










作者:taco
目录
在项目中,会出现一种情况,三维场景中存在大量的重复对象。而按照常规的缓存方式,这样的对象会导致最终的缓存结果很大。比如铁路场景中,枕木、扣件等对象、或是电力场景中绝缘子串等细小构件都会造成这种情况的发生。那么针对这些类型数据应该如何处理呢?有什么好的解决方案么?
本篇文章针对这种情况来提供一种处理思路
一、实例化
1.1 实例化模型
当一个相同的模型重复使用了多次的话,我们可以称之为“使用了多次”。但是当一个模型只存储了一次,又重复使用了多次的话,我们可以称之为“实例化模型”。
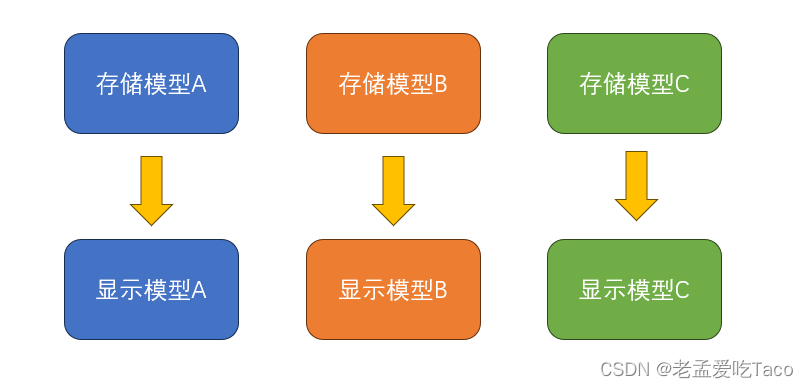
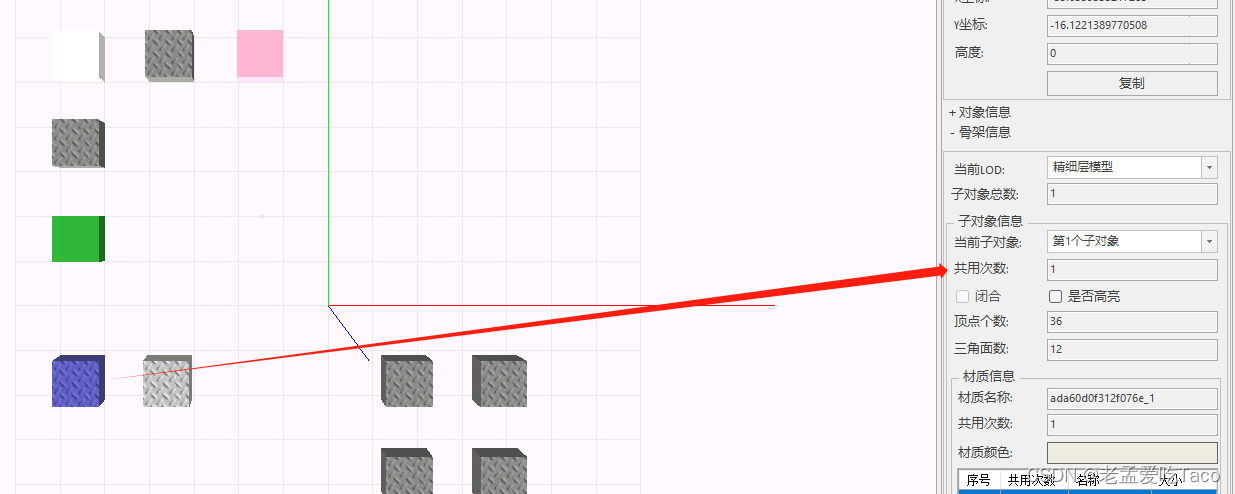
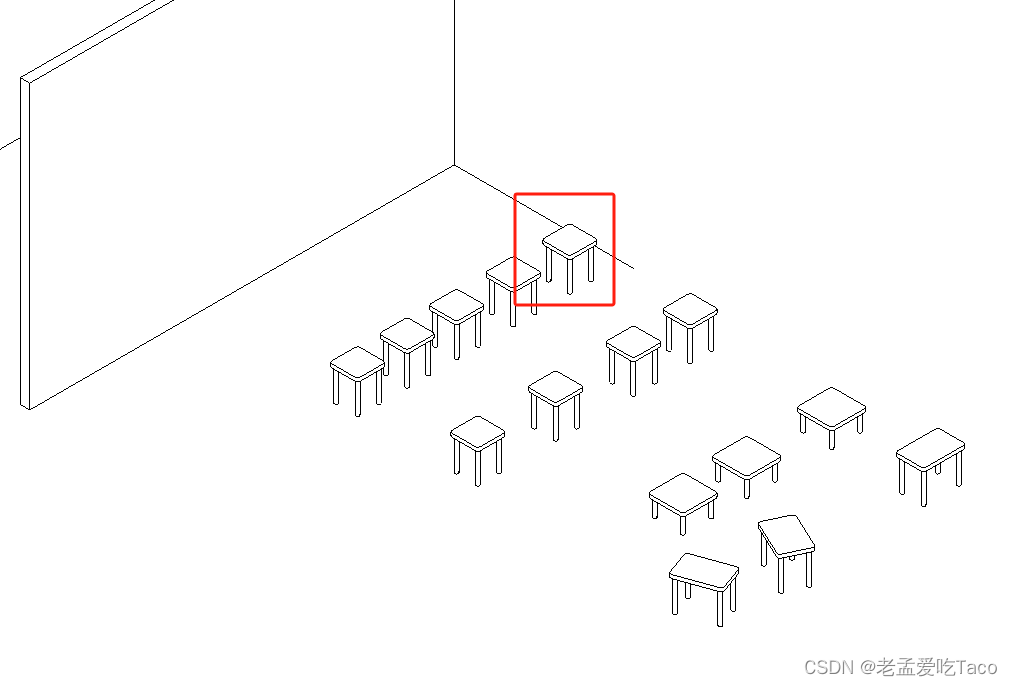
图一:使用了多次
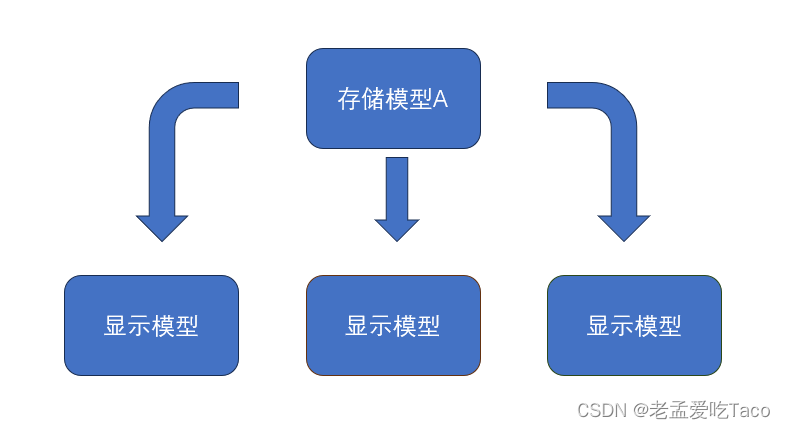
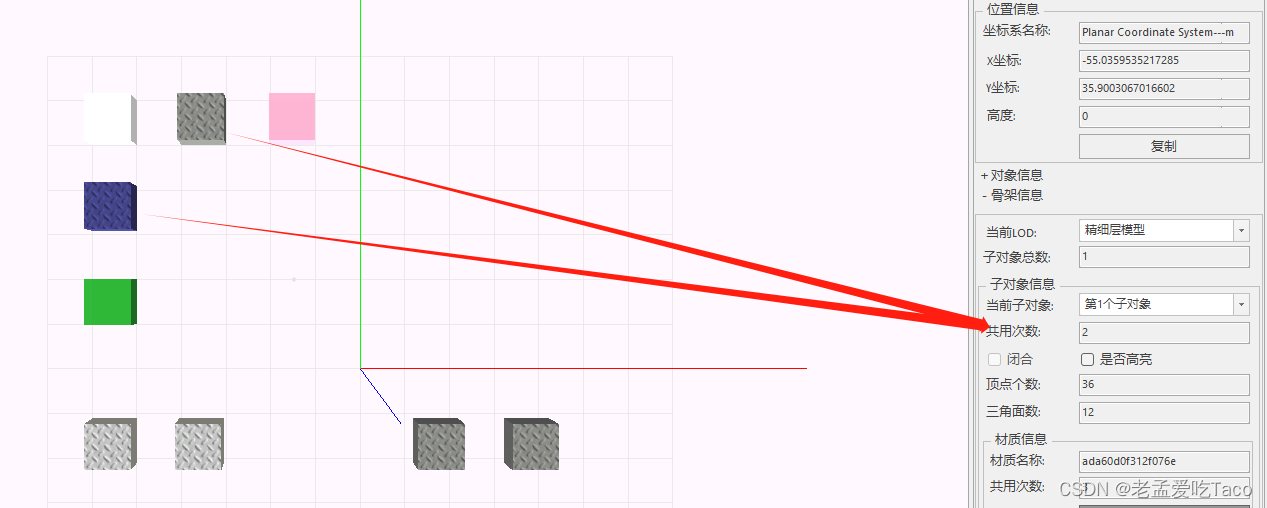
图二:实例化模型
当我们将模型处理为实例化对象后,能大大的降低存储使用的空间。在内存中也只需要存储一个对象,而对象的位置、大小、角度仅通过矩阵信息来调整即可。
1.2 iDesktop&实例化对象
那么在产品中,如何判断一个对象是实例化模型呢?
