







 本文介绍了如何使用pyspider爬取空气质量指数网站上的数据,包括安装pyspider、配置PhantomJS、创建爬虫项目、编写代码提取数据,以及数据的初步可视化。在过程中,特别提到了Python版本问题和数据提取表达式的设置方法。
本文介绍了如何使用pyspider爬取空气质量指数网站上的数据,包括安装pyspider、配置PhantomJS、创建爬虫项目、编写代码提取数据,以及数据的初步可视化。在过程中,特别提到了Python版本问题和数据提取表达式的设置方法。
通过编写爬虫程序,实现对空气质量指数网站上指定地区和时间段内的AQI进行获取,并实现数据可视化
实验步骤:
-
安装pyspider
在anaconda prompt中使用命令行安装:

-
若提示升级,则根据提示进行

-
下载PhantomJS,并配置环境变量
可在如下网址中进行下载
https://phantomjs.org/download.html

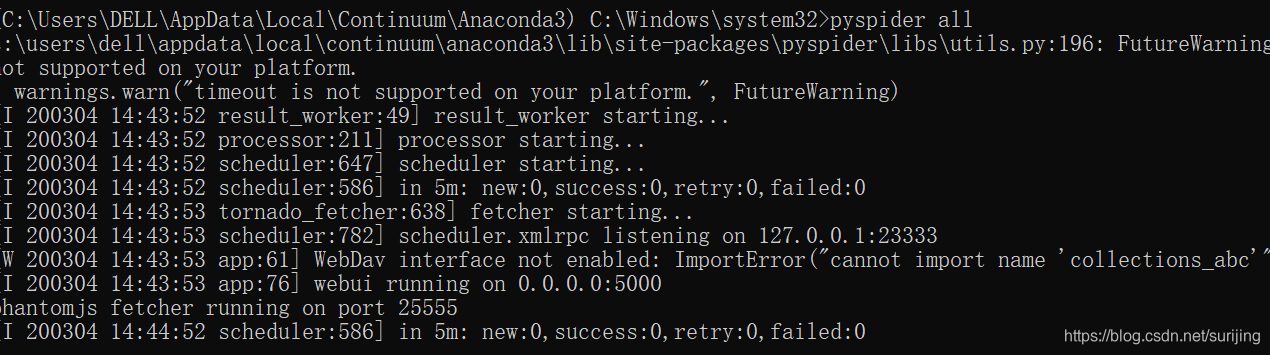
5.用命令行启动pyspider
如果出现下图命令,则启动成功
-
如果,python的版本3.7以上,建议降级,因为会有语言冲突
在命令行输入如下命令:
pip uninstall WsgiDAV==2.4.1 -
启动成功后可以通过默认地址:http://localhost:5000/进入spider web界面
并点击create new project 可以新建爬虫job
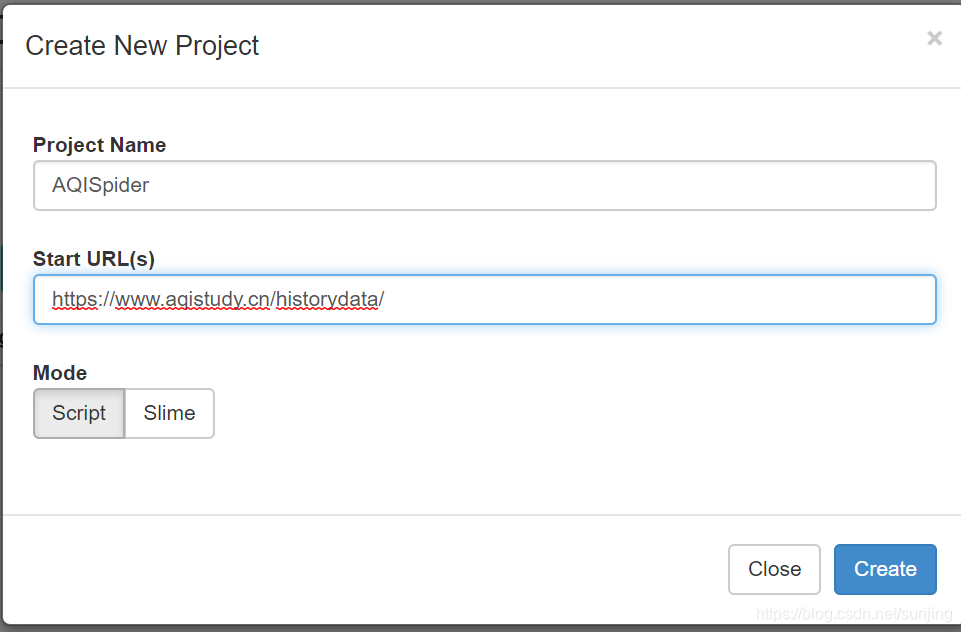
图中的地址便是我要爬取的地址,填写完信息之后点击create -
进入怕成项目编写界面:
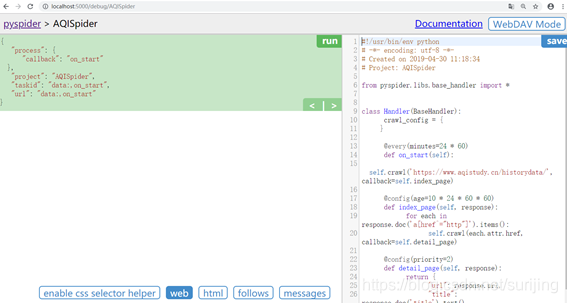
左边是代码调试界面,右边是代码运行结果,点击run 即可运行,每次修改代码之后需要保存(save) -
数据采集
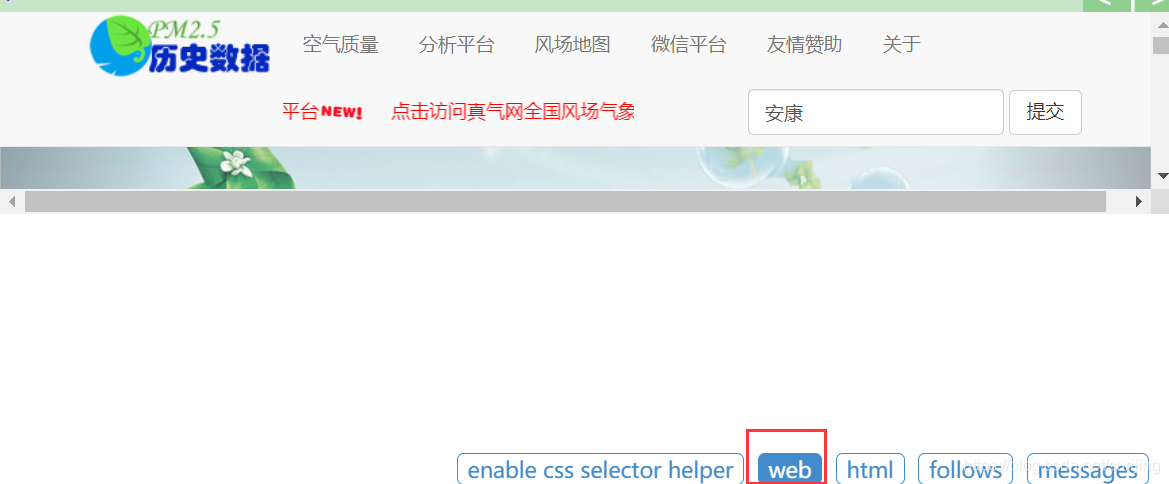
选取要爬取的url
点击右侧的三角按钮
由于url是我们需要的,所以需要修改url获取表达式
点击enable css selector helper,然后点击想要获取的数据,即可生成响应的数据提取表达式:

点击箭头,可以将生成的表达式插入到光标所在的地方,及’div>li>a‘


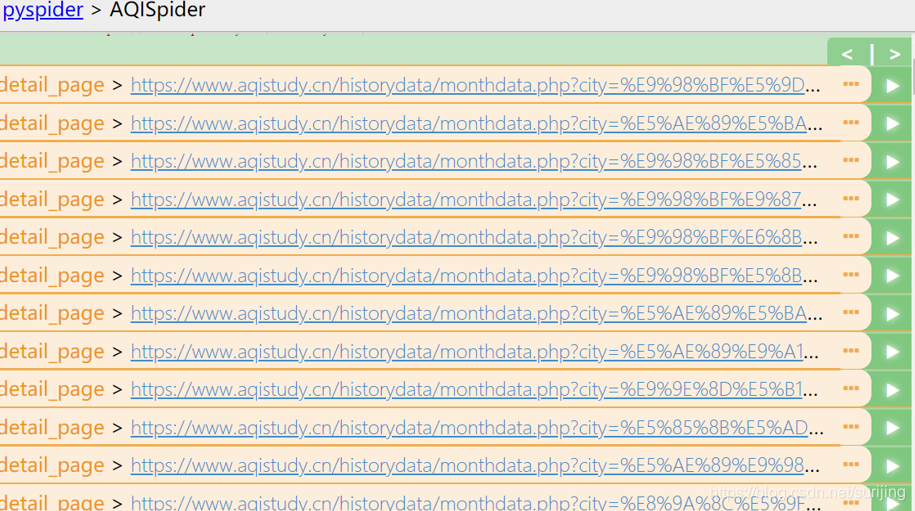
- 获取数据
重新运行之后:
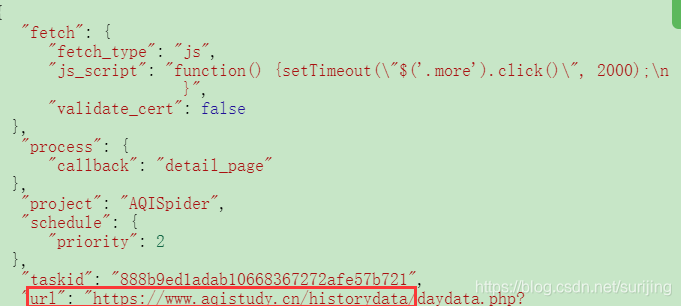
在index_page方法中的self.crawl中加入下面代码:
fetch_type='js',js_script="""function() {setTimeout("$('.more').click()", 2000);
}"""# 等待浏览器加载数据
保存后,再次
在pyspider中生成的代码里Handler类中新建方法:
@config(age=10 * 24 *  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









