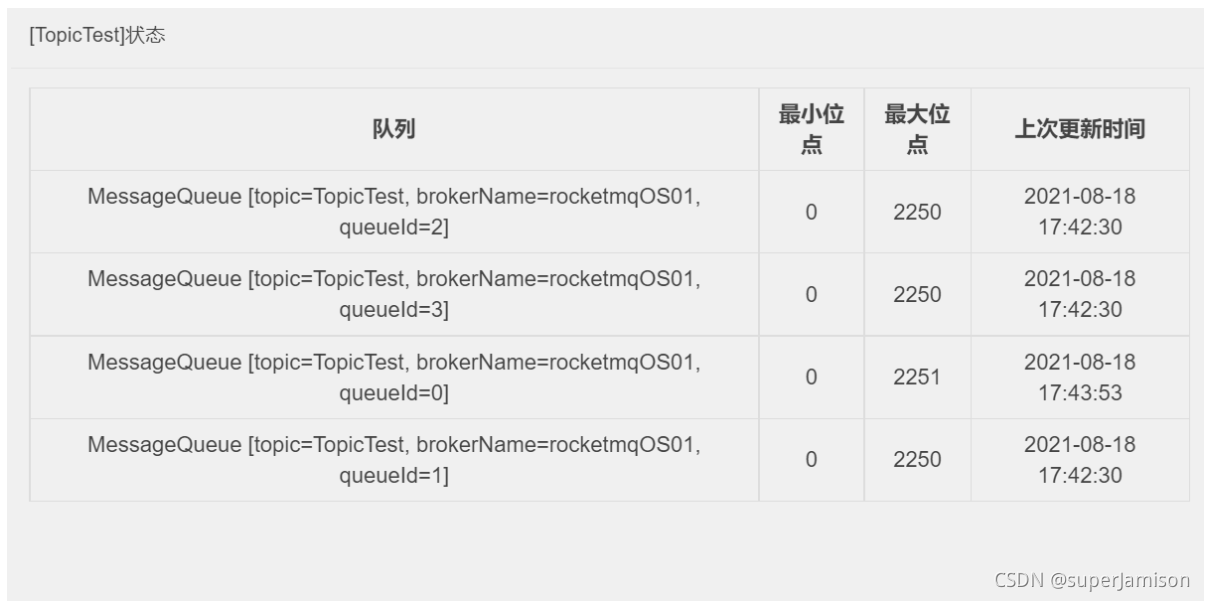
2、消息
可以参考“消息查询”这篇文章。
3、消息轨迹
可以参考“消息轨迹简介”这篇文章。
可以参考“查看消息轨迹”这篇文章。
五、集群搭建
1、集群搭建的理论
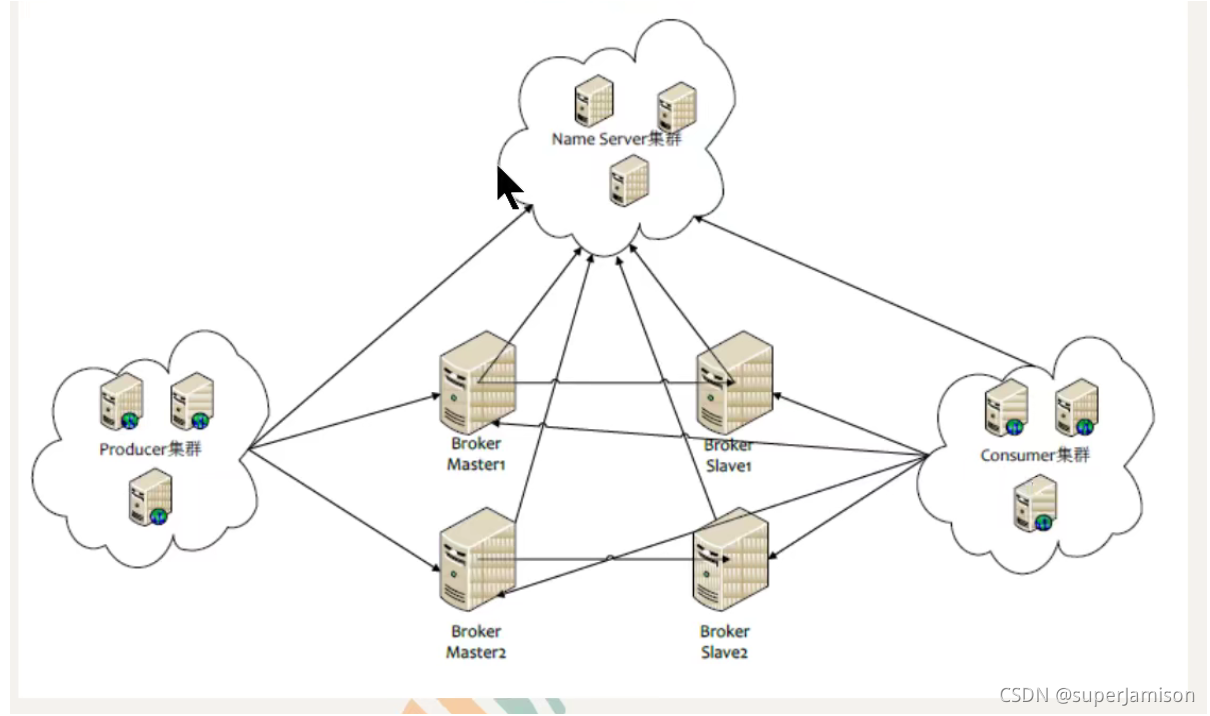
2、数据复制与刷盘策略
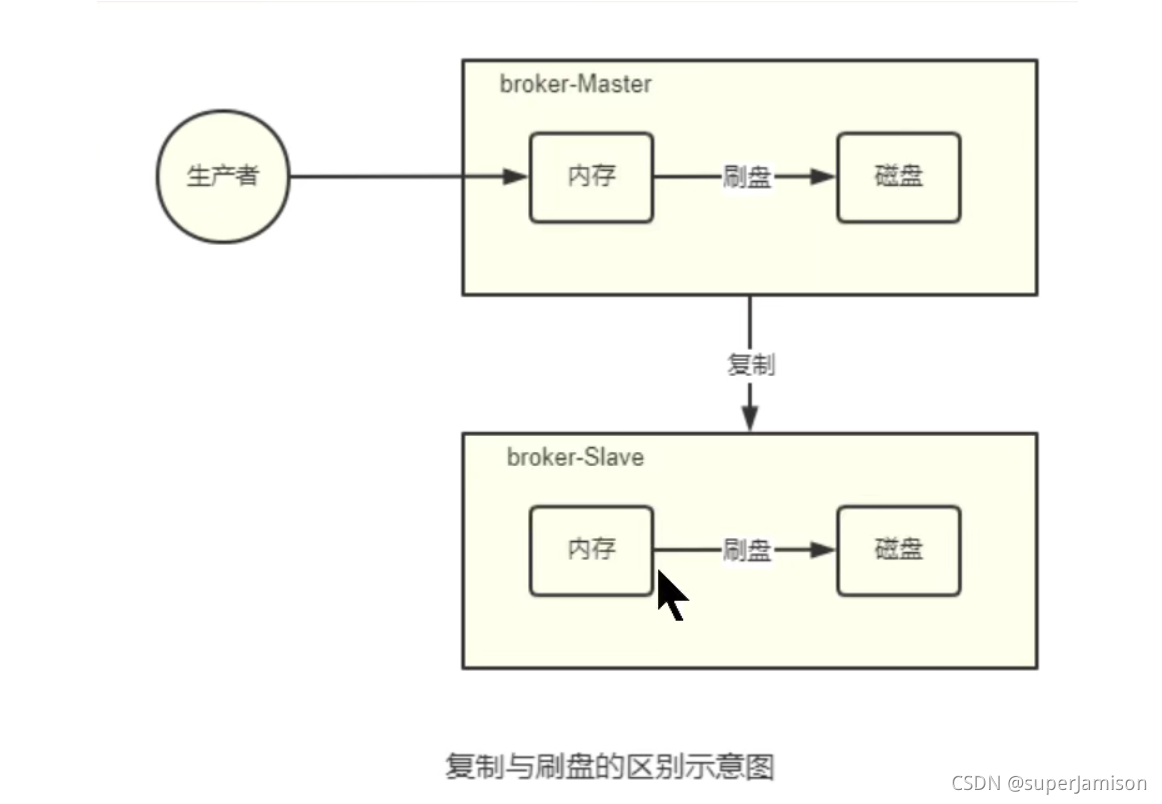
复制策略
复制策略是Broker的Master与Slave间的数据同步方式。分为同步复制与异步复制:
- 同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK。
- 异步复制:消息写入master后,master会立即向producer返回成功ACK,无需等待slave同步数据成功。
异步复制策略会降低系统的写入延迟,RT变小,提高系统的吞吐量。
刷盘策略
刷盘策略是指broker中的消息的落盘方式,即消息发送到broker内存后消息持久化到磁盘的方式。分为同步刷盘与异步刷盘:
- 同步刷盘:当消息持久化到broker的磁盘后才算消息写入成功。
- 异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到磁盘。
1)刷盘策略会降低系统的写入延迟,RT变小,提高系统的吞吐量。
2)消息写入到broker的内存,一般是写入到了PageCache
3、Broker集群模式
单Master
只有一个broker(其本质上就不能够称之为集群)。这种方式也只能在测试的时候使用,生成环境下不能使用,因为存在单点问题。
多Master
broker集群仅仅有多个master构成,不存在slave。同一Topic的各个Queue会平均分布在各个master节点上。
- 优点:配置简单,单个master宕机或重启维护对应用无影响,在磁盘配置为RAID10是,即使机器宕机不可恢复的情况下,由于RAID10磁盘非常可靠,消息也不会丢失(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