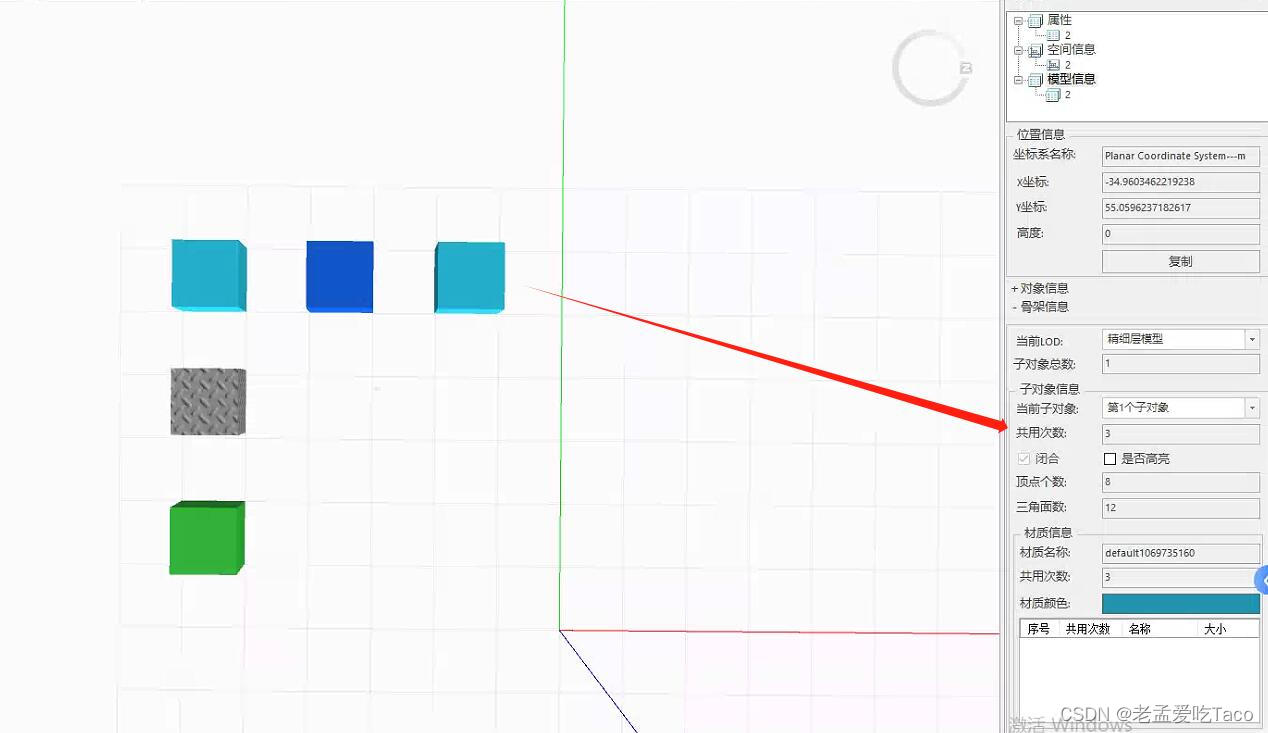
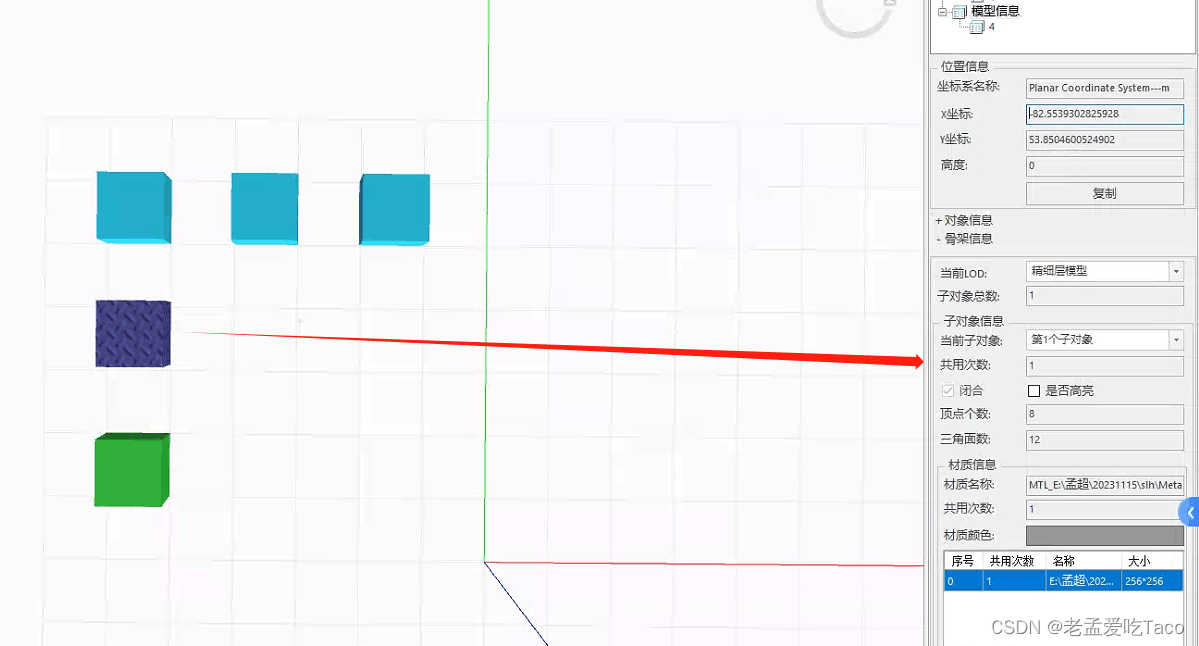
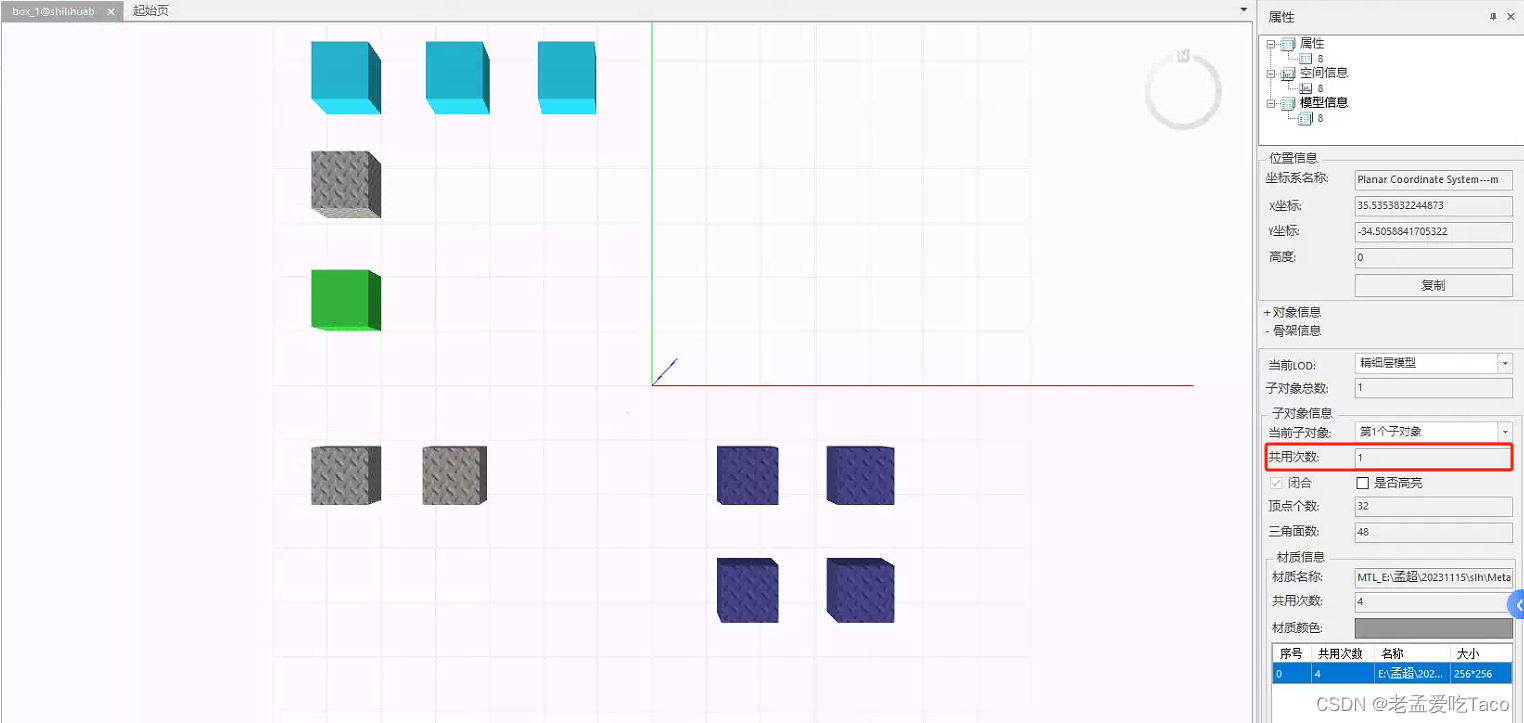
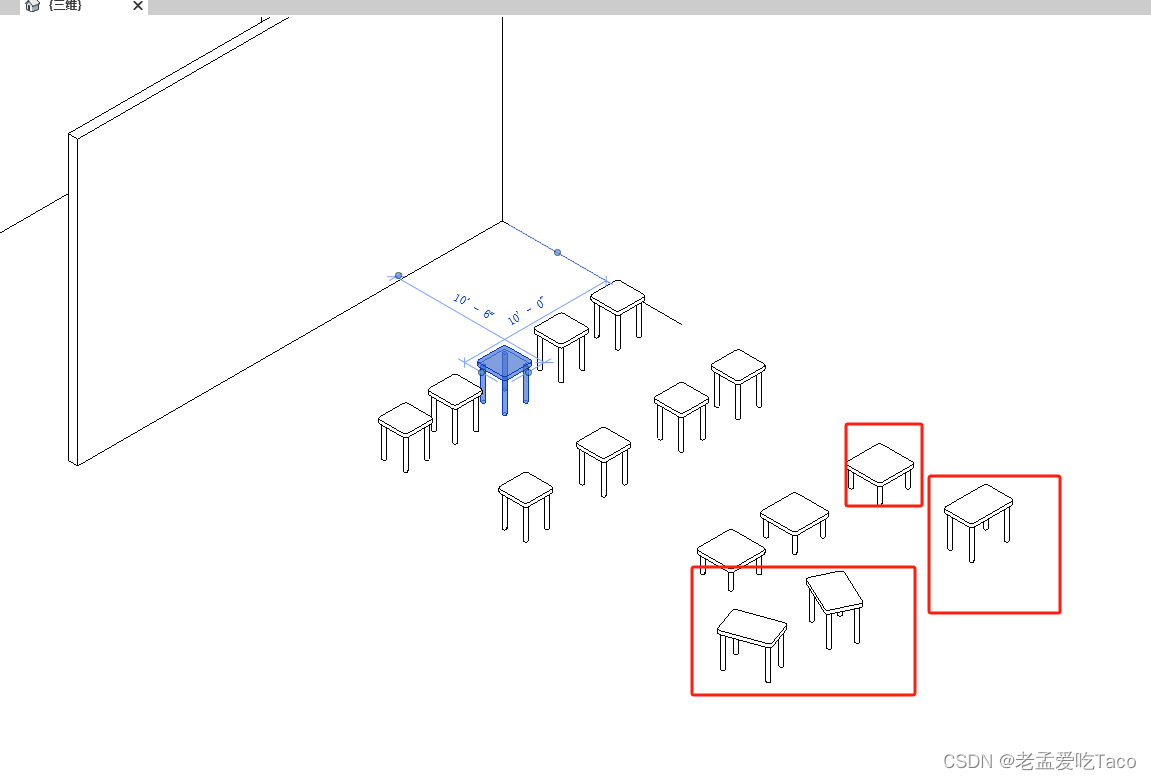
我们可以右键单击模型属性中区看到它的【模型信息】,这里子对象信息也就是当前的共用次数。
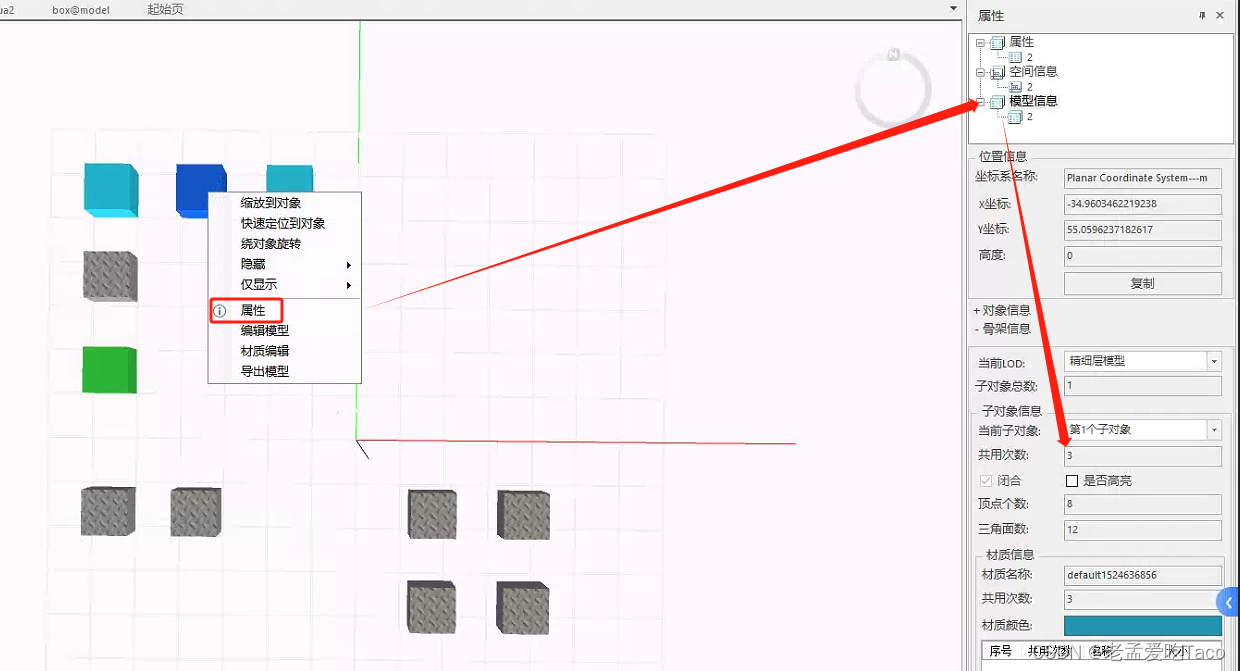
什么类型的数据算是实例化模型呢?在产品中通过模型的骨架、材质、纹理三者共同确定了模型是否复用。
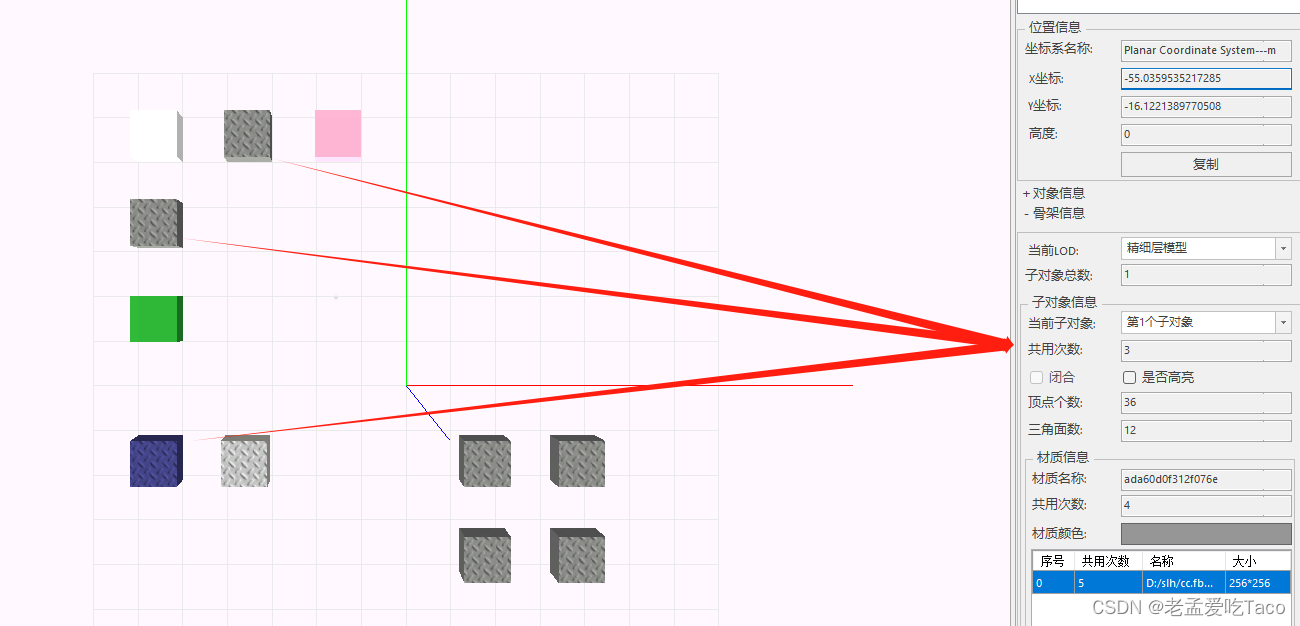
在上图中我们可以看到这三个模型对象是复用关系的,但是当我们去修改选中的材质后(见下图),瓦片,我们会惊喜的发现,只剩两个模型是公用的,所以实例化的三个信息缺一不可。
二、建模软件与实例化
在其他软件中实例化又是如何定义的呢?以及导出的关系又是什么呢?此处以常用的Max、Revit、Bentley三个建模软件来举例说明。
2.1 3ds Max
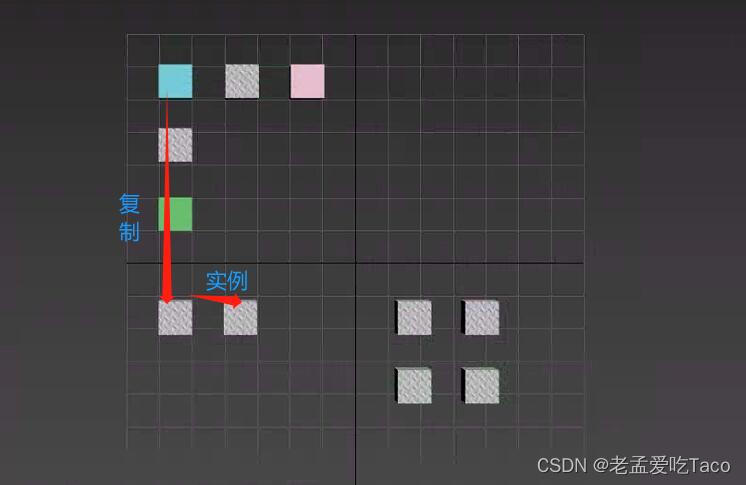
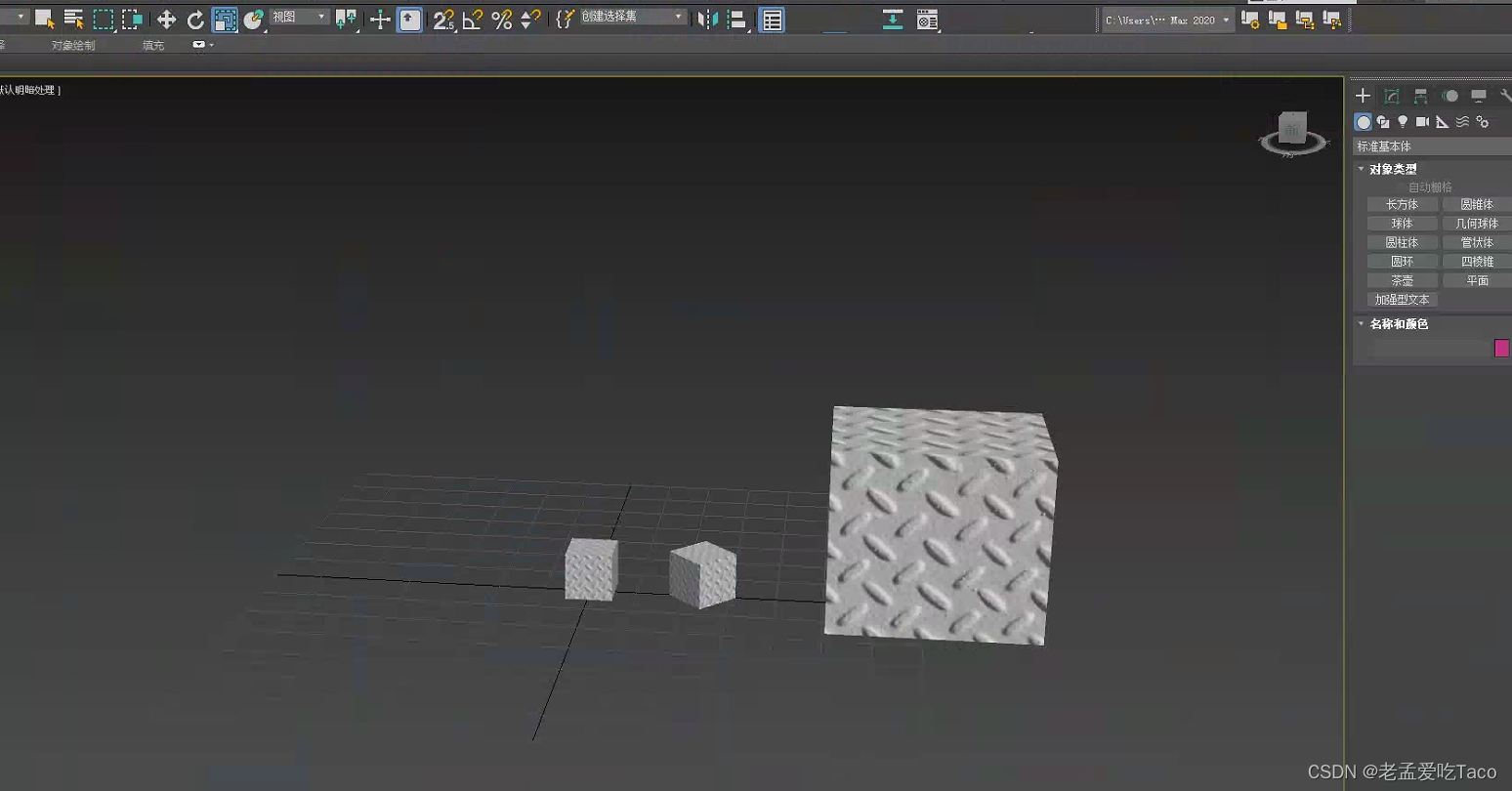
在3ds Max软件中,并没有同一个类型的概念,当我一个对象要Copy的时候直接Ctrl+V就完全能够实现的了。但是在我们复制的时候会出现一个选项让我们选择复制&实例(见下图)。
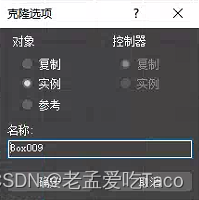
针对整两个参数我们来进行一个简单的测试。我在场景中创建了一个10*10*10的正方体,以该正方体为模板进行复制&实例 。
