







作者:doremi
流数据服务(Streming Service)基于Spark Streaming分布式实时计算框架,因此在配置服务前,需要开启Spark集群。您可以使用iServer内置的Spark来搭建集群,也可以自行在其他的机器上搭建Spark集群服务,参考https://blog.csdn.net/supermapsupport/article/details/91973584,将Spark集群服务注册到iServer中,并且开启分布式分析服务即可开启分布式分析环境,参考https://blog.csdn.net/supermapsupport/article/details/90903095
流模型
在使用流数据服务时,我们必须先了解流模型的结构。
流数据处理流程包含:

依据上述处理流程,流数据的处理模型包含四个部分:Receiver(接收器)、Filter(过滤器)、Mapper(转换器)和Sender(发送器)。每个部分作为一个节点,可以进行连接和合并,构建成实时数据处理流 Stream。除了处理流 Stream 以外,还有一些辅助参数作为整个服务的运行条件,一并存储在启动参数类型 Startup 中。

发布流数据服务需要将配置好的流处理模型文件发布出来,为了方便大家配置流处理模型,我们提供了WEB端的可视化流处理模型编辑器
流处理模型编辑器
使用管理员用户登录iServer服务管理页面,进入服务页面,在默认打开的“概述”页面单机“配置流数据服务”,打开流处理模型编辑器

如图所示,左边为流处理模型的组件列表,包含四部分:接收器、发送器、转换器和过滤器,每个部分作为一个节点,可在右侧的节点编辑器中,进行连接和合并,同时编辑各节点的属性信息,从而构建流处理模型。在编辑器中可直接发布构建好的流处理模型为流数据服务,在页面上部可指定流数据服务的服务名,“发布”按钮用于发布流数据服务。
接收器作为流数据处理的入口,接收各种来源的数据,需要设置接收信息的元数据,消息的读取格式
转换器用于建立字段映射以及对字段进行管理,主要包括字段映射、添加字段、删除字段、字段运算以及地理围栏
过滤器用于过滤当前数据,进行数据的清洗与整理
具体详细的参数配置信息介绍可以参考帮助文档(http://support.supermap.com.cn/DataWarehouse/WebDocHelp/iServer/index.htm)“使用iServer”-“使用流数据服务”-“配置流数据服务”-“流处理模型配置参数说明”
构建流处理模型
添加节点,将左侧的组件拖拽至右侧编辑区域,添加后如下图

编辑属性,单机节点进行属性编辑,填入实际情况的数据属性或者计算表达式,编辑完成选择保存

连接节点,拖拽方框的右侧绿色部分,将拖拽出的箭头指向下一个节点。发送器作为最终节点用于输出处理结果,因此无下一节点
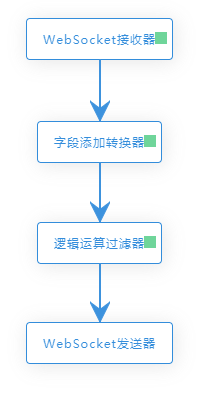
删除节点和连接,鼠标悬浮于几点上,单机右上角的x即可删除此节点,单机节点连接箭头可删除该连接
流处理模型编辑器的大致介绍就到这了,后续我们会对各个类型的接收器进行详细的配置介绍和实际运用















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









