







前言
去年以来,以Cursor为代表的AI编程工具横空出世,彻底点燃了全球开发者对AI辅助编程的热情。海外各种新颖的AI开发工具层出不穷,几乎每周都有新的概念或产品涌现。反观国内,除了几家互联网大厂有所布局,专注于AI编程工具的初创公司似乎相对较少。这固然有国内大模型编程能力仍在追赶的原因,但或许也有一部分原因是,很多人觉得构建一个AI编程工具,特别是具备复杂交互和能力的“智能体(Agent)”,门槛很高,非常复杂。
事实真的如此吗?今天,我们就尝试用不到400行Python代码,带你从零实现一个简单的AI编程智能体。通过这个例子,我们将揭示AI编程智能体的核心原理,希望能打消一些顾虑,为大家构建自己的AI编程产品提供一些启发和参考!
1. AI编程智能体的基本框架
一个AI智能体并非无所不能的神祇,它的核心是大模型 (LLM),但大模型本身是没有感知外部环境和执行外部动作能力的。要让大模型变得“智能”起来,能够完成实际任务(比如读取文件、修改代码),就需要赋予它工具 (Tools),并构建一个**“感知-决策-行动”的循环**来协调这一切。
用一个简单的框架来描述:
- 感知 (Perception): 智能体接收用户的指令或环境信息(例如用户说“帮我读一下某个文件”)。
- 决策 (Reasoning): 大模型根据指令和它掌握的工具信息进行思考和规划,决定下一步做什么。它可能会决定需要调用某个工具来获取更多信息,或者直接给出答案,或者决定调用某个工具来执行一个动作。
- 行动 (Action): 如果大模型决定调用工具,它会输出一个特定的格式来表明它想调用哪个工具以及传入什么参数。
- 执行 (Execution): 开发者编写的“调度层”代码会捕获大模型的工具调用指令,并真正执行对应的工具函数。
- 观察 (Observation): 工具执行完成后,会产生一个结果(例如文件内容、执行成功/失败信息)。
- 反馈 (Feedback): 工具的执行结果被反馈给大模型,作为新的输入信息。
- 再决策/输出 (Re-Reasoning/Output): 大模型接收到工具结果后,会再次决策:是根据结果继续调用其他工具,还是已经获得足够信息,可以直接生成最终回复给用户。
这个循环不断往复,直到任务完成。我们的不到400行代码,就是要实现这个循环中的关键环节:工具的定义、大模型调用工具的解析、工具的执行以及结果的反馈。
下面通过一个流程图来更直观地展示这个基本框架:
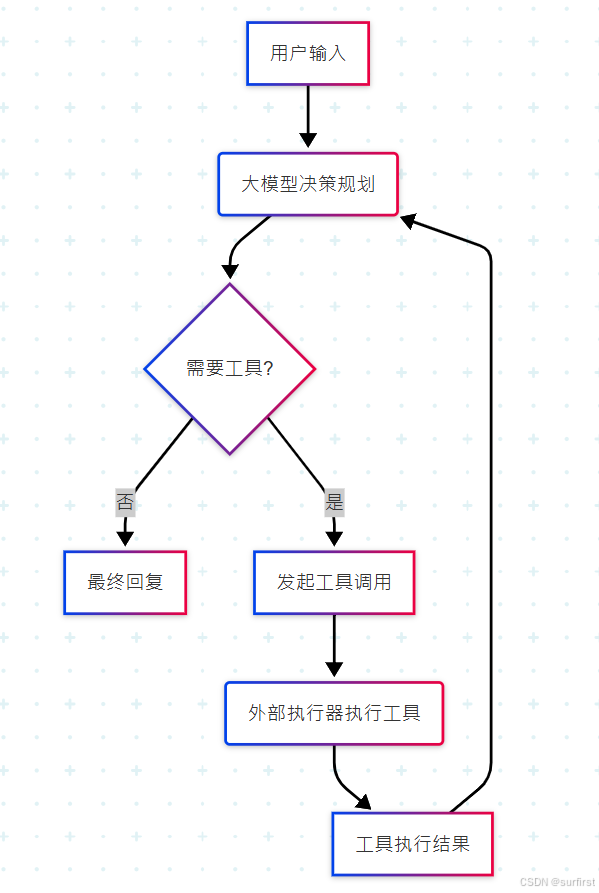
2. 智能体如何调用工具?核心机制解析
这是AI Agent的核心魔法之一:大模型如何知道要调用工具,以及如何告诉外部系统它想调用哪个工具和参数?
在深入代码之前,我们可以通过一个简单的例子来建立直观的理解。假设我们告诉大模型,它有一个叫做 get_weather(<地点名称>) 的工具,调用它可以获取指定地点的天气信息。
对话示例:
- 你: 你是一个天气专家。当我问你某个地方的天气时,你只需要回复我
get_weather(<地点名称>)。然后我会告诉你那里的实际天气。明白了吗? - 大模型: 明白了。当你问我某个地方的天气时,我会回复
get_weather(<地点名称>),然后你会提供具体的天气信息。 - 你: 好的,那慕尼黑天气怎么样?
- 大模型:
get_weather(慕尼黑) - 你: 慕尼黑现在天气:炎热潮湿,28摄氏度。
- 大模型: 好的,我已经知道慕尼黑的天气是炎热潮湿,28摄氏度了。下一个地方呢?比如巴黎天气如何?