- 缺点:单台机器宕机期间,这台机器上未被消费的消息恢复之前不可订阅(不可消费),消息实时性会受到影响。
以上优点的前提是,这些Master都配置类RAID10磁盘阵列。如果没有配置,一旦出现某个Master宕机的话,则会发生大量的消息丢失的情况。
多Master多Slave模式-异步复制
broker机器由多个master构成,每个master又配置了多个slave(在配置RAID磁盘阵列的情况下,一个master一般配置一个slave即可)。master与slave的关系是主备关系,即master负责处理消息的读写请求,而slave仅仅负责消息的备份与master宕机后的角色切换。
异步复制即前面所讲到的**复制策略****中的 异步复制策略,即消息写入到master成功后,master立即向producer返回成功的ACK,无需等待slave的同步数据成功。
该模式的最大的特点之一是,当master宕机后slave能够自动切换为master。不过由于slave从master的同步具有短暂的延迟(毫秒级),所以当master宕机后,这种异步复制的方式可能会存在少量的消息丢失问题。
slave从master同步的延迟越短,其可能丢失的消息就越少
对于master的Raid磁盘阵列,若使用的也是异步复制策略,统一存在 延迟问题,同样也可能会丢失消息,但RAID阵列的秘诀是微妙级的(因为是有硬盘支持),所以其丢失数据量会更少。
多Master多Slave模式-同步双写
该模式是多Master多Slave模式的同步复制实现。所谓的同步双写,是指消息写入master成功后,master会等待slave同步数据成功后才向producer返回成功的ACK,即master与slave都要写入成功之后才会返回成功ACK,也即双写。
该模式与异步复制模式相比,优点是消息的安全性更高,不存在消息的丢失的问题,但单个消息RT略高,从而导致性能要略低(大约低10%)。
该模式存在一个大问题:对于目前的版本,Master宕机后,Slave不会自动切换到Master。
