







今天又是一学期的选修课抢课的开始,早上起来选完课想用python来实现模拟网页抢课。
这里我们用的是python3.6,抓包工具charles4.2.8。
首先打开校园官网,进入教务管理系统,可以看到下面这个登录界面。
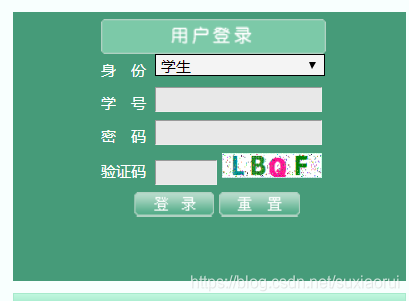
这里我们首先要获取这个验证码图片,那么该怎么获取呢?
我们按F12打开开发者工具,然后点击这个验证码图片,我们就可以抓取到这个验证码网址
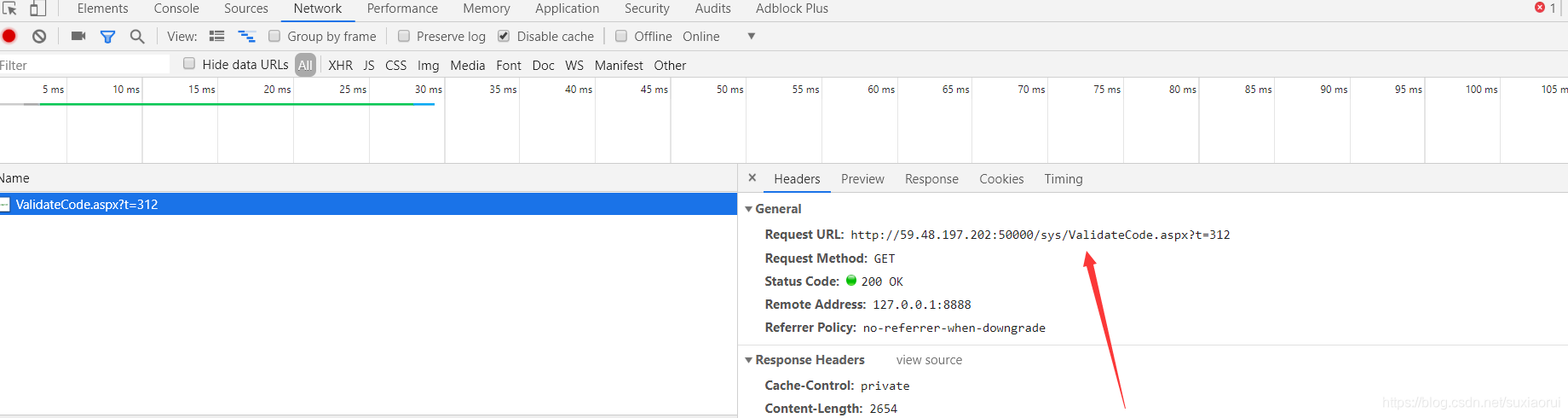
很轻松的就拿到了验证码网址,我们用get求请到这个验证码图片,然后保存到本地。
import requests
yzm_url = "http://59.48.197.202:50000/sys/ValidateCode.aspx"
resp = requests.get(yzm_url)