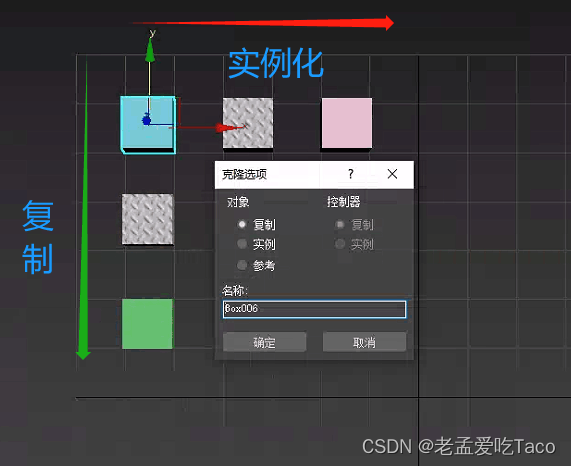
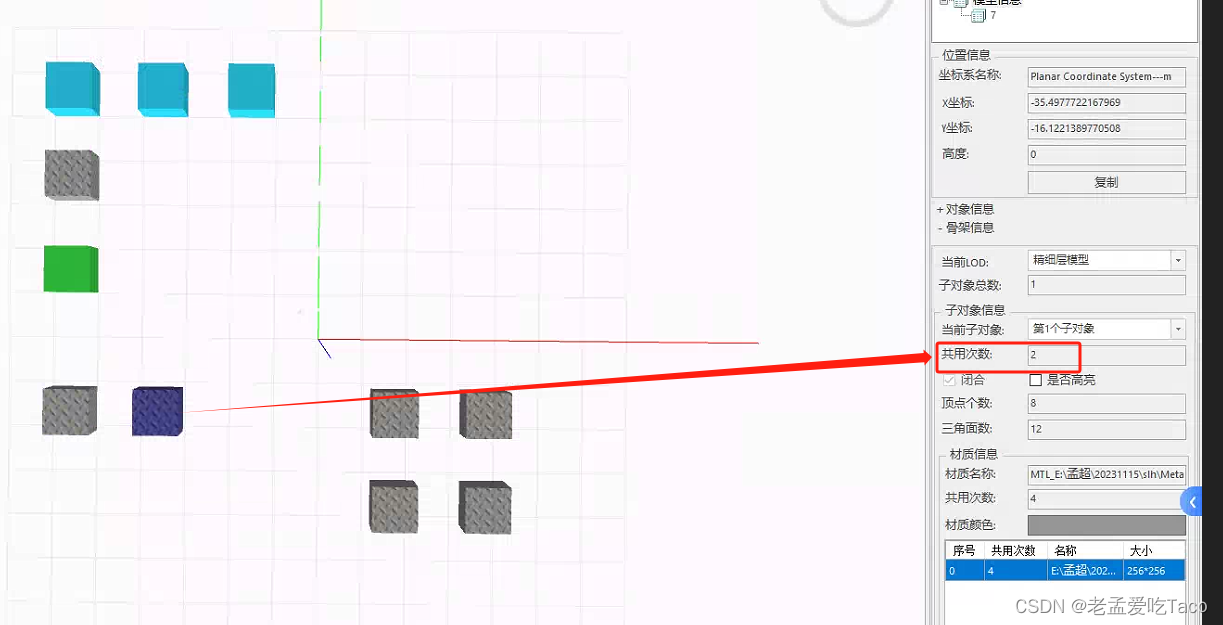
上图中,我们使用原始的box盒子横向进行实例操作,纵向进行复制操作。在操作后,我们修改实例(复制) box1的材质贴图、修改实例(复制) box2的材质。
综上我们整理一下表格,会发现在max软件中本事实例的模型在去设置贴图材质,从max导出插件中是导不出的。导出来的数据仅与原始的模型有关也就是原始的无贴图无材质的数据。
与此同时,我们根据原始的模型复制的模型,是完全能够导出其材质、贴图、纹理的。但是数据就不包含实例化信息了。也就是说相当于两个模型啦!

那么模型就不能有贴图纹理了么?答案当然是:No !No !No!
我们优先对原始(无贴图纹理)数据,进行复制。复制后直接给该数据设置材质,贴图,纹理后,在copy 实例出一个新的模型,就能将材质信息导出的,同时还包含了实例化信息。
这样就很优秀的将实例化信息写入了模型。不过下面有一个特殊情况,也是最近遇到关于建模人员使用上的问题。在max建模的过程中,为了减少对象的数量。通常都会以附加的方式,将很多复用的对象附加到一个对象上面。
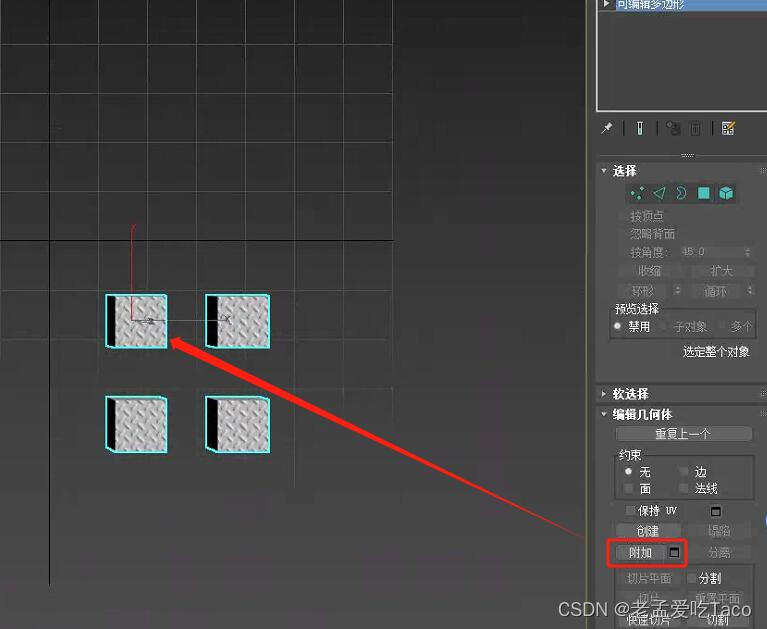
这样会按照一个对象导出,而其中的子对象并不会保留实例信息,所以相同对象不要附加!不要附加!不要附加!能打组就打组就好了!
然而Max里面却有另一个问题,多个对象之间如果有穿插,模型与模型之间有重合部分,这样的对象是不按照实例化处理的。所以如果一个建筑、任务、构建、是由多个对象组成的。需要将其附加成一个对象后,在创建实例。这样的实例是可以正常导出的。而附加后单独对象均按照子对象存储到父对象身上的。