最佳实践
一般会为Master配置RAID10磁盘阵列,然后再为其配置一个Slave。即利用了RAID10磁盘阵列的高校、安全性,有解决了可能会影响订阅的问题。
1)RAID磁盘阵列的效率要高于Master-Slave集群。因为RAID是硬件支持的。也正是因为这样,所以RAID阵列的搭建成本非常高。
2)多Master+RAID阵列,与多Master多Slave集群的区别是什么?
多Master+RAID阵列,其仅仅可以保证数据不丢失,即影响消息的写入,但其可能会影响到消息的订阅。但其执行效率要远高于多Master多Slave集群
多Master多Slave集群,其不仅仅可能保证数据不丢失,也不会影响到消息的写入。其运行效率要低于多Master+RAID阵列
六、磁盘阵列RAID(补充)
1、RAID历史
1988年美国加州大学伯克利分校的D.A. Patterson教授等首次在论文“A Case of Redundant Array ofInexpensive Disks”中提出了RAID概念,即廉价冗余磁盘阵列(Redundant Array of Inexpensive Disks)。由于当时大容量磁盘比较昂贵,RAID 的基本思想是将多个容量较小、相对廉价的磁盘进行有机组合,从而以较低的成本获得与昂贵大容量磁盘相当的容量、性能、可靠性。随着磁盘成本和价格的不断降低,“廉价”已经毫无意义。因此, RAID咨询委员会(RAID’ Advisory Board,RAB)决定用“独立”替代“廉价”,于时RAID变成了独立磁盘冗余阵列( Redundant Array of Independent Disks )。但这仅仅是名称的变化,实质内容没有改变。
2、RAID等级
RAID这种设计思想很快被业界接纳,RAID技术作为高性能、高可靠的存储技术,得到了非常广泛的应用.RAID主要利用镜像、数据条市和数掂伙狐二什X八个不同的笙级、以满足不同数据应用的需求.据对这三种技术A使用策略和组合架构,可以把RAID分为不同的等级,以满足不同数据应用的需求.
