







在单体架构中,我们的事务可以通过数据库的ACID来操作,不会出现什么问题
但随着规模扩大,我们的逻辑服务进行拆分A,B,C…模块,部署在多台服务器,数据库一般也是多台,进行了分库分表等操作,这些A,B,C…模块间通过网络通信完成协作,此刻就产生了单体应用触发不了的问题:
- 一致性问题: 既然是多个数据库,那么通过网络操作,客观上就会存在延时(短距离很小,当跨国时就很慢了)甚至不可达,
- 可用性问题:用户访问某个页面,应该给提供可预期的结果,而不是浏览器报错,可以通过一些策略完成
- 网络分区:在分布式场景中,不可避免的会出现多个模块系统协同工作,根据墨菲定律,就一定有几率发生网络中断、延时、不可达等客观存在问题
这三个问题也是分布式事务关注的核心问题:CAP理论
1. 分布式理论
1.1 CAP定理
- 一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability) : 每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
具体地讲在分布式系统中,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性
显然,任何横向扩展策略都要依赖于数据分区
因此,设计人员必须在一致性与可用性之间做出选择(二选一)
1.2 CAP的三种组合
分布式系统中,为了提高强一致性,应该使用更少的节点,这样更容易同步消息,而为了提高可用性,不得不增加节点,保证高可用,矛盾,所以需要取舍
-
CA:保证可用性和一致性,放弃分区
除非不是分布式架构,或者应用在一个永不会通信故障的网络中(理想),只有个别场景符合,当前的互联网架构显然不符合使用
-
CP:保证一致性和分区容忍性,放弃可用性
当节点间不可通信时,进行阻塞,直到通信恢复,期间无法再对外提供服务,用户体验不好,如A转账给B,只有A扣款成功并B收款成功,整个事务才算完成,显然耗费资源
-
AP:保证可用性和分区容忍性,放弃强一致性(使用最终一致性)
给出一个用户可以忍受的时间,时间内达成数据的最终一致性,比如跨行转账,并不是立刻到账,可能是明天,或者2小时内到账
1.3 BASE理论
在分布式系统中,我们往往追求的是可用性,它的重要程序比一致性要高,那么如何实现高可用性呢?
前人已经给我们提出来了另外一个理论,就是BASE理论,它是用来对CAP定理进行进一步扩充的
BASE理论指的是:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)
2. 分布式事务
在分布式系统中,要实现分布式事务,无外乎以下解决方案
2.1 两阶段提交(2PC)
两阶段提交就是使用XA协议的原理,我们可以从下面这个图的流程来很容易的看出中间的一些比如commit和abort的细节
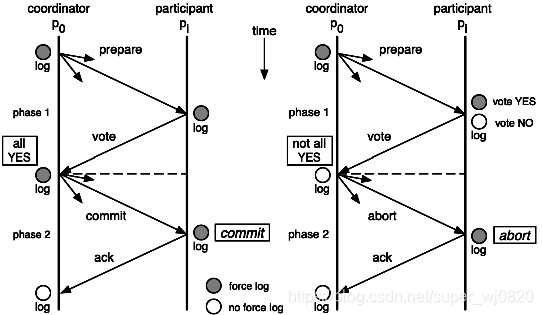
XA 是一个两阶段提交协议,该协议分为以下两个阶段:
- 第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段:事务协调器要求每个数据库提交数据。
其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息
两阶段提交这种解决方案属于牺牲了一部分可用性来换取的一致性:整体可用性=每个数据库的可用性的乘积
优点: 尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
缺点: 实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景,如果分布式系统跨接口调用
2.2 补偿事务(TCC)
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作
它分为三个阶段:
-
Try 阶段主要是对业务系统做检测及资源预留
-
Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
-
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
举个例子,假入 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
1、首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
2、在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
3、如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点: 缺点还是比较明显的,在2,3步中都有可能失败
TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理
2.3 本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay
我们可以从下面的流程图中看出其中的一些细节:
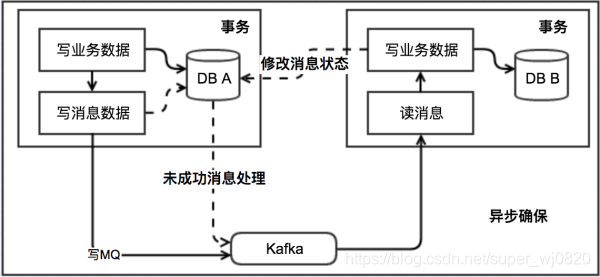
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。在 .NET中 有现成的解决方案
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理
2.4 MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如 Kafka、RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交
关于Kafka的事务,参考:Kafka 0.11后幂等性和事务的基本原理和流程
优点: 实现了最终一致性,不需要依赖本地数据库事务














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