不是只有一模一样的模型叫实例化模型!我们定义实例模型始终只有那三个参数骨架、材质、纹理。所以当我们在max中创建一个实例模型后,平移,旋转,缩放都是可以的,这些并不会修改其骨架信息,而是修改其矩阵信息。

iDesktop与3ds Max的关联就这些了。当然还有一些关于插件导出的问题。我们后面在说。
2.2 Revit
Max中的搞懂了以后,其实再其他软件中就相对来说类似了。不过在Revit软件中,我们用到了一个新的东西“族”。族在Revit中是一个很重要的概念,是由“family”翻译过来的,其实它本身就相当于一个集合。
而Revit中也包含了很多这种集合例如墙、门、楼梯等。而族内部按照不同规格(材料、尺寸)细分为不同的“类型”。而我们根据某一个类型去创建的单独的一个模型,就可以称之为一个“实例”。这样子我们就回到了一开始所说的实例啦!
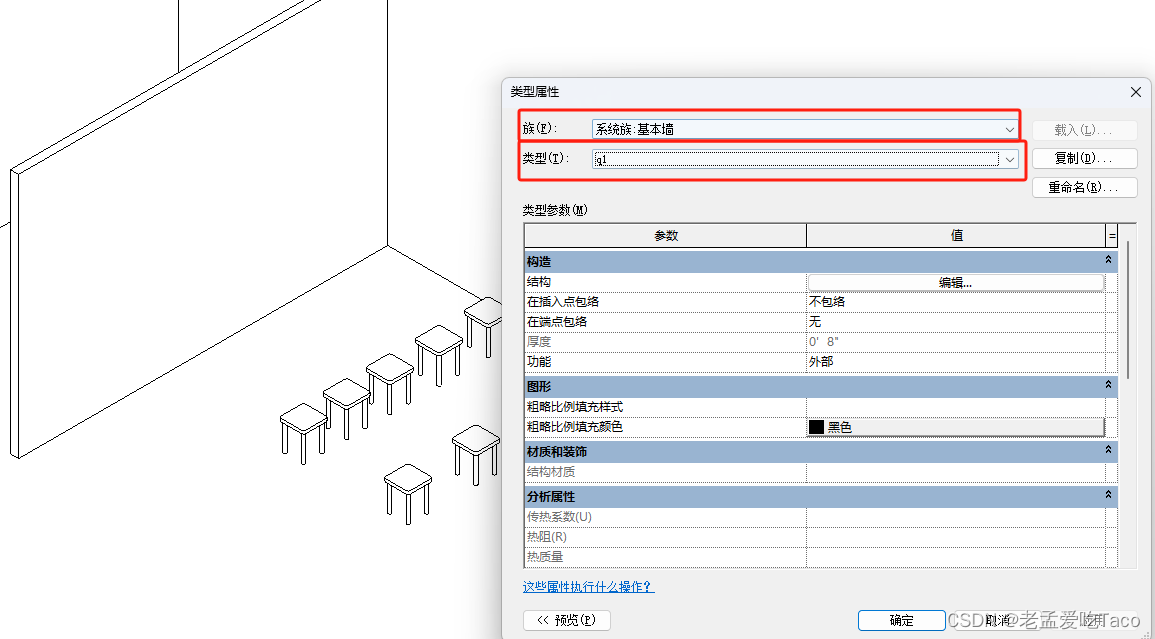
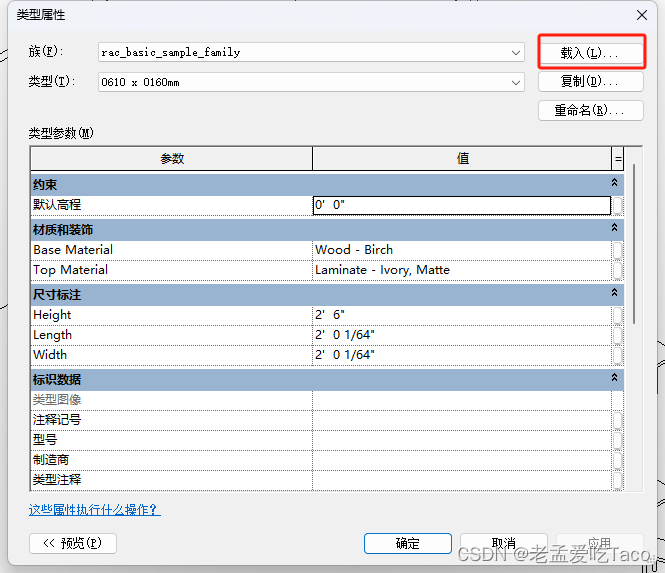
在Revit中根据族的可编辑性又分为三种:系统族,内建族,可载入族。而与我们实例化相关的只有可载入族,而其他两个族并不参数实例化。我们载入一个本地的.rfa文件来使用。
在载入后我们可以在场景中直接使用这个族创建单个实例。
也可以修改其中的类型,在创建其他尺寸的实例模型。或是旋转其中的模型。

当我们导出后,可以看到。每一个载入族实例都直接做了复用,而仅与类型有关。同时可以观察到系统族(墙)虽然看起来一样但是并不参与复用。


2.3 Bentley
Revit里面用“族”,那么Bentley里面用什么呢?没错就是你想的那个“共享单元”!!!