with open("yzm.jpg","wb")as f:
f.write(resp.content)我们就可以在本地里看到验证码。

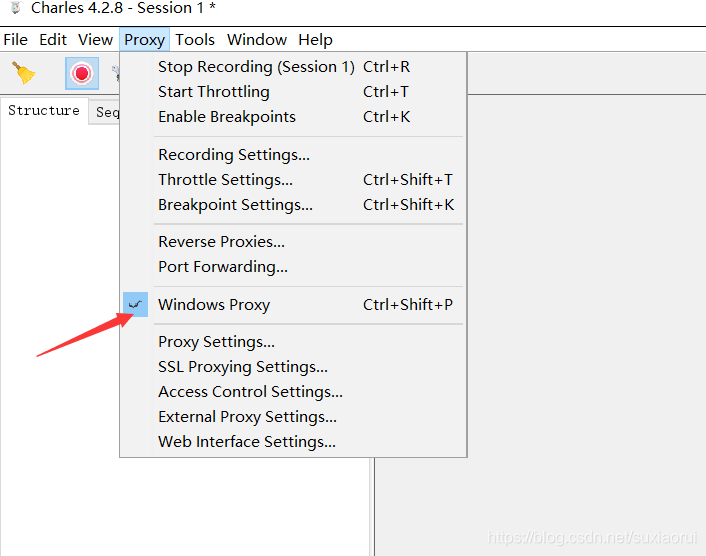
在抓取之前,我们要打开我们的charles工具,同时确保我们安装了相关证书和打开了windows proxy。也就是下面图中
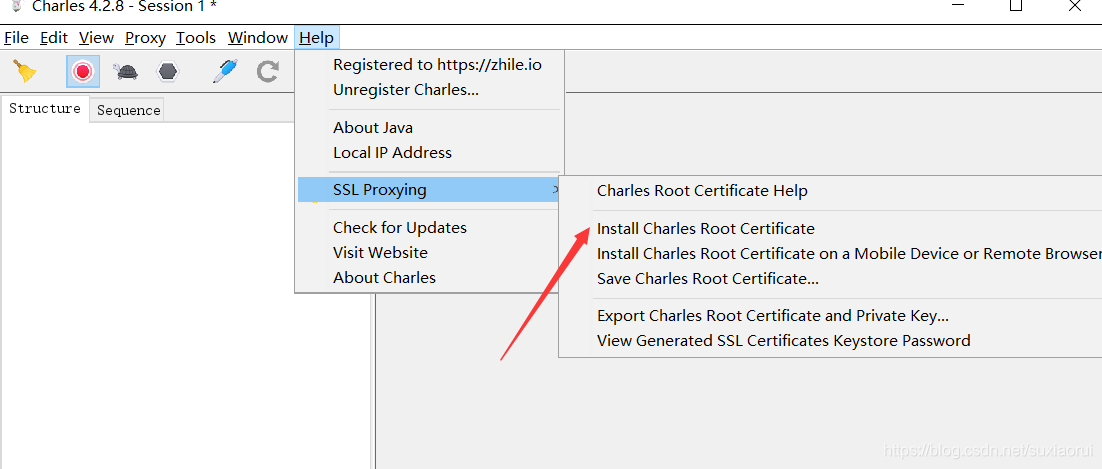
接着点击安装证书
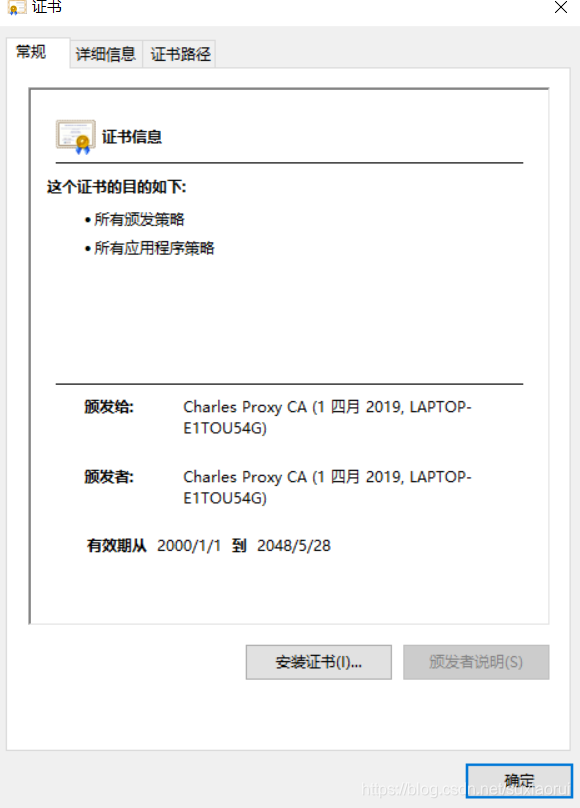
接着选择本地计算机,点击下一步
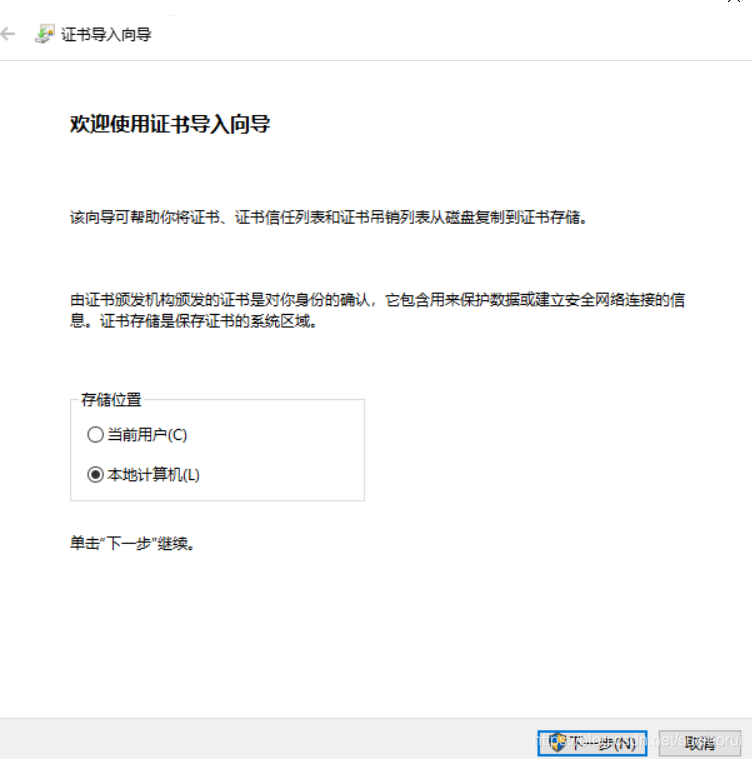
然后选择将所有证书都放入下列存储,点击浏览选择受信任的根证书颁发机构
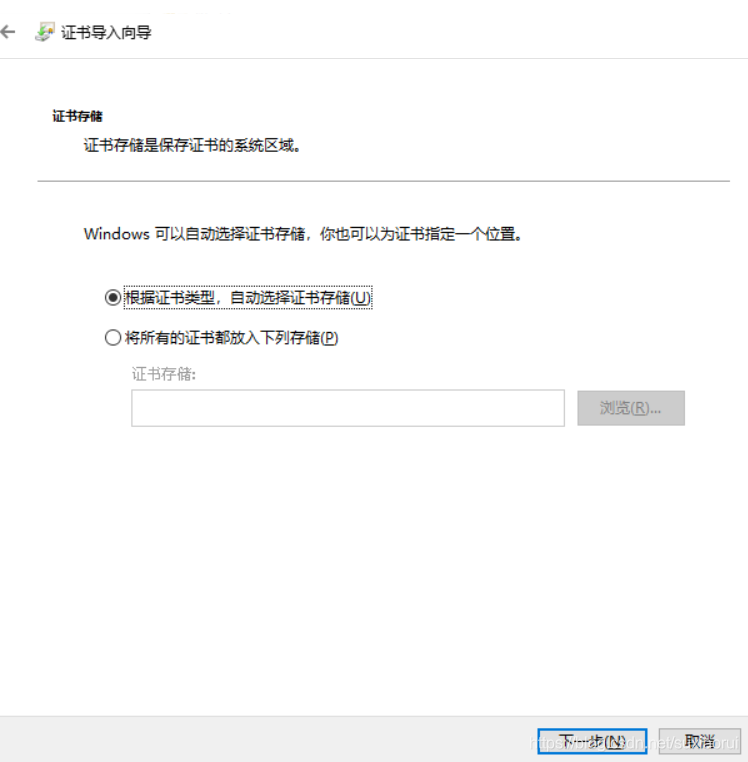
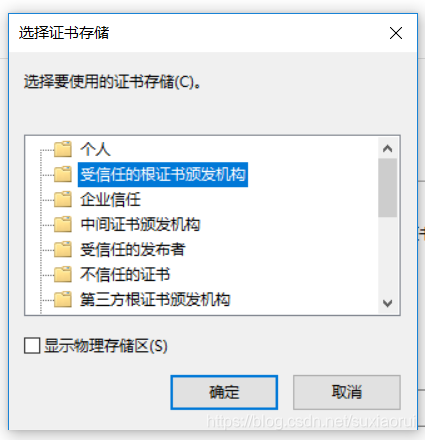
