






一、需求背景
云服务项目,MySQL水平分库,由于各种历史原因,各个分库的数据量不均衡,新增分库数据量低,需要一种负载均衡算法能自动平衡数据分布
二、解决方案
基于数据库权重的负载均衡算法
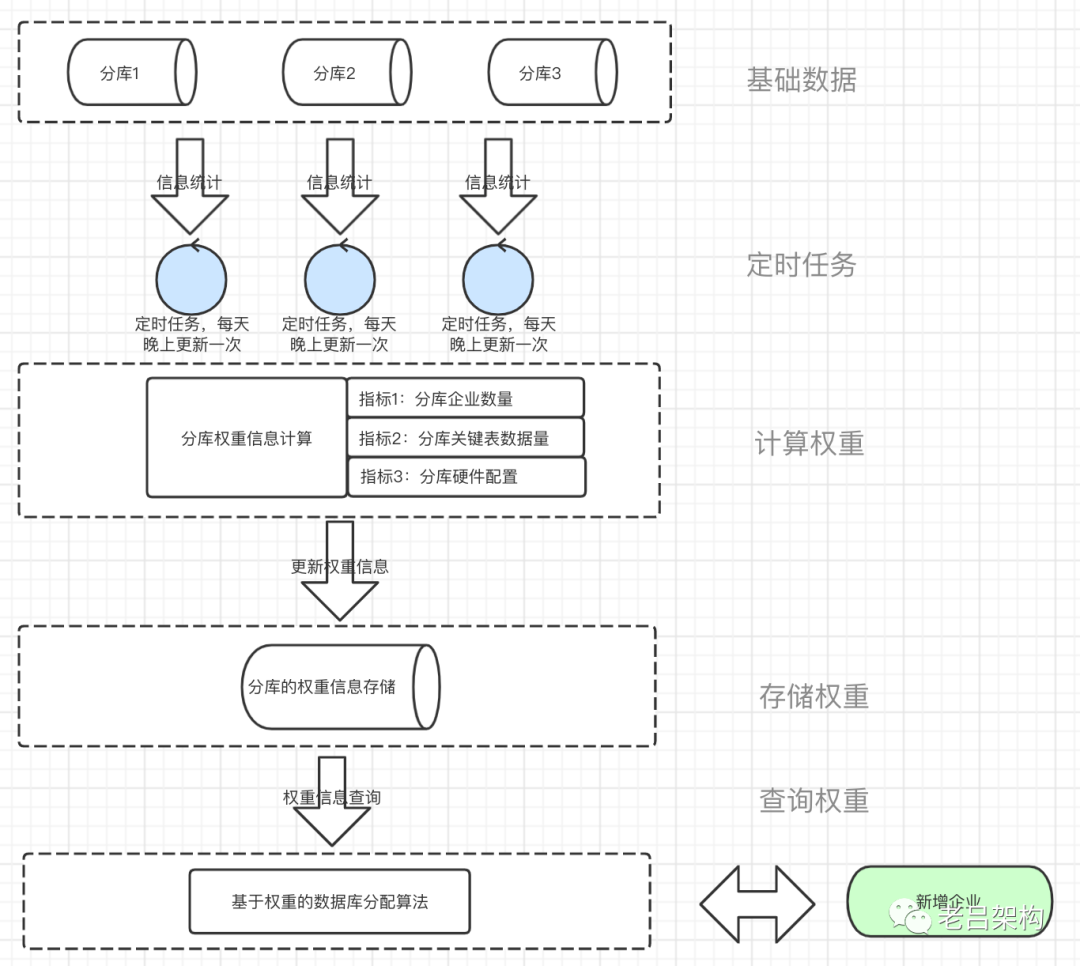
三、代码实现
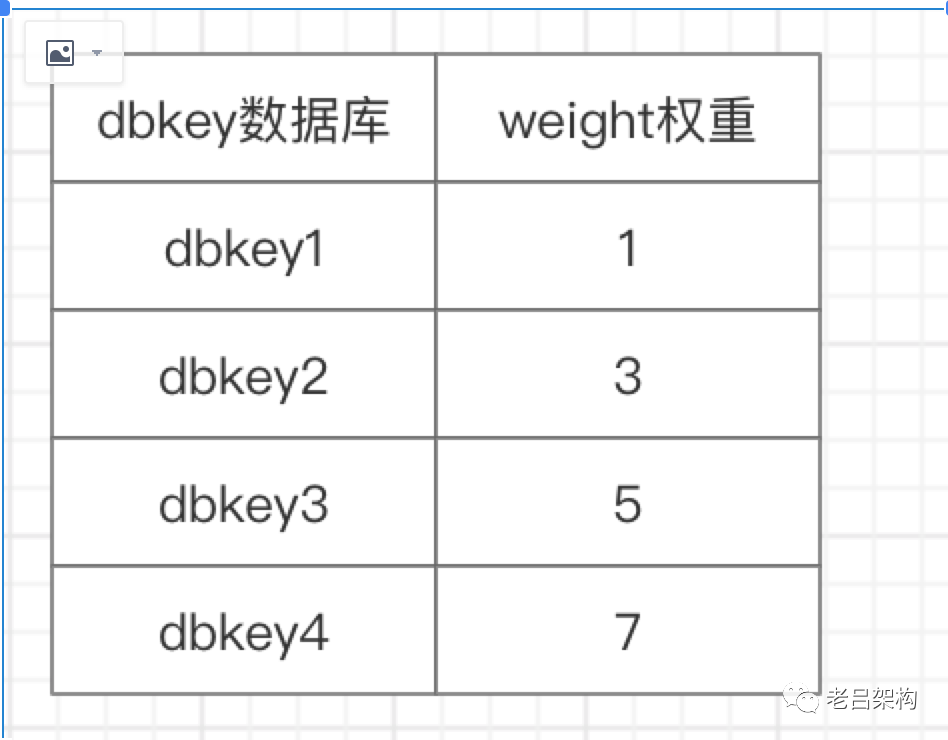
权重存储结构表
定时同步权限信息的任务
基于权重的负载均衡算法
public class DbKeyWeightDto implements Serializable {
private static final long serialVersionUID = -5196176232082947951L;
public DbKeyWeightDto() {
}
public DbKeyWeightDto(String dbkey, Integer weight) {
this.dbkey = dbkey;
this.weight = weight;
}
private String dbkey;
private Integer weight;
}
public class ByWeight {
/**
* 测试
* @param args
*/
public static void main(String[] args) {
ArrayList<DbKeyWeightDto> weightList = getWeightList();
for (int i = 0; i <10000 ; i++) {
DbKeyWeightDto dto = selectOne(weightList);
System.out.println(dto.getDbkey());
}
}
/**
* 负载均衡算法
* @param weightList
* @return
*/
private static DbKeyWeightDto selectOne(ArrayList<DbKeyWeightDto> weightList) {
int size = weightList.stream().mapToInt(DbKeyWeightDto::getWeight).sum();
int[] tempArray = new int[size];
int i=0;
for (int i1 = 0; i1 < weightList.size(); i1++) {
int weight = weightList.get(i1).getWeight();
for (int j = 0; j <weight ; j++) {
tempArray[i]=i1;
i++;
}
}
Random random = new Random();
return weightList.get(tempArray[random.nextInt(size)]);
}
/**
* 计算权重信息
* @return
*/
