






2024年还有哪些百万粉丝公众号?我抓取了下数据2024 批量下载公众号文章内容/阅读数/点赞数/留言数/粉丝数导出pdf文章备份(带留言):
星球研究所这个号2017-2024年的所有历史文章,共586篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月19日粉丝数437万 :
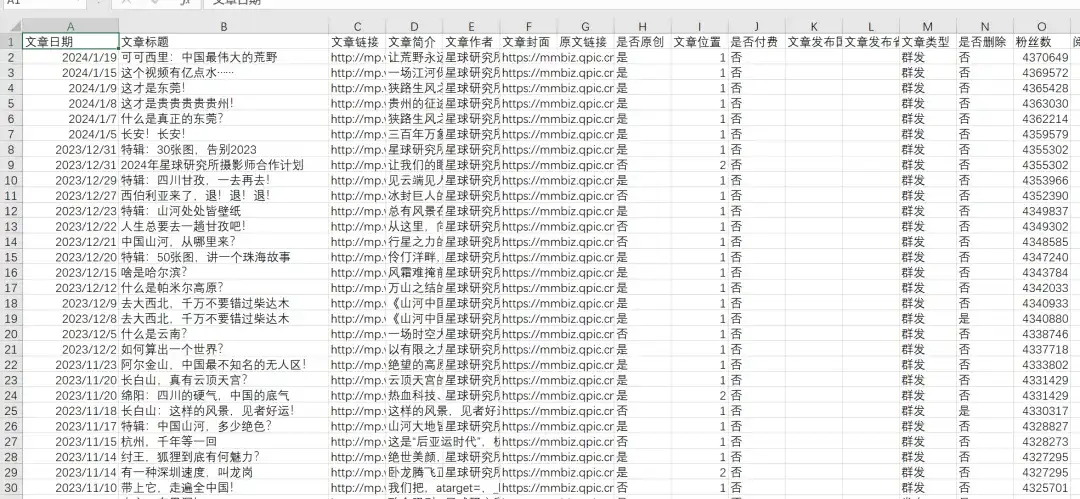
罗翔说刑法这个号2017-2024年的所有历史文章,共389篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月15日粉丝数173万 :
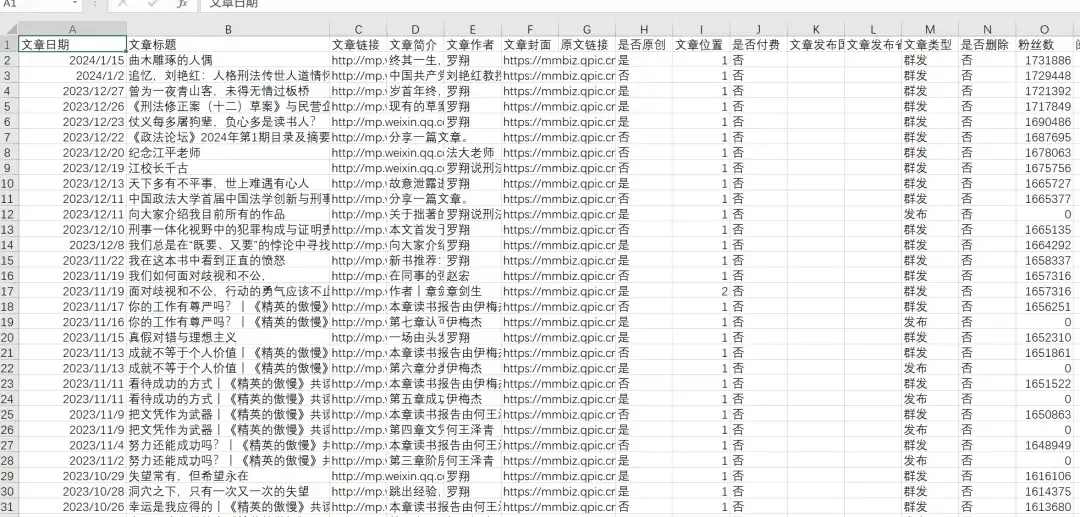
好奇博士这个号2020-2024年的所有历史文章,共3337篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月20日粉丝数625万 :
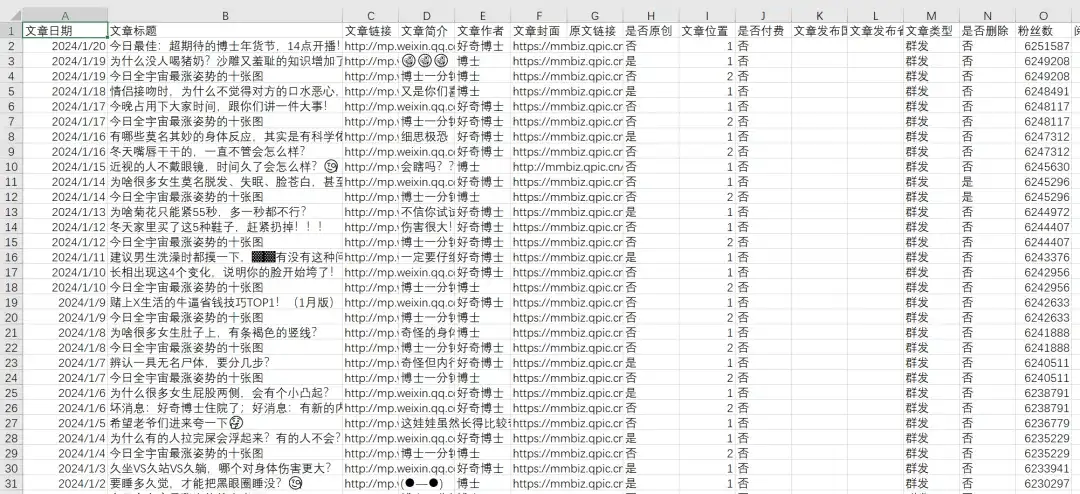
