






创建表和测试数据:
-- DROP TABLE IF EXISTS people;
CREATE TABLE people (
id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name varchar(50) NOT NULL,
email varchar(100) NOT NULL
);
INSERT INTO people(name, email)
VALUES ('张三', 'zhangsan@test.com'),
('李四', 'lisi@test.com'),
('王五', 'wangwu@test.com'),
('李斯', 'lisi@test.com'),
('王五', 'wangwu@test.com'),
('王五', 'wangwu@test.com');
其中,2 和 4 的 email 字段存在重复数据;3、5 和 6 的 name 和 email 字段存在重复数据
基于多个字段的重复记录:
如果我们想要找出 name 和 email 两个字段都重复的数据,可以基于这两个字段进行分组统计
SELECT *
FROM people
WHERE (name, email) IN (
SELECT name, email
FROM people
GROUP BY name, email
HAVING count(1) > 1)
ORDER BY email;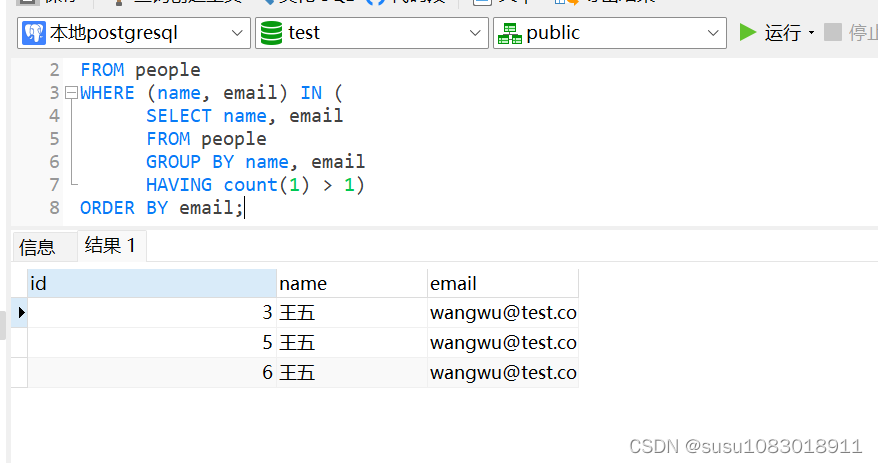
或者:
WITH d AS (
SELECT name, email
FROM people
GROUP BY name, email
HAVING count(*) > 1)
SELECT p.*
FROM people p
JOIN d ON (d.name = p.name AND d.email = p.email)
ORDER BY p.email;
使用窗口函数查找重复记录:
使用聚合函数查找重复记录需要扫描同一个表两次,如果表中的数据量很大时,可能存在性能问题。为此,我们可以采用另一种方法:窗口函数
首先,我们通过 count() 窗口函数找出每个 email 出现的次数:
SELECT id, name, email, count(*) over (partition by email) cnt
FROM people;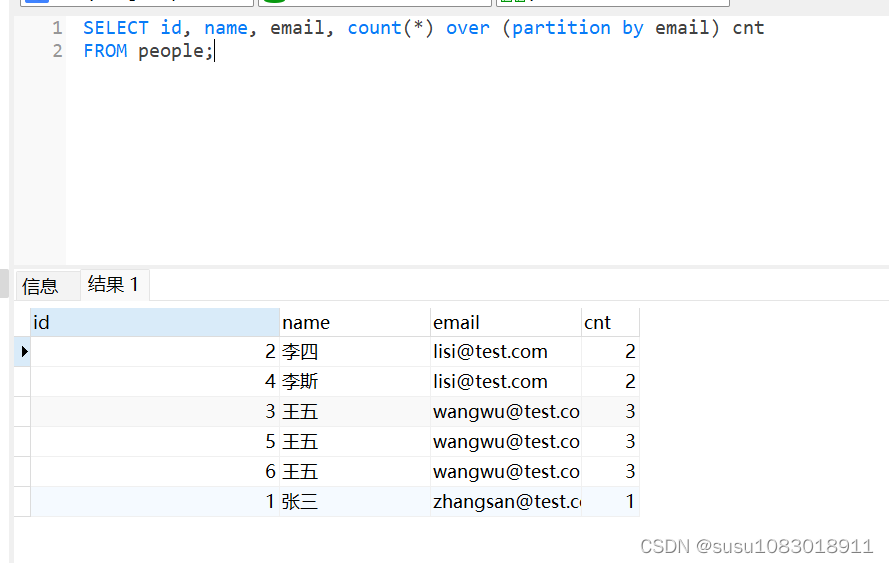
窗口函数不仅可以找出字段的重复次数,同时还可以保留原表中的数据,避免了二次扫描的操作。接下来我们只需要返回次数大于 1 的记录即可:
WITH d AS (
SELECT id, name, email,
count(*) over (partition by email) cnt
FROM people)