D.A. Patterson等的论文中定义了RAIDO~RAID6原始RAID等级。随后存储厂商又不断推出RAID7、D.A. Patterson等的论文中定义了RAIDO~RAID6原始RAID等级。随后存储厂商又不断推出RAID7、RAID1、RAID3、RAID5、RAID6和RAID10。
RAID每一个等级代表一种实现方法和技术,等级之间并无高低之分。在实际应用中,应当根据用户的数据应用特点,综合考虑可用性、性能和成本来选择合适的RAID等级,以及具体的实现方式。
3、关键技术
4、RAID分类
5、常见RAID等级详解
七、集群的搭建
1、双主双从集群搭建
准备两台虚拟机192.168.80.60:9876;192.168.80.61:9876
选择配置双主双从异步模式的集群:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-81QNymdl-1630034007427)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210819091157505.png)]](https://img-blog.csdnimg.cn/b862e2d07df4448fabf69b7d80ac67e4.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
192.168.80.60的master配置
选择这个a的master
编辑broker-a.properties
[root@rocketmqOS01 2m-2s-async]# vim broker-a.properties
## 添加一下配置内容
namesrvAddr=192.168.80.60:9876;192.168.80.61:9876
192.168.80.60的slave配置
选择这个b的slave

编辑broker-b-s.properties
[root@rocketmqOS01 2m-2s-async]# vim broker-b-s.properties
## 添加一下配置内容
namesrvAddr=192.168.80.60:9876;192.168.80.61:9876
listenPort=11011
#存储路径
storePathRootDir=~/store-s
#commitLog 存储路径
storePathCommitLog=~/store-s/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=~/store-s/consumequeue
#消息索引存储路径
storePathIndex=~/store-s/index
#checkpoint 文件存储路径
storeCheckpoint=~/store-s/checkpoint
#abort 文件存储路径
abortFile=~/store-s/abort
192.168.80.61的master配置
选择这个b的master
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R8kLSwL4-1630034007429)(C:\Users\29829\AppData\Roaming\Typora\typora-user-images\image-20210819092108180.png)]](https://img-blog.csdnimg.cn/968c68270bf84c32879b21e4309b8572.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAc3VwZXJKYW1pc29u,size_20,color_FFFFFF,t_70,g_se,x_16)
编辑broker-b.properties
[root@rocketmqOS02 2m-2s-async]# vim broker-b.properties
## 添加一下配置内容
namesrvAddr=192.168.80.60:9876;192.168.80.61:9876
192.168.80.61的slave配置
选择这个a的slave

编辑broker-a-s.properties
[root@rocketmqOS02 2m-2s-async]# vim broker-a-s.properties
## 添加一下配置内容
namesrvAddr=192.168.80.60:9876;192.168.80.61:9876
listenPort=11011
#存储路径
storePathRootDir=~/store-s
#commitLog 存储路径
storePathCommitLog=~/store-s/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=~/store-s/consumequeue
#消息索引存储路径
storePathIndex=~/store-s/index
#checkpoint 文件存储路径
storeCheckpoint=~/store-s/checkpoint
#abort 文件存储路径
abortFile=~/store-s/abort
启动集群服务
## 启动nameserver
nohup ./bin/mqnamesrv &
tail -f ~/logs/rocketmqlogs/namesrv.log
## 启动对应的broker
nohup ./bin/mqbroker -c ./conf/2m-2s-async/broker-a.properties &
tail ~/logs/rocketmqlogs/broker.log
上传本地文件到远程主机
## 将本地文件上传到远程主机
scp name_stop.sh root@192.168.80.61:/rocketmq/rocketmq_install/rocketmq-all-4.9.0-bin-release/














 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