网易数读这个号2015-2024年的所有历史文章,共1234篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月17日粉丝数207万 :
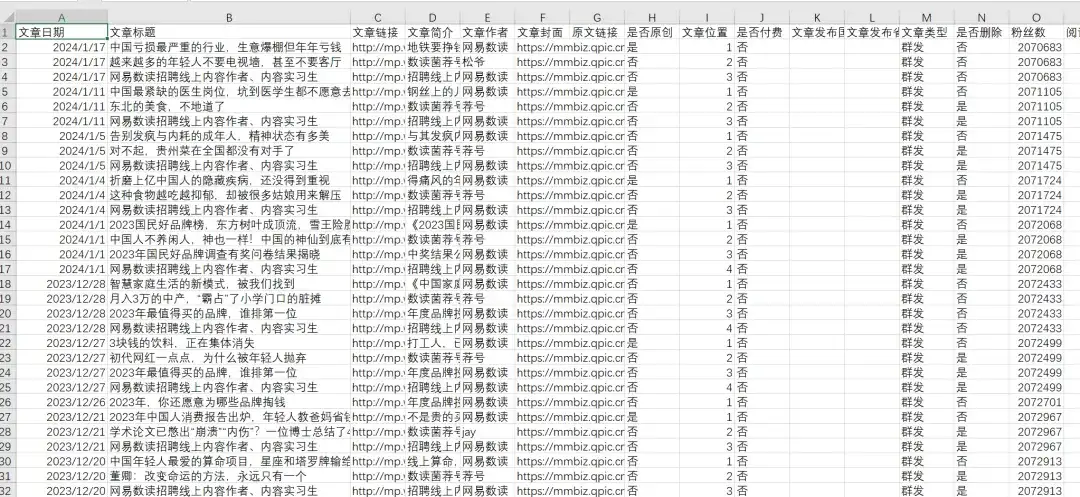
地球知识局这个号2016-2024年的所有历史文章,共5625篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月19日粉丝数294万 :
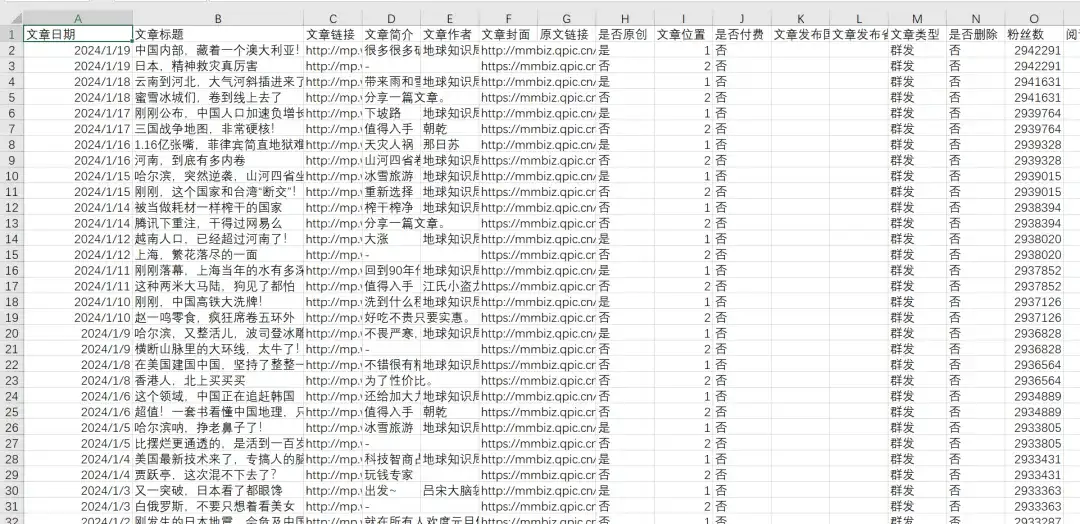
小声比比这个号2022-2024年的所有历史文章,共546篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月19日粉丝数136万 :
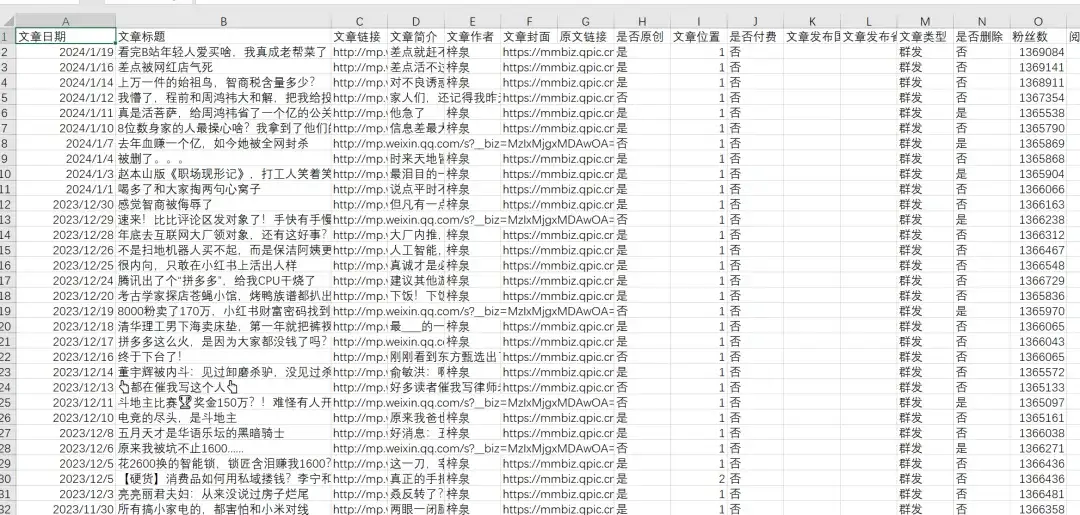
混知这个号2014-2024年的所有历史文章,共1586篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月20日粉丝数752万 :
