










文章目录
1. 下载安装Ollama
打开ubuntu终端,执行:curl -fsSL https://ollama.com/install.sh | sh
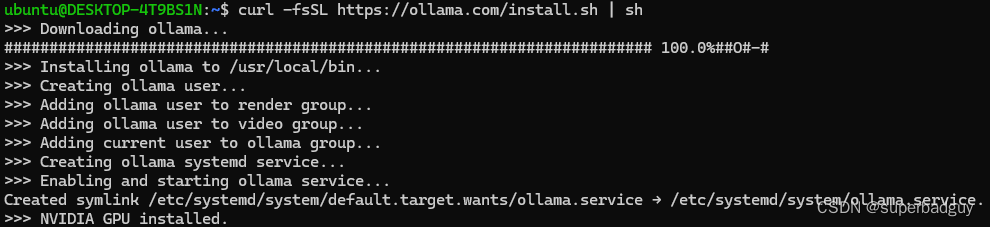
安装成功后,默认ollama已经运行在后台
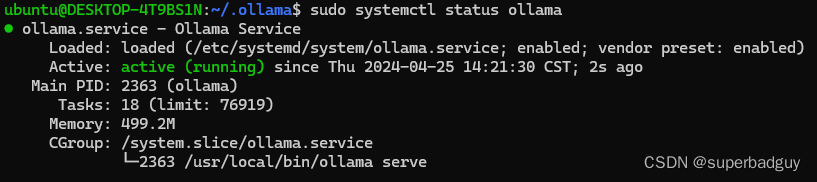
- 查看状态:
sudo systemctl status ollama
- 查看进程:
sudo ps -ef | grep -v color | grep ollama
- 查看端口
- 先安装:
sudo apt install net-tools - 查看:
sudo netstat -anp | grep 11434
- 先安装:
2. 下载模型
-
查看本地模型:
ollama list

本地还没有模型 -
下载llama3:
ollama pull llama3 -
查看现有模型:
ollama listNAME ID SIZE MODIFIED llama3:latest a6990ed6be41 4.7 GB 2 minutes ago
3. 访问
- API请求方式
或者curl http://localhost:11434/api/chat -d '{ "model": "llama3", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }'# 安装json解析工具 sudo apt update && sudo apt install jq -y # 非流式访问,并将结果用json格式输出 curl -s http://localhost:12345/api/chat -d '{ "model": "llama3", "messages": [ { "role": "user", "content": "你好?" } ], "stream": false }' | jq - 交互式对话:
ollama run llama3 python代码- 安装langchain:
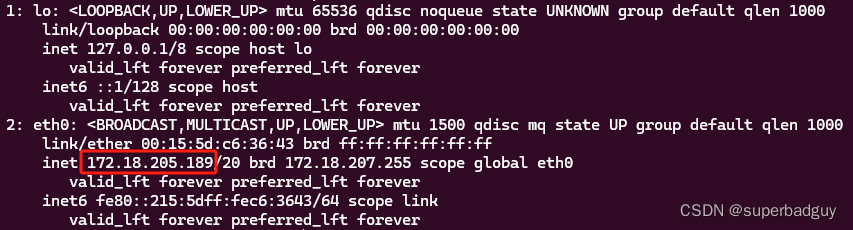
pip install -U langchain - 查看ollama服务的IP:
ip addr
- 运行
from langchain.llms.ollama import Ollama from langchain.chat_models.ollama import ChatOllama llm = Ollama(model="llama3", base_url='http://172.18.205.189:12345') print(llm.invoke('hello')) chat = ChatOllama(model="llama3", base_url='http://172.18.205.189:12345') print(chat.invoke('hello'))
- 安装langchain:
4. 自定义模型存放和运行
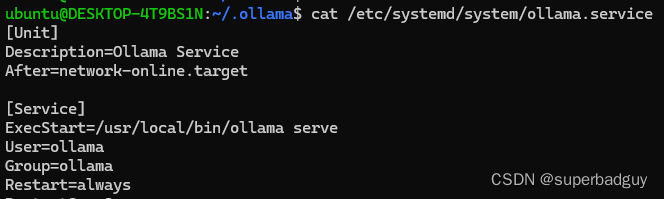
4.1. ollama用户启动
ollama服务默认以ollama用户启动运行在后台
- 直接使用
ollama pull <模型名>下载模型时,它会存于/usr/share/ollama/.ollama/models/下,执行:du /usr/share/ollama/.ollama/models/ -d 1 -h20K /usr/share/ollama/.ollama/models/manifests 4.4G /usr/share/ollama/.ollama/models/blobs 4.4G /usr/share/ollama/.ollama/models/
4.2. 当前用户运行
- 执行
ollama serve开启ollama服务,它是以当前用户启动运行的,会在用户的home目录下创建.ollama文件夹。
相当于执行OLLAMA_HOST=127.0.0.1:11434 ollama serve,所以当11434被占用了,就会报Error: listen tcp 127.0.0.1:11434: bind: address already in use。 - 指定监听所有IP和指定端口:
OLLAMA_HOST=0.0.0.0:<端口> ollama serve - 执行
ollama pull <模型名>时,相当于执行OLLAMA_HOST=http://localhost:11434 ollama pull <模型名>,若当前是ollama是以ollama用户启动的,则它会将模型下载到/usr/share/ollama/.ollama/models/中,若是以当前用户启动的,则会下载到~/.ollama/models/blobs中 - 执行
ollama list,没指定OLLAMA_HOST环境变量,也是同ollama pull一样,使用默认值
4.3. 自定义模型存放目录
- 第一种方式:
启动时指定模型路径:OLLAMA_MODELS=/mnt/d/models/.ollama/models OLLAMA_HOST=0.0.0.0:12345 ollama serve - 第二种方式:
- 在执行
ollama serve后,将~/.ollama文件夹直接剪切到另一个地方,比如/mnt/d/models/ - 删除
~/.ollama文件夹 - 建立软链接:
ln -s /mnt/d/models/.ollama ~/.ollama

- 启动:
OLLAMA_HOST=0.0.0.0:12345 ollama serve
- 在执行
- 执行
OLLAMA_HOST=http://127.0.0.1:12345 ollama pull qwen下载模型,它就会将模型下载到/mnt/d/models/.ollama/models中 - 查看本地模型:
OLLAMA_HOST=http://localhost:12345 ollama list

5. 运行多个模型
ollama好像和fastchat不一样,一次只能启动一个模型,当访问另一个模型时,它就会自动卸载当前模型加载另一个模型。所以土办法是启多个服务,每个服务只让访问一个模型?
6. Troubleshooting
6.1. bind: address already in use
执行ollama serve时,报

说明端口已经被占用
- 要么使用
sudo netstat -anp | grep <端口>,找出使用该端口的进程,将其kill掉 - 要么指定端口启动:
OLLAMA_HOST=0.0.0.0:12345 ollama serve
6.2. Connection refused
执行
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
报curl: (7) Failed to connect to localhost port 11434 after 0 ms: Connection refused,说明ollama服务没有启动
- 以ollama用户启动:
sudo systemctl start ollama - 以当前用户启动:
OLLAMA_HOST=0.0.0.0:11434 ollama serve















 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