接着点击确定,最后点击完成即安装成功。
现在我们打开软件,将Windows proxy这个设置打开
准备工作已经就绪,我们就要开始了。
接着我们就要模拟登陆这个教务系统,选择学生,输入账号,密码和验证码登陆系统。
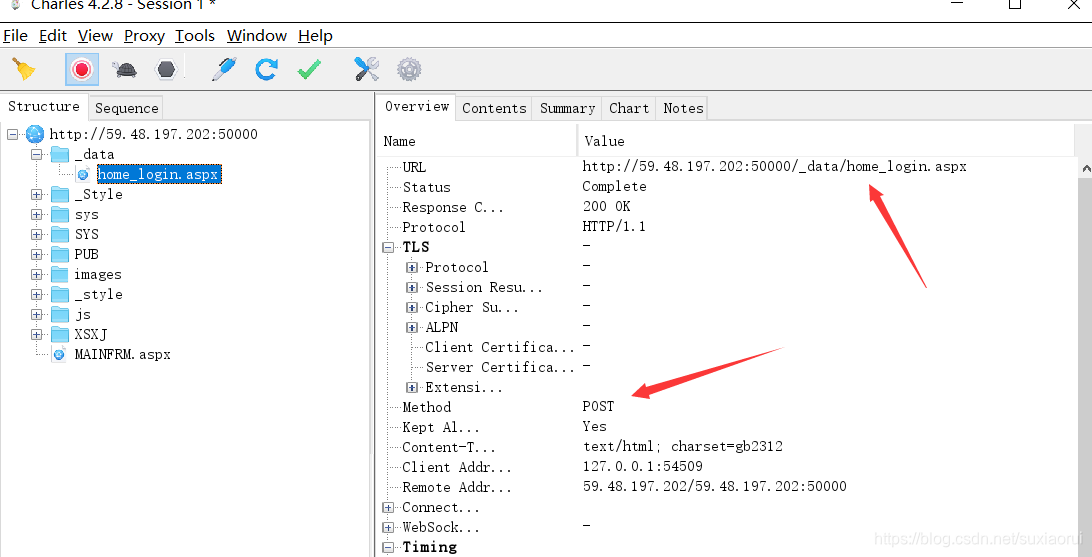
我们可以看到请求方式是post请求,这里我们输入账号、密码和验证码传给服务器, 当然是post请求,同时我们也知道请求网址。我们看一下我们post了哪些data。

很明显我们能看出来Sel_Type STU这个是我们当时登录这个系统选择的学生,因为还有教师等其他的选项。下面就是账号、
密码以及验证码。我们用代码来实现登录。
account = input("请输入你的账号")
pwd = input("请输入你的密码")
answer = input("请输入验证码答案:")
check_url = "http://59.48.197.202:50000/_data/home_login.aspx"
data = {
# Sel_Type: STU
# UserID: 账号
# PassWord: 密码
# cCode: f7gc
"Sel_Type":"STU",
"UserID": account,
"PassWord": pwd,
"cCode": answer
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
login_resp = requests.post(check_url,data=data,headers=headers)
# print(login_resp.text)
cookie = login_resp.cookies上面代码就可以实现模拟登录,这里我们要说一下最后一行代码cookie = login_resp.cookies.