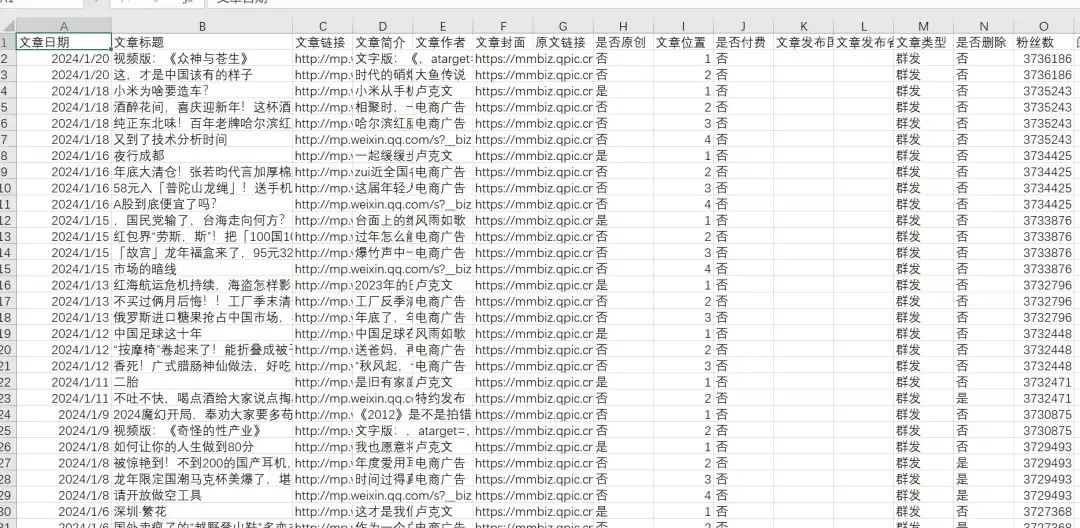
卢克文工作室这个号2015-2024年的所有历史文章,共1034篇,导出的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,2024年1月20日粉丝数373万 :
如果还想分析公众号阅读数据可以看看深圳卫健委这个案例,我抓取了这个号2019-2024年的所有文章数据:
抓取公众号阅读数点赞数在看数留言数做数据分析, 以深圳卫健委这个号为例
视频更新版:批量下载公众号文章内容/话题/图片/封面/音频/视频,导出html,pdf,excel包含阅读数/点赞数/留言数
2023批量下载公众号文章内容/话题/图片/封面/视频/音频,导出html和pdf格式,含阅读数/点赞数/在看数/留言数/赞赏数

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