SELECT *
FROM d
WHERE cnt > 1
ORDER BY id;
窗口函数同样支持基于多个字段的分区操作,以下语句可以用于找出 name 和 email 两个字段都重复的数据:
WITH d AS (
SELECT id, name, email,
count(*) over (partition by name, email) cnt
FROM people)
SELECT *
FROM d
WHERE cnt > 1
ORDER BY id;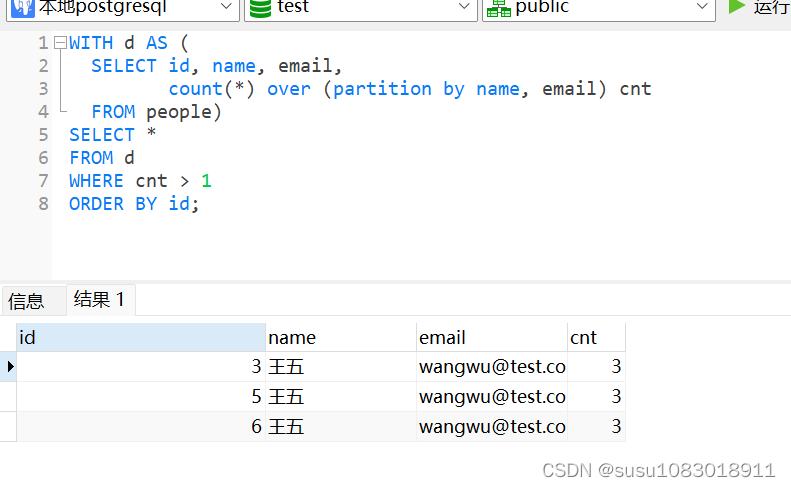
如果需要删除重复记录,请往下看:
使用子查询删除重复记录
假如我们想要删除 email 字段重复的记录,只保留其中 id 最小的一条;可以使用子查询找出需要保留的数据,然后删除其他的数据:
DELETE
FROM
people
WHERE
ID NOT IN ( SELECT MIN ( ID ) FROM people GROUP BY email );也可以使用跨表删除或者关联子查询删除重复的数据:
DELETE
FROM people p
USING people d
WHERE p.email = d.email AND p.id < d.id;DELETE
FROM people p
WHERE p.id NOT IN (
SELECT min(id)
FROM people
WHERE email = p.email
);使用窗口函数删除重复记录
ROW_NUMBER() 窗口函数可以用于将数据进行分组,然后为每一条数据分配一个唯一的数字编号。例如:
SELECT id, name, email,
row_number() over (PARTITION BY email ORDER BY id) AS row_num
FROM people;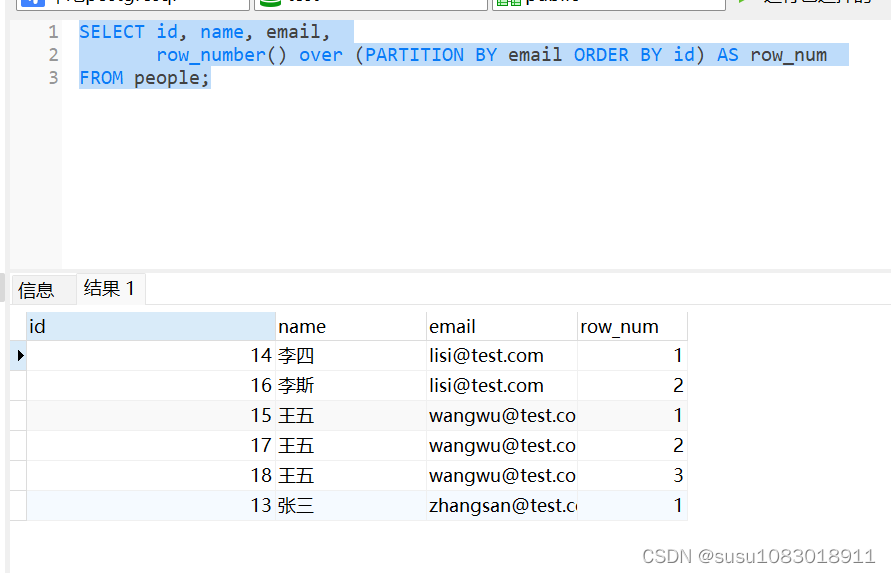
以上语句基于 email 分组(PARTITION BY email),同时按照 id 进行排序(ORDER BY id),然后为每个组内的数据分配一个编号;如果编号大于 1 就意味着存在重复的数据。
我们可以基于该查询结果删除重复的记录:
DELETE
FROM people
WHERE id IN (
SELECT id
FROM (
SELECT id, name, email,
row_number() over (PARTITION BY email ORDER BY id DESC) AS row_num
FROM people) d
WHERE row_num > 1);













 2876
2876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









