







目录
1 主要内容
该程序为python代码实现数据聚类分析,聚类分析在电力系统上应用非常广泛,如全年的风、光和负荷数据量比较大,为了提高分析效率,可以将全年数据聚类得到几类不同场景,通过概率权值的方式实现“代表性”分析,还可以用于用户用电行为特点等方面,该程序作为全家桶,包含基于密度的聚类DBSCAN算法、基于划分的聚类AP算法、基于密度的空间聚类自适应算法、
基于密度的聚类OPTICS算法、基于划分的聚类KMeans算法、基于划分和密度的聚类CFSFDP算法、基于DBSCAN改造的时空聚类算法等15类聚类算法,基本做到句句注释,方便学习研究。
-
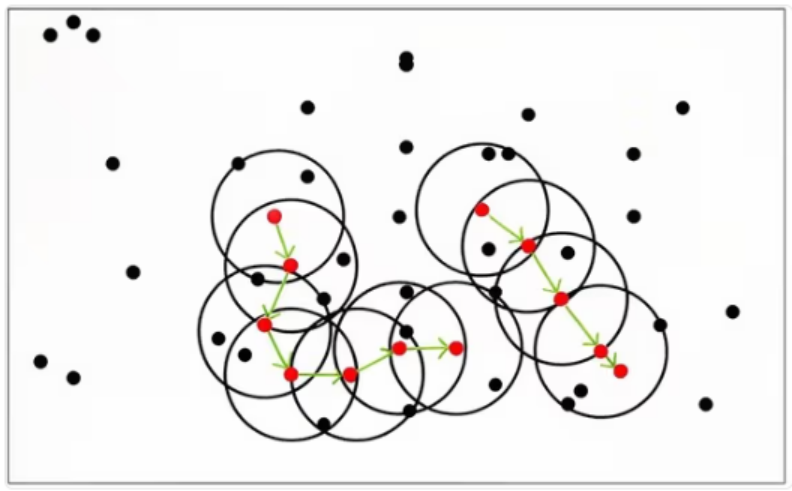
DBSCAN聚类算法
DBSCAN 聚类定义为:由密度可达关系导出的最大密度相连样本集合构成一个聚类簇,簇中可有一个或多个核心对象。若仅一个核心对象,其他非核心对象在其 ϵ- 邻域内;若多个核心对象,任一核心对象的 ϵ- 邻域必有其他核心对象,这些核心对象 ϵ- 邻域内所有样本组成 DBSCAN 聚类簇。
寻找聚类簇样本集合的方法:任选无类别的核心对象作种子,找出其密度可达的样本集合,构成一个聚类簇。之后不断选取未分类的核心对象,重复上述过程找新聚类簇,直至所有核心对象都有类别。
Kmeans聚类算法
K-means 算法是一种聚类算法。聚类是依据相似性原则,把相似度高的数据对象归为同一类簇,相异度高的分到不同类簇。它与分类的关键区别在于:聚类是无监督过程,待处理数据无先验知识;分类是有监督过程,有带先验知识的训练数据集。
在 K-means 算法里,K表示类簇个数 ,means指类簇内数据对象的均值(不过,若存在异常点,如极大或极小值,求均值会受干扰)。该算法也叫 k-均值算法 ,属于基于划分的聚类算法,以距离衡量数据对象间相似性,距离越小,相似性越高,越可能同属一类簇。通常,K-means 算法用欧氏距离计算数据对象间的距离。
算法流程如下:

-
数据说明
程序应用的数据为二维或者三维度数据,通过单独的数据文件保存,方便直接替换为所要分析的数据。
2 部分程序
# 计算距离矩阵def compute_squared_EDM(X): return squareform(pdist(X,metric='euclidean'))# DBSCAN算法核心过程def DBSCAN(data,eps,minPts): # 获得距离矩阵 disMat = compute_squared_EDM(data) # 获得数据的行和列(一共有n条数据) n, m = data.shape # 将矩阵的中小于minPts的数赋予1,大于minPts的数赋予零,然后1代表对每一行求和,然后求核心点坐标的索引 core_points_index = np.where(np.sum(np.where(disMat <= eps, 1, 0), axis=1) >= minPts)[0] # 初始化类别,-1代表未分类。 labels = np.full((n,), -1) clusterId = 0 # 遍历所有的核心点 for pointId in core_points_index: # 如果核心点未被分类,将其作为的种子点,开始寻找相应簇集 if (labels[pointId] == -1): # 首先将点pointId标记为当前类别(即标识为已操作) labels[pointId] = clusterId # 然后寻找种子点的eps邻域且没有被分类的点,将其放入种子集合 neighbour=np.where((disMat[:, pointId] <= eps) & (labels==-1))[0] seeds = set(neighbour) # 通过种子点,开始生长,寻找密度可达的数据点,一直到种子集合为空,一个簇集寻找完毕 while len(seeds) > 0: # 弹出一个新种子点 newPoint = seeds.pop() # 将newPoint标记为当前类 labels[newPoint] = clusterId # 寻找newPoint种子点eps邻域(包含自己) queryResults = np.where(disMat[:,newPoint]<=eps)[0] # 如果newPoint属于核心点,那么newPoint是可以扩展的,即密度是可以通过newPoint继续密度可达的 if len(queryResults) >= minPts: # 将邻域内且没有被分类的点压入种子集合 for resultPoint in queryResults: if labels[resultPoint] == -1: seeds.add(resultPoint) # 簇集生长完毕,寻找到一个类别 clusterId = clusterId + 1 return labels
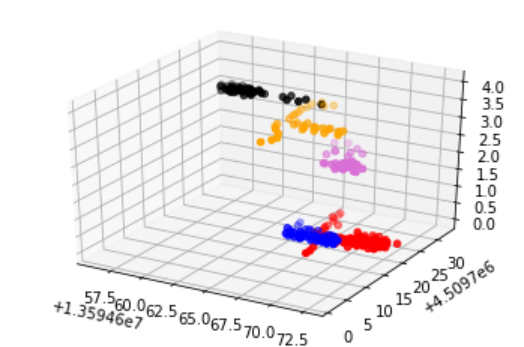
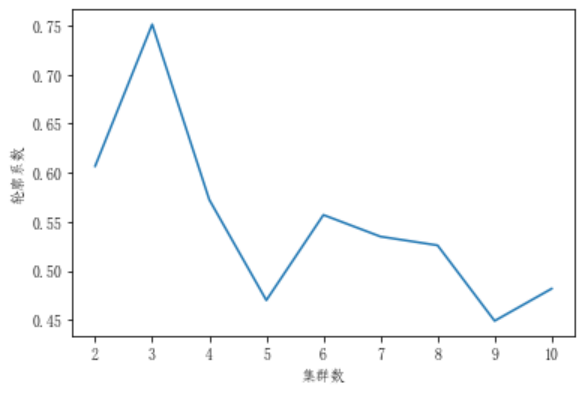
3 程序结果
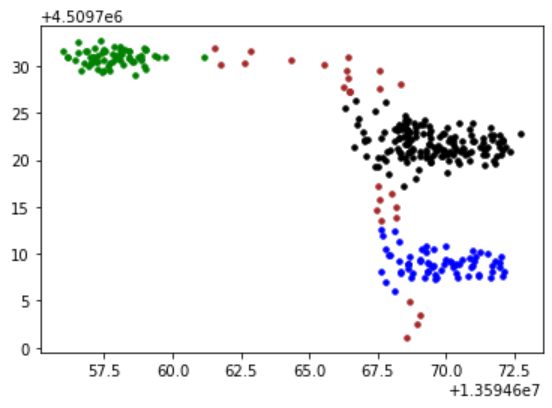
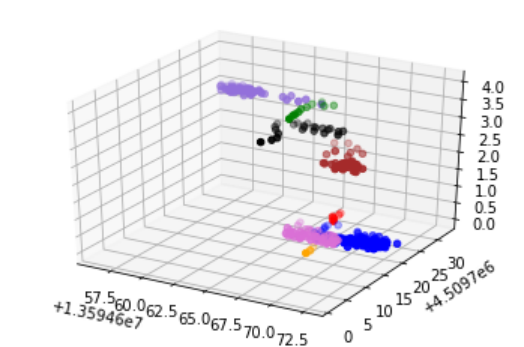
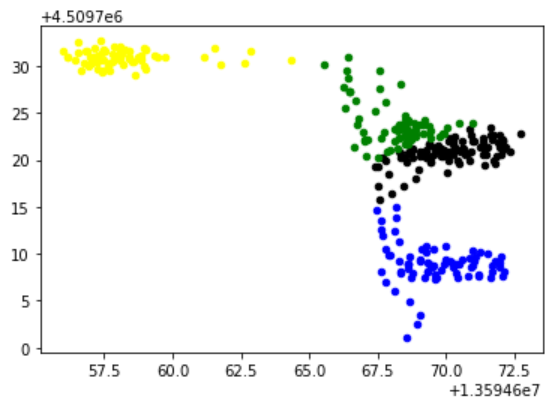
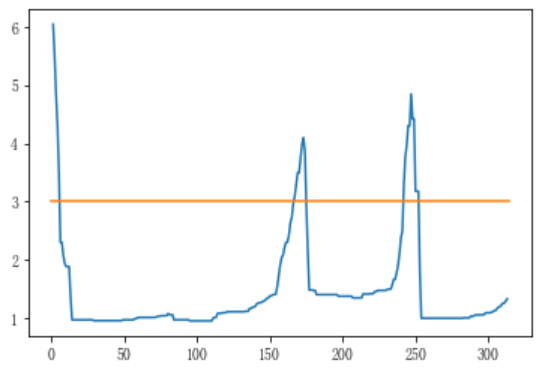
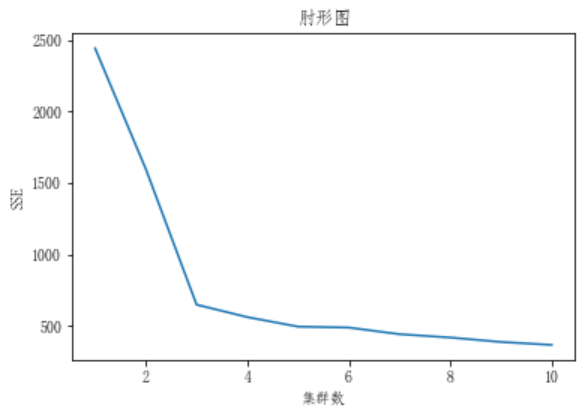
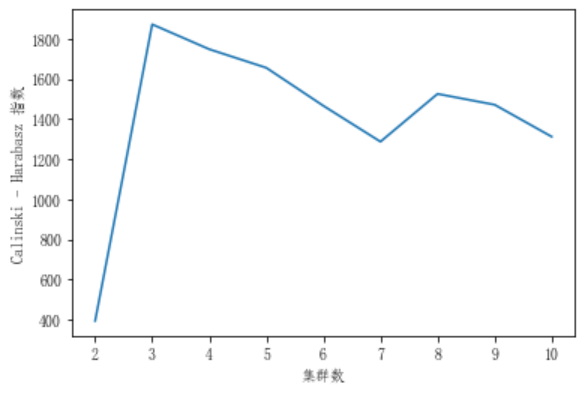
4 下载链接



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