private static ArrayList<DbKeyWeightDto> getWeightList() {
//模拟定时任务统计获取分库的企业数量数据
ArrayList<DbKeyWeightDto> dbKeyWeightDtos = new ArrayList<>();
Random random = new Random();
for (int i = 1; i <=4 ; i++) {
dbKeyWeightDtos.add(new DbKeyWeightDto("dbkey"+i,random.nextInt(100)));
}
//排序
Collections.sort(dbKeyWeightDtos,(a1, a2)->{
if (a1.getWeight()==null) {
a1.setWeight(0);
}
if (a2.getWeight()==null) {
a2.setWeight(0);
}
return a1.getWeight()-a2.getWeight();
});
//首尾权重对调
for (int i = 0; i < dbKeyWeightDtos.size()/2; i++) {
Integer temp = dbKeyWeightDtos.get(i).getWeight();
dbKeyWeightDtos.get(i).setWeight(dbKeyWeightDtos.get(dbKeyWeightDtos.size()-1-i).getWeight());
dbKeyWeightDtos.get(dbKeyWeightDtos.size()-1-i).setWeight(temp);
}
return dbKeyWeightDtos;
}
}四、总结
1、定时任务有多种方案,我就不写代码了,知道思路就行了;
2、统计数据量的时候要最终转换为百分比下的相对数量;
3、数据量越大的分库,权重值应该越小,所以要按数据量的百分比排序后,再首尾对调才是正确的权重值;
4、负载均衡算法的思路是:
1)产生一个数组大小等于各个分库的权重之和(一定要用百分比相对数据量哦,否则数组就太大了);
2)按权重值给每个分库分配数组格子的数量,格子的内容是list的元素索引;
3)产生数组大小以内的随机数;
4)这就选出来了一个list元素索引,可以进一步得到dbkey的值;
5、新增数据库的特殊情况,这时候计算权重信息时注意不能漏掉它,它的初始数据量为0,计算完权重信息后,它的权重值应该是最大的就对了,另外同时数据量最大的那个分库的权重值会是0,这是符合预期的,因为首尾对调的原因。随着新增分库数据的增加,就会慢慢趋于平衡;
6、权重值的计算部分有很多策略和指标可以进行复杂扩展,各位同学要根据自己项目的实际情况使用不同的指标和策略计算权重值;
















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