为什么这里要保存cookie值呢,因为选课网址是另一个,这个cookie是服务器给我们的,我们访问选课网址,发送这个cookie就可以被允许访问。
下面我们看一下这个选课界面
点击检索,然后我们可以在抓包工具中看到
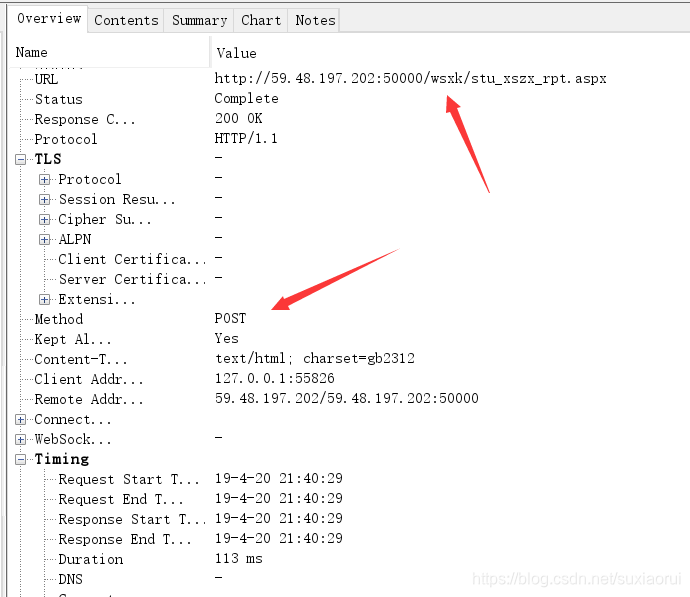
可以看到这个也是一个post请求。我们可以看请求头中有cookie值,所以我们一会发送求请时要带上cookie值。
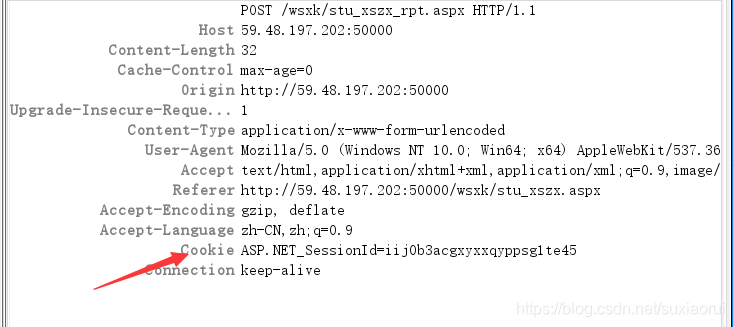
接下来我们再看一下要发送data值。
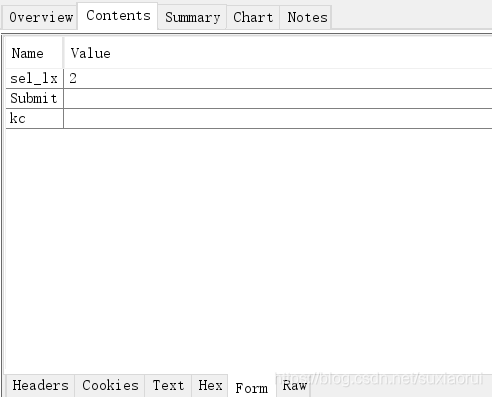
这里的 sel_lx 2是我们检索之前要选的那个公共选修课,它是下拉选项框中的第二个,所以也得发送个这个值。
我们用代码实现如下
choice_url = "http://59.48.197.202:50000/wsxk/stu_xszx_rpt.aspx"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.368",
"Cookie": "ASP.NET_SessionId=w1fkgc45132ox145rdlwap55"
}
data={
"sel_lx": "2",
}
check_resp = requests.post(choice_url,data=data,headers=headers)