在MicroStation CONNECT Edition中,没有过于复杂的复制粘贴,实例问题。所有的实例都是通过共享单元拿来的。我们通过【内容】中的【放置激活单元】来添加我们的共享单元即可。
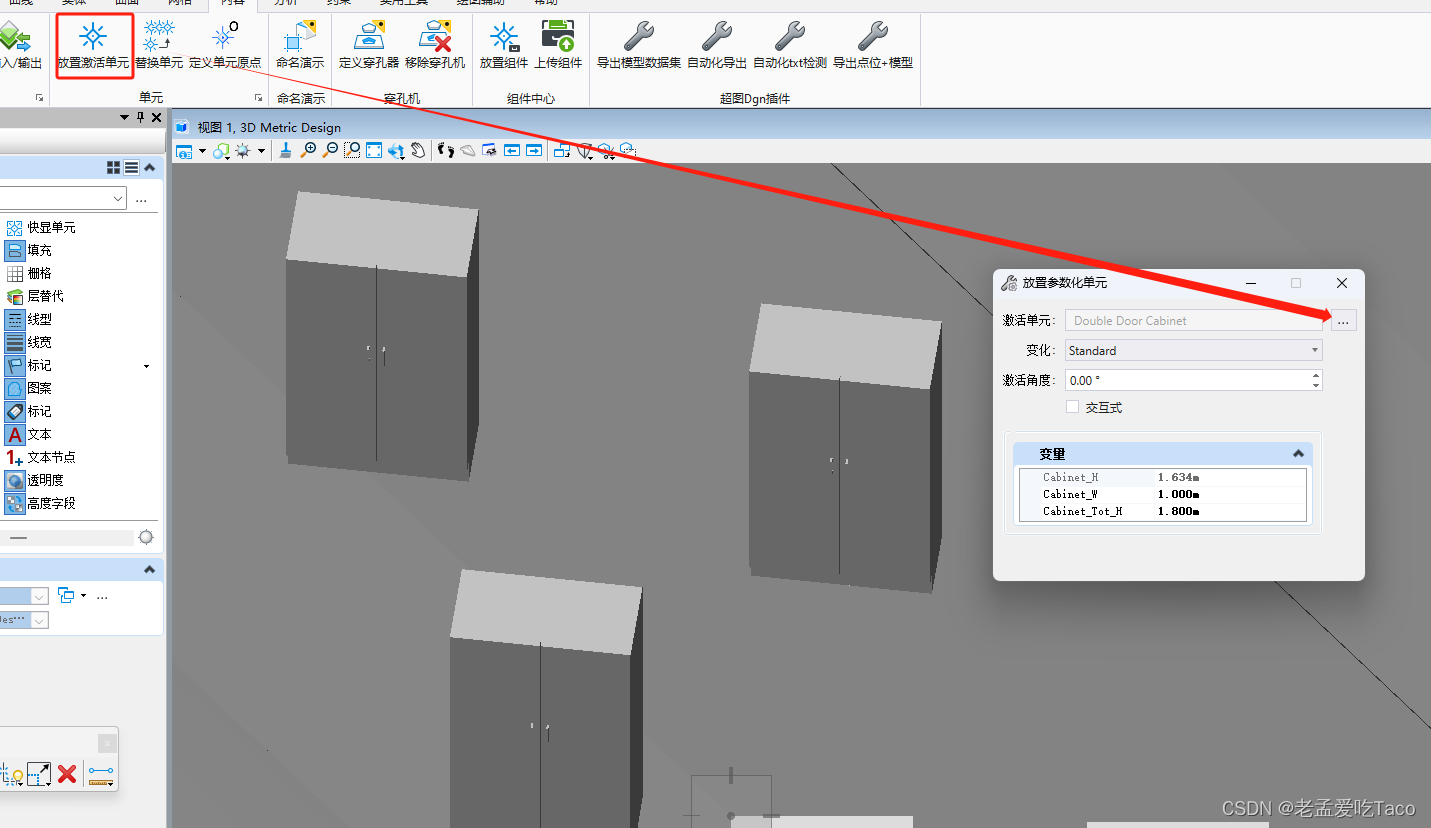
激活单元可以为创建的dgn文件导入即可使用。导入后我们双击激活就可以在场景中创建实例模型了。
三、实例化与缓存
介绍完了在建模软件中的实例化信息与idesktop中的关联,那么接下来我们来说说后续的步骤。虽然我们说明了降低存储。但是是从哪里看出来的呢?说白了后面性能问题还是没有解决。具体又怎么个使用呢?
3.1 文件大小
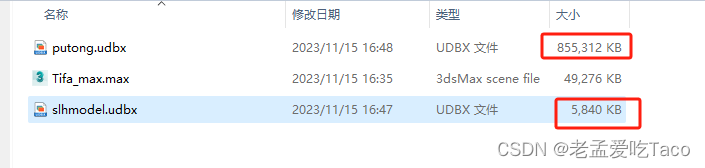
同样的一份模型通过复制、实例方式分别进行导出。可以通过导出的udbx大小看出有着明显的差别,未实例导出的大小为835M,实例导出的大小只有5.7M 。
3.2 加载速度&场景帧率
这里使用的模型比较极限,单个场景中仅显示的三角网数量达到了800w,这时已经看不出实例化和非实例化的区别了。帧率趋向于一致。但是从模型的加载速度上来看,未经过实例化的加载速度完成时间在10s左右。而经过实例化的模型加载速度3s左右。
3.3 切片缓存
数据集的大小对比完成后,我们来看下实例化数据对缓存的影响。
在说缓存之前我们先引入一个新的概念:数据集实例化、普通缓存实例化、点外挂缓存完全实例化。
3.3.1 数据集实例化
数据集实例化指的是模型对象之间存在了复用的关系(也就是我们在模型属性中看到的复用次数),是存储在udb及udbx中的实例化对象,可以减少udbx、udb等占用空间。只跟骨架、材质、纹理三者有关。
什么手段可以使数据集实例化?
1. 建模软件中存在复用关系,即可在导出后得到数据集实例化的对象。也就是上文中建模软件的一些操作,包含“族”、“共享单元”等实例对象。
2. 如果确定这骨架、材质、纹理相同,但是显示没有复用的化,可以使用iDesktop 中【三维数据】-【模型工具】-【实例化处理】功能,将其进行实例化。
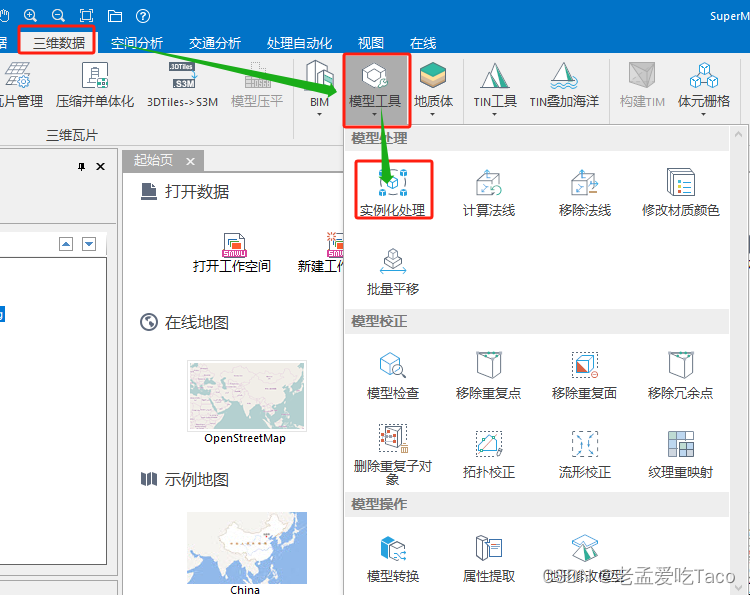
3.3.2 缓存实例化
在说明普通缓存实例化之前我们使用上面的数据继续做一个测试。普通缓存实例化使用的功能仅有一个,可以在下图中看到。在模型数据集生成三维缓存的时候我们勾选一个参数叫做【实例化】。
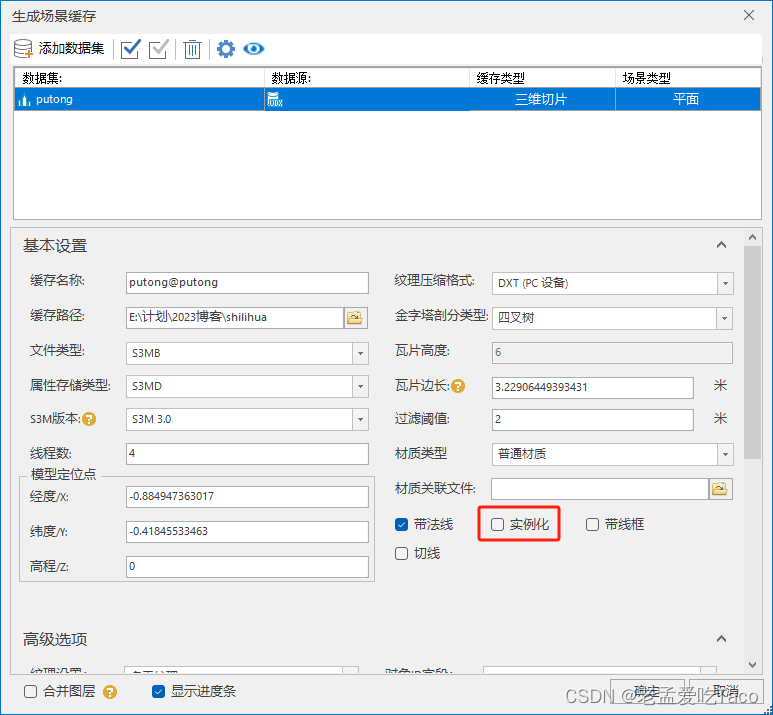
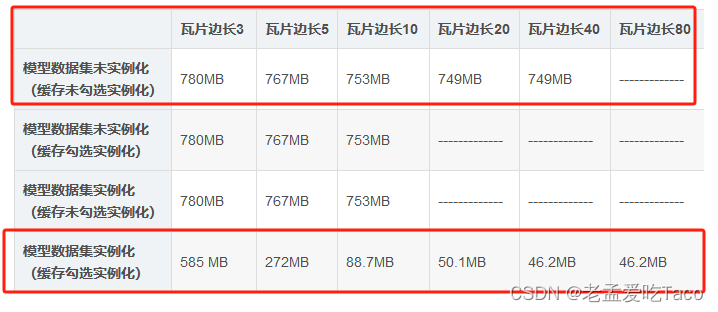
而什么情况勾选这个参数才起作用呢?没有实例化信息的模型数据集直接勾选也可以将模型实例化么?勾选后文件大小会减小么?我们做了一组测试,来看下面的表格。
| 瓦片边长3 | 瓦片边长5 | 瓦片边长10 | 瓦片边长20 | 瓦片边长40 | 瓦片边长80 | |
|---|---|---|---|---|---|---|
| 模型数据集未实例化 (缓存未勾选实例化) | 780MB | 767MB | 753MB | 749MB | 749MB | ------------- |
| 模型数据集未实例化 (缓存勾选实例化) | 780MB | 767MB | 753MB | ------------- | ------------- | ------------- |
| 模型数据集实例化 (缓存未勾选实例化) | 780MB | 767MB | 753MB | ------------- | ------------- | ------------- |
| 模型数据集实例化 (缓存勾选实例化) | 585 MB | 272MB | 88.7MB | 50.1MB | 46.2MB | 46.2MB |
1. 我们从前两行观察到当模型数据集中本身不包含实例化信息的时候。无论我缓存时是否勾选实例化缓存结果均为一致的。
2. 由第三行与第四行来对比会发现,如果模型数据集本身包含实例化信息,但不勾选该功能时,普通缓存结果并不保留实例化信息。
3. 由第一行与第四行对比可以发现,模型数据集本身实例化后,在缓存时勾选实例化功能,可以大大减小普通模型缓存结果文件的大小。
为了减小缓存文件的大小,数据集实例化、缓存实例化就缺一不可啦!
