







特征工程
项目数据格式

CTR预估的流程
数据—>预处理—>特征提取—>模型训练—>后处理
模型和特征的关系
一句话概括这个问题,特征决定了上界,而模型决定了接近上界的程度。
数据预处理
首先要进行的是label匹配,由于我们拿到的数据为展示日志和点击日志,我们需要做的是将拿到的数据进行join操作,数据join完成之后我们,得到我们想要的训练数据。数据的预处理主要就是信息的组合,将其他文件的相关信息,组合到一个文件中,形成我们的训练数据。join的代码如下
#! /bin/bash
sort -t $'\t' -k "$2,$2" $1 >t1
sort -t $'\t' -k "$4,$4" $3 >t2
join -t $'\t' -1 $2 -2 $4 t1 t2 -a 1 | awk -v n=$2 '{
s=$2;
for(i=3;i<n+1;i++){
s=s"\t"$i
}
s=s"\t"$1
for(i=n+1;i<=NF;i++){
s=s"\t"$i
}
print s
}'
rm -f t1 t2如果数据较多,我们一般对数据进行负采样。负采样就是采集label为0的日志,保留正样本,如果样本数量不均衡,处理方法有,保留所有正样本,同时向下负采样,或者保留所有正样本且复制多次,同时向下负采样,使得比例大约为1:10左右。
数据特征
这里的特征一般都三类,用户特征,广告特征和上下文特征
| 标题 | 特征 |
|---|---|
| 用户特征 | userid、gender、age |
| 广告特征 | adid、titleid、advertedierid、keywordid、decription |
| 上下文特征 | depth、position |
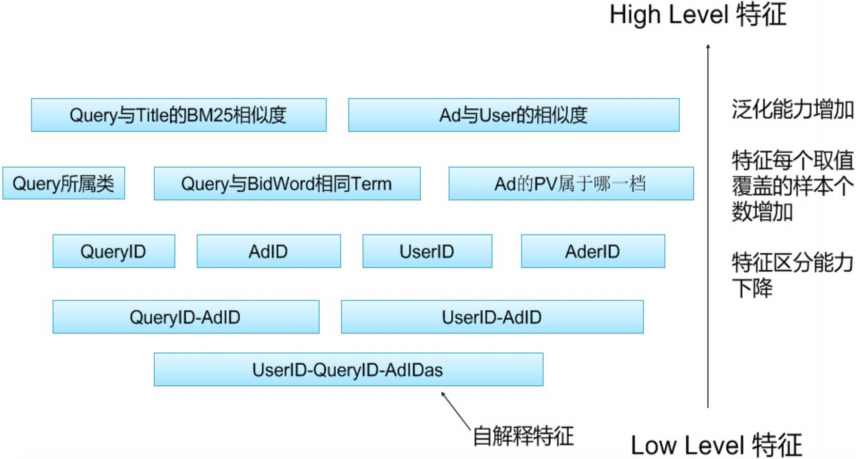
以上的这些特征按照,不同的能力,还可以有不同的划分方法,High Level特征和Low Level特征。
High Level特征:指的是泛化能力比较强的特征
Low Level特征:指的是子解释性比较强的特征
具体的关系如下图所示:
这里的特征还可以按照刻画能力和覆盖度进行划分
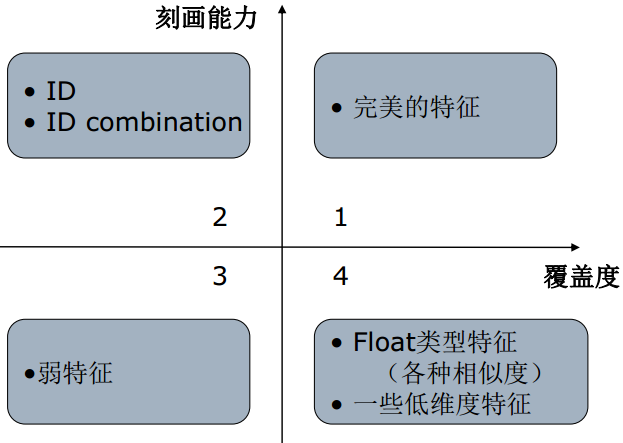
当然,我们最想要的就是在第一象限的完美特征,但是这种特征一般比较少,二三象限的特征比较多,而第四象限的特征的影响就比较微弱了。
数据特征处理方法
One Hot Encoding
One-Hot编码,又称为一位有效编码,主要是采用位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,举例说明,我们有如下属性:
性别:[“male”,”female”]
广告id:[11,22,33,44,55,66]
位置:[1,2,3,4,5,6]
对以一个样本[“feamle”,44,4],可以采用序列化的方式[1,3,3],但是这样不能直接在算法中使用。
One Hot Encoding的编码思想是,”female”对应[0,1],广告id44对应的是[0,0,0,1,0,0],位置4对应的是[0,0,0,1,0,0],则完整的特征数字化的结果为:
[0,1,0,0,0,1,0,0,0,0,0,1,0,0]
具体的代码实现,有两种方法,一种是通过加入前缀,形成唯一的编号,一种是通过Hash函数的方法,虽然Hash函数的方法,在数据量比较大的时候会有一些冲突,但是这对最后的影响结果不是很大。
加入前缀的特征处理
def processIdFeature(prefix,id):
global feature_map
global feature_index
str = prefix + "_" + id
if str in feature_map:
return feature_map[str]
else:
feature_index = feature_index + 1
feature_map[str] = feature_index
return feature_indexHash函数的方法
def hashFeature(prefix,id):
str = prefix + "_" + id
return hash(str) % HASH_SIZE离散化
为什么要使用离散化的方法?
假设特征在[0,1]之间,预测是有非线性关系
y=(x−0.5)2
,线性模型:
y=wx
进行拟合,效果会怎么样呢?效果应该不会太好,如果我们将
x
划分为若干段,比如:
等值离散
等值划分是将特征按照值域进行均分,每一段内的取值等同处理。
等量离散
等量划分是根据样本总数进行均分,每段等量个样本划分为1段。
特征组合
特征组合的目的,主要有两种
| 特征组合 | 目的 |
|---|---|
| AUC之间进行组合 | 提高表达关系的能力 |
| AUC内部进行组合 | 提高自解释的能力 |
参考文献:
1、http://blog.csdn.net/google19890102/article/details/44039761















 5294
5294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