这个例子非常清晰地展示了工具调用的核心思想:我们告诉大模型它有哪些工具(尽管这里没有提供正式的Schema,只是通过指令),当用户需求出现时,大模型“决定”要使用某个工具,并以**约定的格式(这里是 get_weather(...) 字符串)**告诉我们它想调用的工具和参数。然后,**外部系统(也就是我们)**负责“执行”这个工具(这里是我们手动提供了天气信息),并将结果“反馈”给大模型,大模型再利用这个信息生成最终的用户回复。
理解了这个“大模型输出指令 -> 外部代码执行 -> 结果反馈回大模型”的循环,你就抓住了Agent工具调用的核心。
现在,我们来看看在实际编程中如何实现这一机制。诀窍在于两个关键点:
- 工具定义 (Tool Definition / Schema): 我们在调用大模型API时,会额外提供一个参数,告诉模型它“拥有”哪些工具,每个工具叫什么名字,是用来做什么的,以及调用它需要哪些参数(参数名、类型、描述)。这通常是通过一个结构化的数据格式来描述,比如JSON Schema。这些信息相当于给了大模型一本“工具书”。
- 结构化输出 (Structured Output): 当大模型在决策阶段认为调用某个工具能更好地完成任务时,它不会直接返回自然语言回复,而是会按照API约定的格式,输出一个结构化的信息,明确指示:“我决定调用工具A,参数是X和Y”。
让我们看看具体如何操作。假设我们有一个read_file函数,用来读取文件内容。我们需要定义它的Schema:
# 这是一个示例的JSON Schema定义
read_file_schema = {
"type": "function",
"function": {
"name": "read_file", # 工具名称
"description": "读取指定路径文件的内容", # 工具描述
"parameters": {
# 参数定义
"type": "object",
"properties": {
"path": {
# 参数名
"type": "string", # 参数类型
"description": "要读取文件的相对路径" # 参数描述
}
},
"required": ["path"] # 必需的参数
}
}
}
在调用支持工具调用的LLM API时(例如OpenAI, Together AI, 或国内一些大模型的Function Calling接口),我们会把这个Schema列表作为参数传进去。
当用户输入“帮我读取 /path/to/your/file.txt 这个文件的内容”时,如果大模型认为read_file工具可以完成这个任务,它就可能返回类似这样的结构化输出:
{
"tool_calls": [
{
"id": "call_abc123", # 调用ID
"type": "function",
"function": {
"name": "read_file", # 模型决定调用的工具名称
"arguments": "{\"path\": \"/path/to/your/file.txt\"}" # 模型决定的参数,通常是JSON字符串
}
}
],
"role": "assistant",
"content": null # 如果模型只调用工具,content可能为空
}
关键点来了: 大模型只是告诉你它“想”干什么,具体的执行必须由我们编写的外部代码来完成。我们的代码需要:
- 检查大模型的回复中是否包含
tool_calls。 - 如果包含,解析出工具的名称 (
function.name) 和参数 (function.arguments)。 - 根据工具名称,调用我们实际定义的Python函数(比如查找一个函数映射表)。
- 执行对应的函数,并将解析出的参数传进去。
- 将函数执行的结果,按照API的要求格式化,添加回对话历史中,并再次调用大模型。这次调用时,大模型就能看到“工具调用的结果是XXX”,然后才能根据这个结果生成最终的用户回复。
理解了这个“大模型输出指令 -> 外部代码执行 -> 结果反馈回大模型”的循环,你就抓住了Agent工具调用的核心。
3. 构建我们的AI编程智能体
现在,我们来实现一个简单的AI编程智能体,它拥有读文件、列文件和编辑文件三个基础的编程工具。我们将代码整合在一起,看看它有多简单。
首先,安装并导入必要的库(这里我们使用一个通用的client对象代表任何支持工具调用的LLM客户端,读者可以根据实际情况替换为OpenAI, Together AI或其他国内厂商的SDK):
# 假设你已经安装了某个支持工具调用的SDK,例如 together 或 openai
# pip install together # 或 pip install openai
import os
import json
from pathlib import Path # 用于处理文件路径
# 这里的 client 只是一个占位符,你需要用实际的LLM客户端替换
# 例如: from together import Together; client = Together()
# 或者: from openai import OpenAI; client = OpenAI()
# 请确保 client 对象支持 chat.completions.create 方法并能处理 tools 参数
class MockLLMClient:
def chat(self):
class Completions:
def create(self, model, messages, tools=None, tool_choice="auto"):
print("\n--- Calling Mock LLM ---")
print("Messages:", messages)
print("Tools provided:", [t['function']['name'] for t in tools] if tools else "None")
print("-----------------------")
# 在实际应用中,这里会调用真实的API并返回模型响应
# 模拟一个简单的工具调用响应
last_user_message = None
for msg in reversed(messages):
if msg['role'] == 'user':
last_user_message = msg['content']
break
if last_user_message:
if "Read the file secret.txt" in last_user_message and tools:
# 模拟模型决定调用 read_file 工具
return MockResponse(tool_calls=[MockToolCall("read_file", '{"path": "secret.txt"}')])
elif "list files" in last_user_message and tools:
# 模拟模型决定调用 list_files 工具
return MockResponse(tool_calls=[MockToolCall("list_files", '{}')])
elif "Create a congrats.py script" in last_user_message and tools:
# 模拟模型决定调用 edit_file 工具
# 这是一个简化的模拟,实际模型会解析出路径和内容
args = {
"path": "congrats.py",
"old_str": "",
"new_str":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