纵向的实例化结束了,表格还有横向的。那横向的瓦片边长又代表什么意思呢?作用又是什么呢?
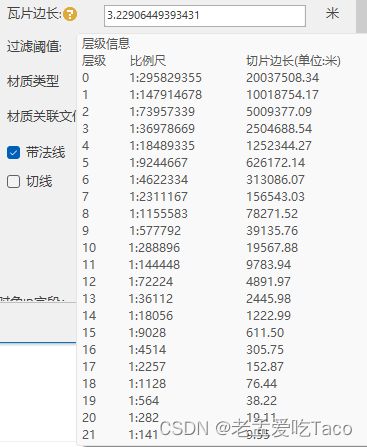
先用未实例化的数据集解释一下瓦片边长是什么意思。我们先以瓦片边长3(767MB)、10(753MB)、20(749MB)的数据来看,缓存后数据量的大小其实并没有明显区别。

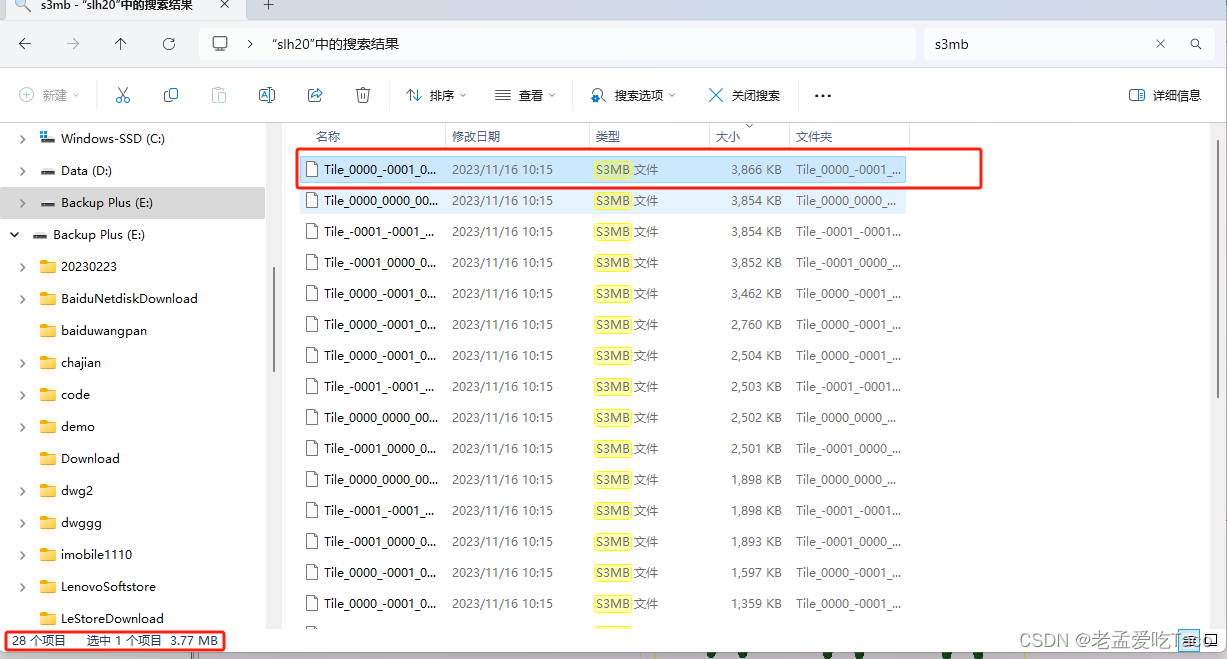
然而我放出另一张图,阁下该如何应对呢?我们分别找出每个文件夹中最大的s3mb缓存文件,就会发现不同。
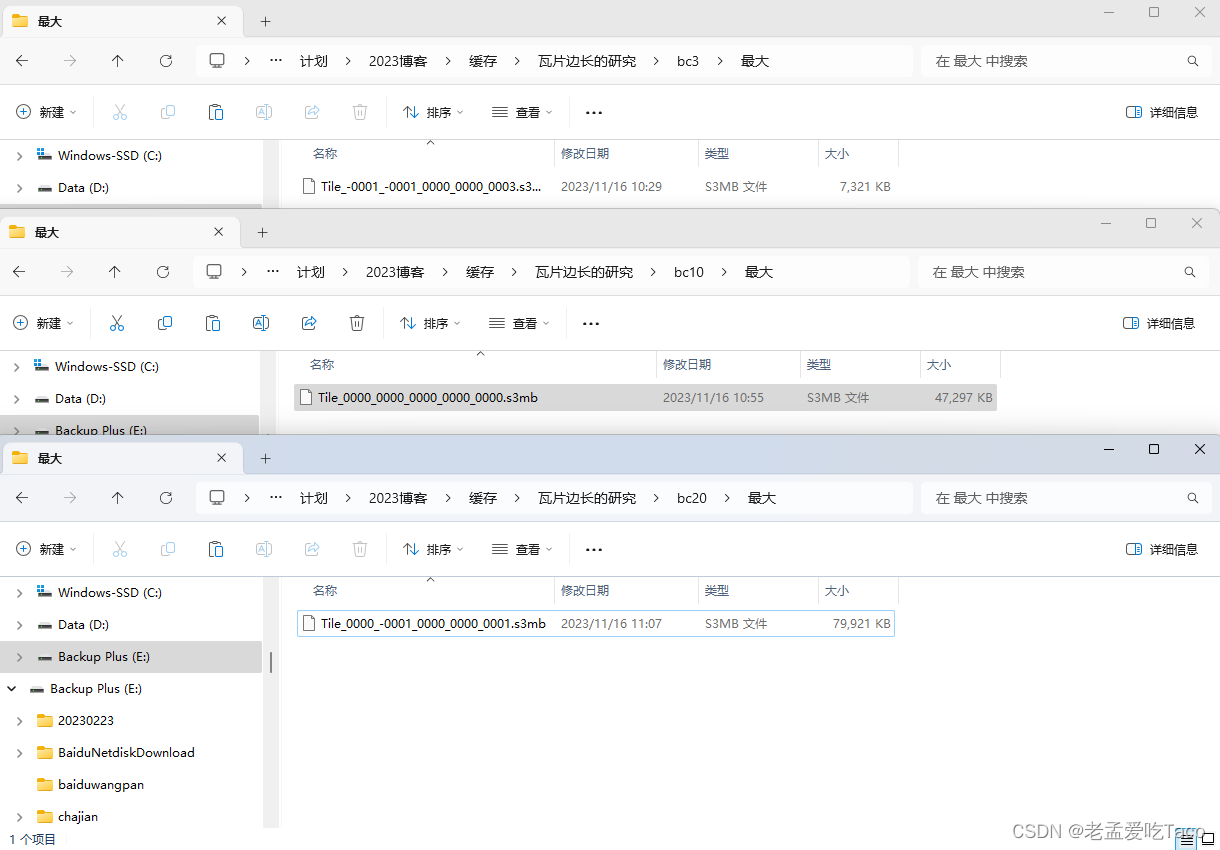
瓦片变成为3的数据最大的缓存为7.14MB,瓦片边长为10的数据最大的缓存为46MB,而瓦片边长为20的数据最大的缓存竟然已经高达了79MB!
可以在模型数据集的属性中查看到包围盒范围,现在我模型的包围盒子在20米左右。
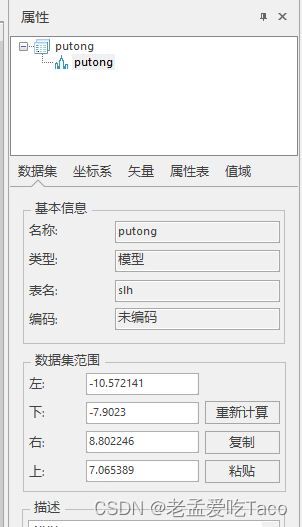
我们就假定他就是20m的包围盒,如下图。
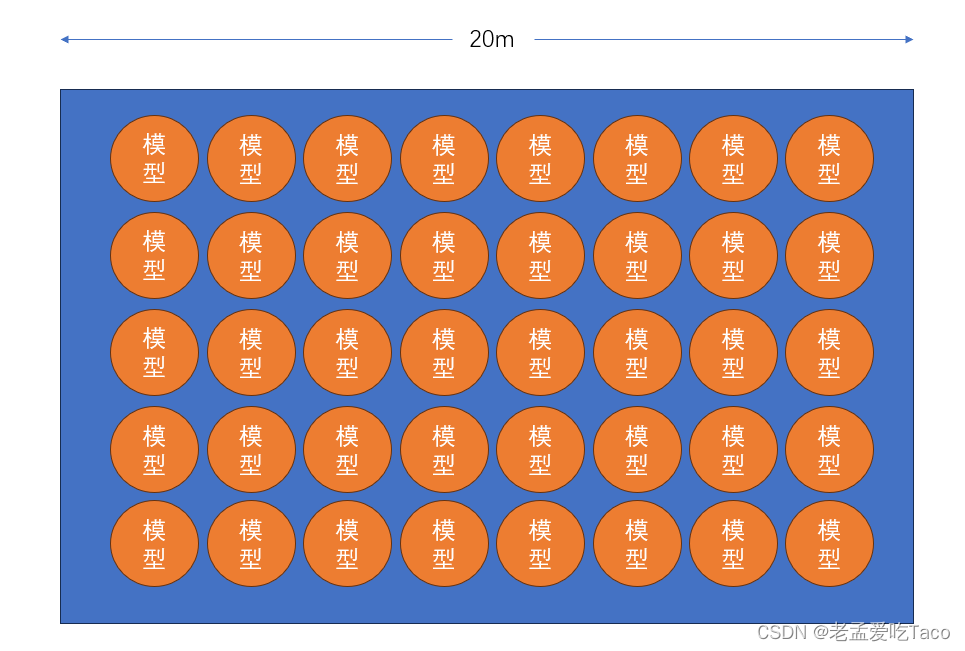
而我的瓦片边长的定义是处理后数据最大的边长,最大根节点所在的比例尺,最大的块的区域。
瓦片边长 3m
瓦片边长 10m

瓦片边长 20m
这也就是为什么瓦片边长越大,缓存结果的存储就越大了。当然不是说越小越好,瓦片边长决定了缓存根节点数量:边长越大,根节点越少;相反,边长越小,根节点数量过多时,加载模型将在一定程度上变慢。过少又会导致数据下载渲染过慢。还是需要取一个合适的值。关于这部分优化可以参考其他的模型优化方案来处理,这里就不细说了。
我们回到实例化上面。为什么要先说明瓦片边长呢,因为实例化与其还是有一定关系的。
我们来观察第一行和第四行的数据就可以发现,当我瓦片边长越大,普通实例化缓存数据的数据量会有明显的变少。反而当我瓦片边长越小,实例化的模型大小反而越不明显更趋近于未实例化的普通缓存。
实际上,这部分处理的实例化是不跨瓦片的,也就是在瓦片内实例化。而不是说我同一个模型在不同瓦片之间都是复用的。所以就解释了瓦片变成越小,越趋近于原始的未实例化缓存。而瓦片边长越大,则能更多的复用对象。
但由于复用的关系,此时则不会因为瓦片边长过大而导致的单个s3mb过大。(除非本身模型够大)。此时我们找到瓦片边长为20m的数据,降序排列其最大的s3mb文件仅有3Mb。
3.3.3 点外挂缓存实例化
然而除了普通实例化缓存以外,还有一种缓存是对数据做了完全实例化的。这个缓存就是点外挂生成缓存。相当于我所有的模型共用了一份模型缓存文件,其他地方只存储矩阵及点位信息。
然而这种类型的数据在处理为缓存之前也有一个特殊的要求,就是需要(点+模型)的格式。而并非在模型数据集中的复用关系。
在点中存储了矩阵信息、模型位置路径、以及其他的一些模型中所包含的属性信息。然而这种数据是如何处理出来的呢?在超图的三维插件中提供了该工具,用来导出点+模型工具。
工具可以在上面链接处下载。目前超图三维导出插件只提供max、bentley软件导出点集加外挂模型。
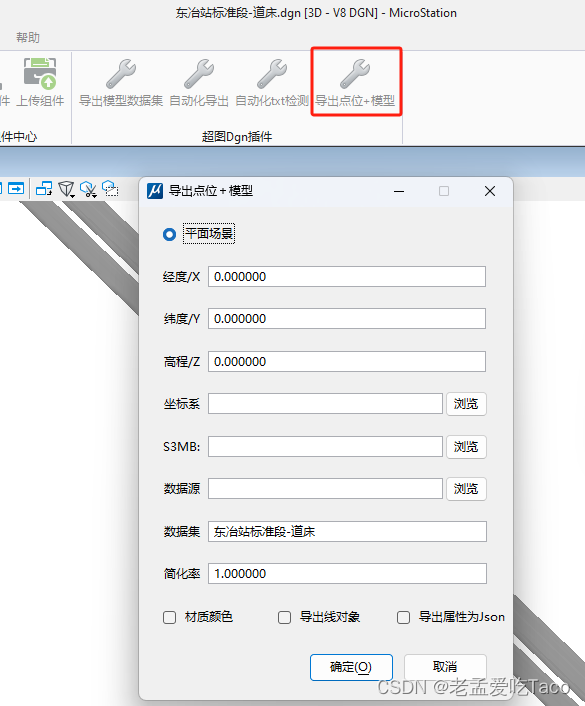
我们继续以Max数据为例进行导出。虽然这里模型有很多,但是导出后的数据仅有一个实例模型。而与其对应的点数据集包含了。路径位置及矩阵信息。

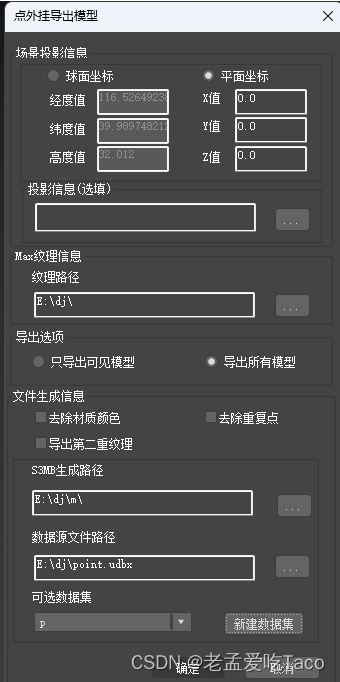
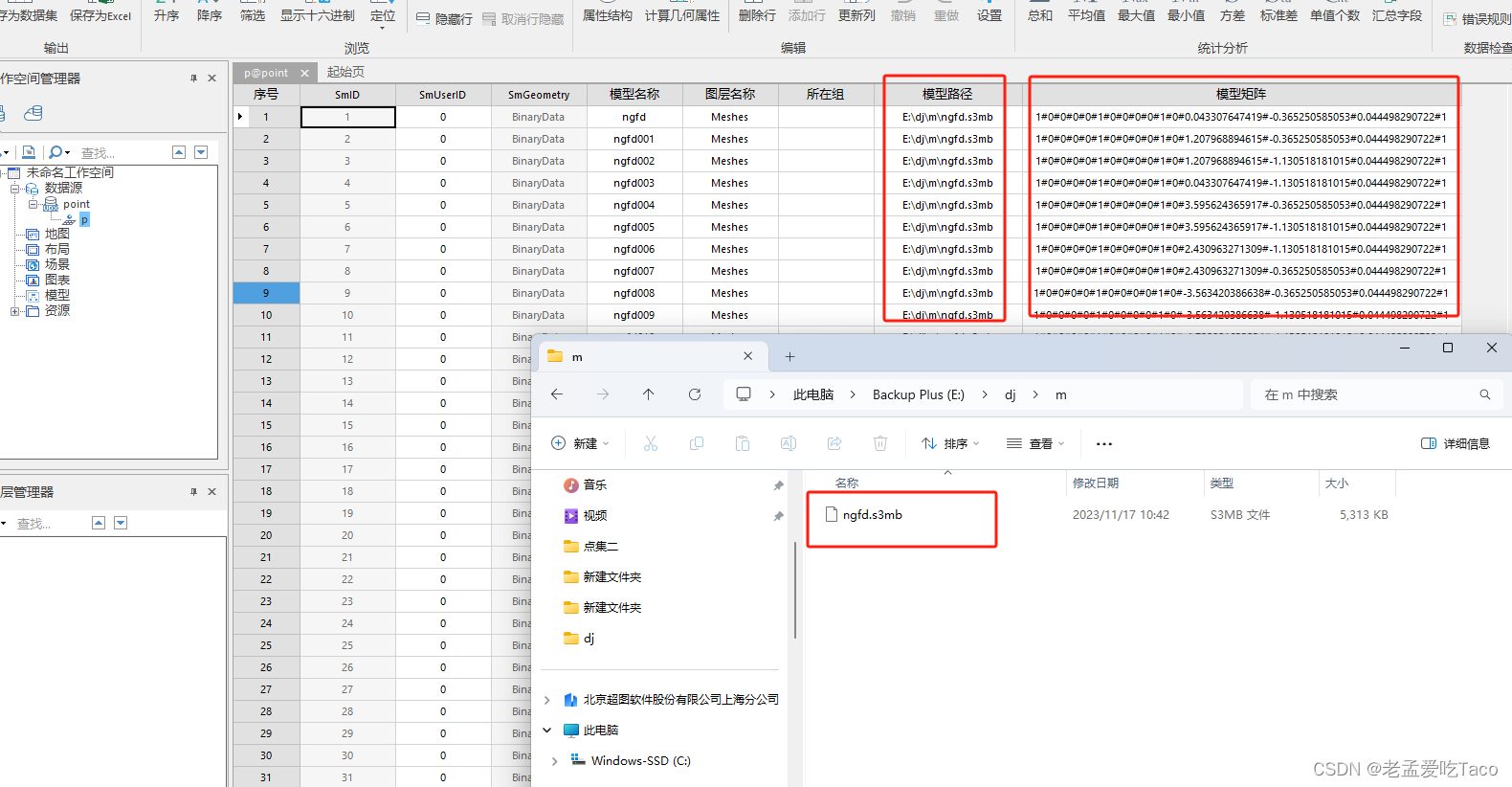
至于点外挂数据如何处理为缓存,可以参考另一篇文章,已经详细说明了。点击下方链接可以直接跳转SuperMap iDesktop 点数据集外挂生成缓存详解_idesktop 生成缓存到oss-CSDN博客
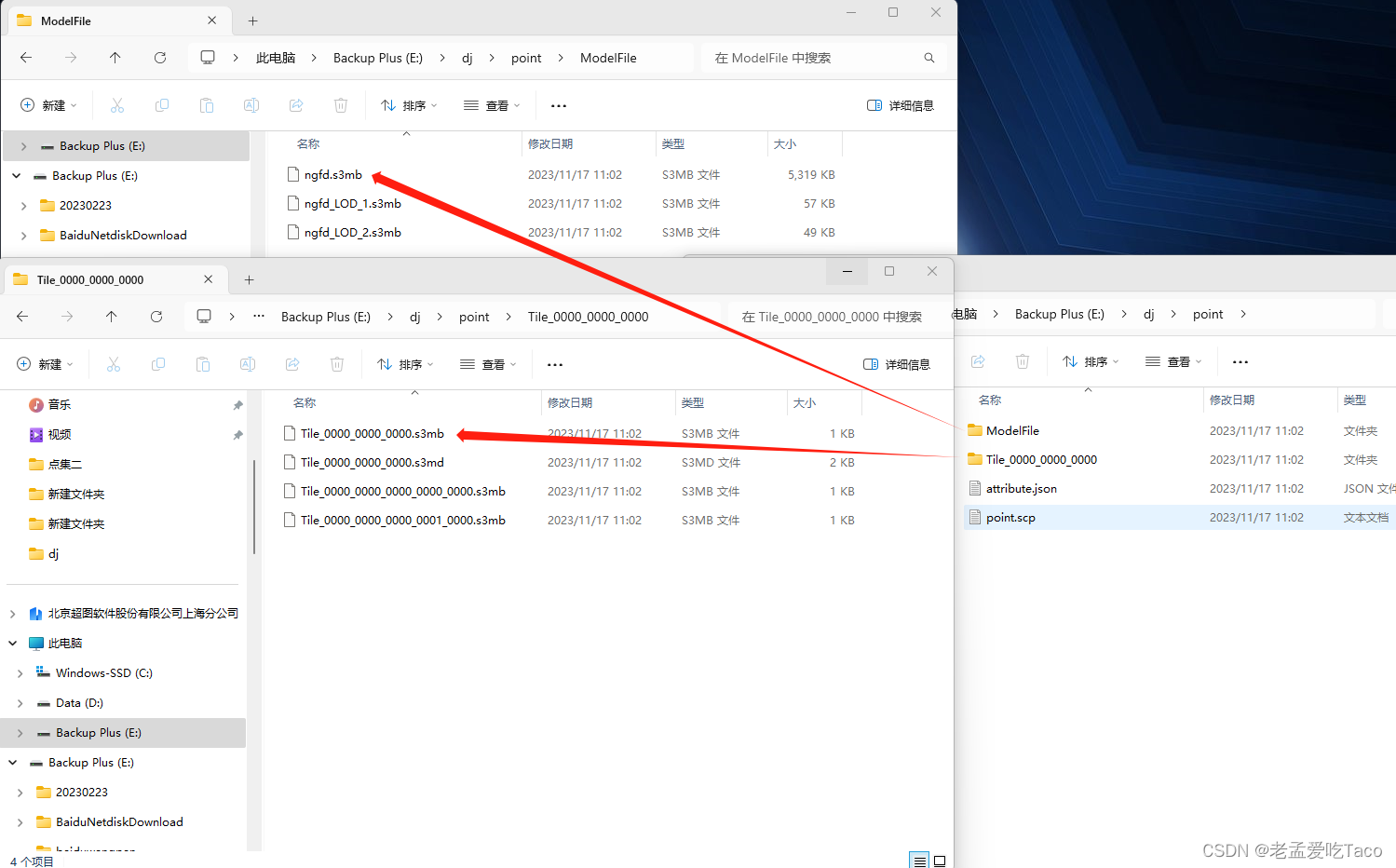
不过我们这里说明一下点外挂缓存后的格式,缓存后的格式包含ModelFile文件夹和Tile文件夹。在ModelFile中存储了我们使用的模型在这里已经不按照瓦片去区分了,就是点位去放置这个模型。此时整个缓存只有5.3Mb的大小。极大程度减小模型所占用的空间大小。同时由于复用关系,占用资源大大减小。场景的帧率有也了显著的提升。同样Bentley导出插件的效果一致。
3.3.4 缓存的使用
虽然说了普通缓存和点外挂缓存的区别,那在实际使用中我应该用哪个呢?什么情况下应该使用模型普通缓存,什么情况下应该使用点外挂缓存?
从使用上来说,这两个缓存没有明显的界限。但经验测试发现,如果构件种类较少30-40种范围内,同时复用情况又比较多的情况下。就比如我们一开始说的枕木、扣件一类。使用点外挂的方式会明显优于普通场景缓存(实例化)。
如果场景已经处理好了,扣件、枕木不便于拆分成单独图层的话,优先使用普通模型缓存(实例化)。当然大型构件也更适用于场景缓存。
当然具体情况还需要结合实际场景再进行调整。
四、实例化与导出点外挂代码
上面max插件和bentley插件都能导出了,那之前说的revit可咋办啊!模型都建好了啊!难道又要花钱重新建模了么?No! 不用的!(当然还有一些fbx,obj的模型同理!)
如果模型存在复用关系,又想要实现点外挂功能的话。目前直接通过iDesktop的话还没有办法,不过走iObject 组件的话当然还是可以实现的!
接下来我们介绍一下如果使用代码实现的应该如何处理当然如果不是开发的话,也可以在我的资源中也可以下载小程序直接使用的。
这里仅介绍关键代码。
第一步获取模型的实例化信息存储起来。而实例化信息就包含了我们所说的骨架、材质、纹理等信息。
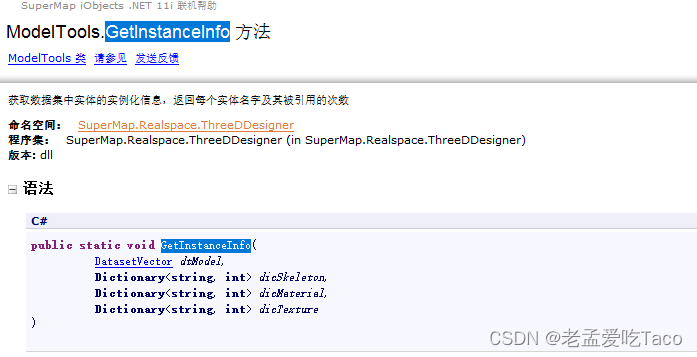
DirectoryInfo directoryInfo = Directory.CreateDirectory(Path.GetDirectoryName(textBox1.Text) + "\\" + datasetName);
Dictionary<string, string> dictionary = new Dictionary<string, string>();
Dictionary<string, int> dictionary2 = new Dictionary<string, int>();
Dictionary<string, int> dictionary3 = new Dictionary<string, int>();
Dictionary<string, int> dictionary4 = new Dictionary<string, int>();
DatasetVector dv = ds.Datasets[datasetName] as DatasetVector;
ModelTools.GetInstanceInfo(dv, dictionary2, dictionary3, dictionary4);接下来我们创建三维点的矢量数据集用于存储我们的点位,并在其中添加关联模型字段、关联矩阵字段。用来存储我们点外挂缓存的关联到的模型数据与矩阵信息。
//创建三维点数据集用于存储点外挂信息
DatasetVectorInfo dvinfo = new DatasetVectorInfo();
dvinfo.Type = DatasetType.Point3D;
dvinfo.Name = datasetName + "p3d";
if (ds.Datasets.Contains(dvinfo.Name))
{
dvinfo.Name = dvinfo.Name + "_1";
}
DatasetVector pointp3d = ds.Datasets.Create(dvinfo);
pointp3d.PrjCoordSys = dv.PrjCoordSys;
FieldInfos fieldInfos = dv.FieldInfos;
foreach (FieldInfo item in fieldInfos)
{
FieldInfo val4 = item;
if (!val4.IsSystemField && !(val4.Name == "SmUserID"))
{
pointp3d.FieldInfos.Add(val4);
}
}
//创建关联模型\关联矩阵字段
FieldInfo fieldinfo1 = new FieldInfo();
fieldinfo1.Type = FieldType.Text;
fieldinfo1.Name = "关联模型";
fieldinfo1.MaxLength = 1024;
pointp3d.FieldInfos.Add(fieldinfo1);
fieldinfo1.MaxLength = 255;
fieldinfo1.Type = FieldType.Text;
fieldinfo1.Name = "关联矩阵";
pointp3d.FieldInfos.Add (fieldinfo1);
fieldinfo1.Dispose();接下来遍历我们定位到第一条记录集,去遍历我记录集中的每一个模型数据,使用GetGeometry获取到模型。读取GeoModel3D的中心点用于新建 Point3D对象,添加至我们的三维点数据集。
随后我们获取到GeoModel3D的Model,用来提取骨架信息。当然每一层的都要拿出来去创建为一个新的。关于骨架LOD的详细使用可以参考博客(SuperMap iObjects.Net模型纹理更新功能及注意事项-CSDN博客)这里就不详细介绍了。
模型数据的矩阵信息是通过Skeleton skeleton = oldmodel.GetSkeleton(oldmodelsktid, ref array); 可以直接获取到的。但是我们需要提前创建一个4*4的数组用来存储矩阵信息,当然 double[] array = new double[16];创建就可以的了。
紧接着通过字典的方法去判断是否相同,如果不相同则导出一个s3m本地模型文件。这样子我们就实现了导出点+模型,随后继续使用idesktop工具直接处理为点外挂缓存即可。
//设置字段批量更新参数
Recordset recordset = pointp3d.GetRecordset(false,CursorType.Dynamic);
recordset.Batch.MaxRecordCount = 100;
recordset.Batch.Begin();
//获取模型记录集并移动至第一条
Recordset modelrecordset = dv.GetRecordset(false, CursorType.Static);
modelrecordset.MoveFirst();
//遍历模型记录集导出
for (int i = 1; i <= modelrecordset.RecordCount; i++)
{
//获取模型
GeoModel3D geomodel3d = modelrecordset.GetGeometry() as GeoModel3D;
//获取模型中心点
Point3D position = geomodel3d.Position;
GeoPoint3D geopoint3d = new GeoPoint3D(position);
//添加
//三维点
recordset.AddNew(geopoint3d);
//添加字段
foreach (FieldInfo item2 in fieldInfos)
{
FieldInfo val8 = item2;
if (!val8.IsSystemField)
{
recordset.SetFieldValue(val8.Name, modelrecordset.GetFieldValue(val8.Name));
}
}
Model oldmodel = geomodel3d.Model;
Model newmodel = new Model();
//获取旧模型矩阵,lod,骨架
//获取骨架
int skeletonCount = oldmodel.GetSkeletonCount(-1);
double[] array = new double[16];
string text = "";
//获取旧模型lod
int lODCount = oldmodel.LODCount;
for (int j = 0; j < skeletonCount; j++)
{
SkeletonID oldmodelsktid = new SkeletonID(-1, j);
//获取指定编号和外部矩阵的骨架
Skeleton skeleton = oldmodel.GetSkeleton(oldmodelsktid, ref array);
text += skeleton.Name;
newmodel.Add(skeleton);
//释放骨架
skeleton.Dispose();
List<Model> list = new List<Model>();
//获取模型每层LOD
for (int k = 0; k < lODCount; k++)
{
Model modellod = new Model();
SkeletonID sktid2 = new SkeletonID(k, j);
Skeleton skeleton2 = oldmodel.GetSkeleton(sktid2, ref array);
modellod.Add(skeleton2);
list.Add(modellod);
skeleton2.Dispose();
modellod.Dispose();
}
//更新模型lod
newmodel.SetLODs(list);
foreach (Model item3 in list)
{
item3.Dispose();
}
list.Clear();
}
string str = "";
for (int l = 0; l < array.Length - 1; l++)
{
str = str + array[l].ToString() + "#";
}
str += "1";
recordset.SetFieldValue("关联矩阵", (object)str);
if (!dictionary.Keys.Contains(text))
{
string text2 = Guid.NewGuid().ToString();
//模型文件设置类。该类提供了获取或设置模型文件路径、是否忽略LOD(仅对osgb起作用)、获取模型文件类型。
ModelFileSetting modelFileSetting = new ModelFileSetting();
modelFileSetting.IgnoreLOD = false; ;
string text3 = filetype;
string a = text3;
if (!(a == "S3MB"))
{
if (a == "OBJ")
{
modelFileSetting.FilePath = directoryInfo.FullName + "\\" + text2 + ".obj";
}
}
else
{
modelFileSetting.FilePath = directoryInfo.FullName + "\\" + text2 + ".s3mb";
}
ModelConvertor.ToFile(newmodel, modelFileSetting);
modelFileSetting.Dispose();
dictionary[text] = text2;
}
string text4 = filetype;
string a2 = text4;
if (!(a2 == "S3MB"))
{
if (a2 == "OBJ")
{
recordset.SetFieldValue("关联模型", (object)(directoryInfo.FullName + "\\" + dictionary[text] + ".obj"));
}
}
else
{
recordset.SetFieldValue("关联模型", (object)(directoryInfo.FullName + "\\" + dictionary[text] + ".s3mb"));
}
newmodel.Dispose();
modelrecordset.MoveNext();
}
recordset.Batch.Update();















 2687
2687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