result = check_resp.text
print(check_resp.text)这下就可以看到这个页面,当然我们可以通过xpath、正则、BeautifulSoup或者css选择器其中一种类解析。
这里我们选择用BeautifulSoup库类解析。
from bs4 import BeautifulSoup
oup = BeautifulSoup(result,'lxml')
data_list = []
for idx, tr in enumerate(soup.find_all('tr')):
if idx != 0:
tds = tr.find_all('td')
data_list.append({
'课程名称': tds[0].contents[0]
})
print(data_list)我们就可以看到我们 有什么选修课,以及选修课对应的一种编号。
下面我们可以举个例子,比如我们要报这个cad计算机绘图选修课
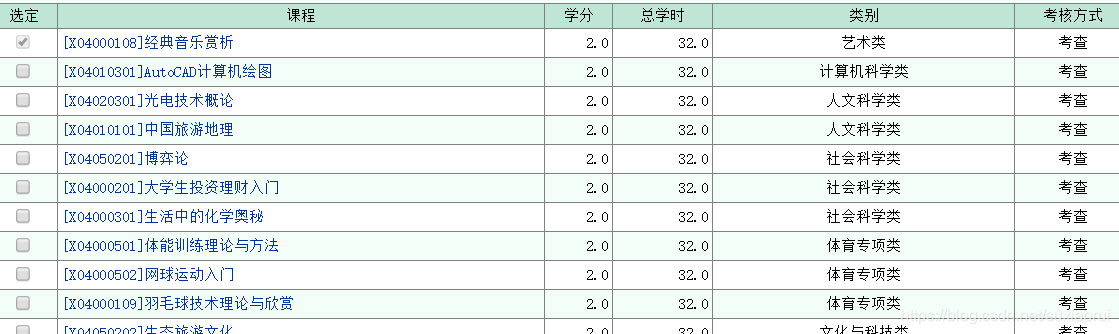
我们要先选择好课程,然后提交。抓包工具抓到数据如下
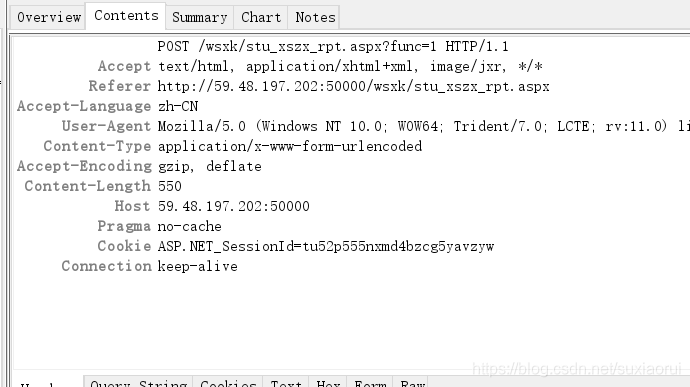
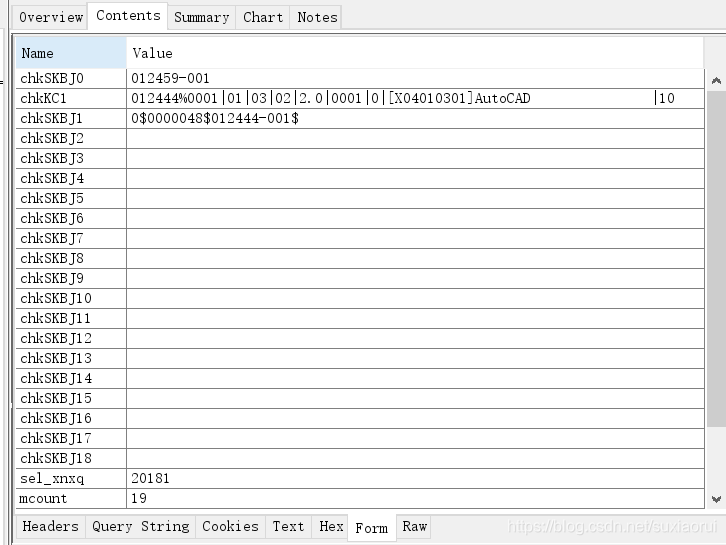
这里的data值有很多,我们可以在charles中试试删除多个值,看看能不能收到响应 。
点击这个像钢笔一样的符号。就会给我们默认复制一个,我们可以进行修改再发送请求。
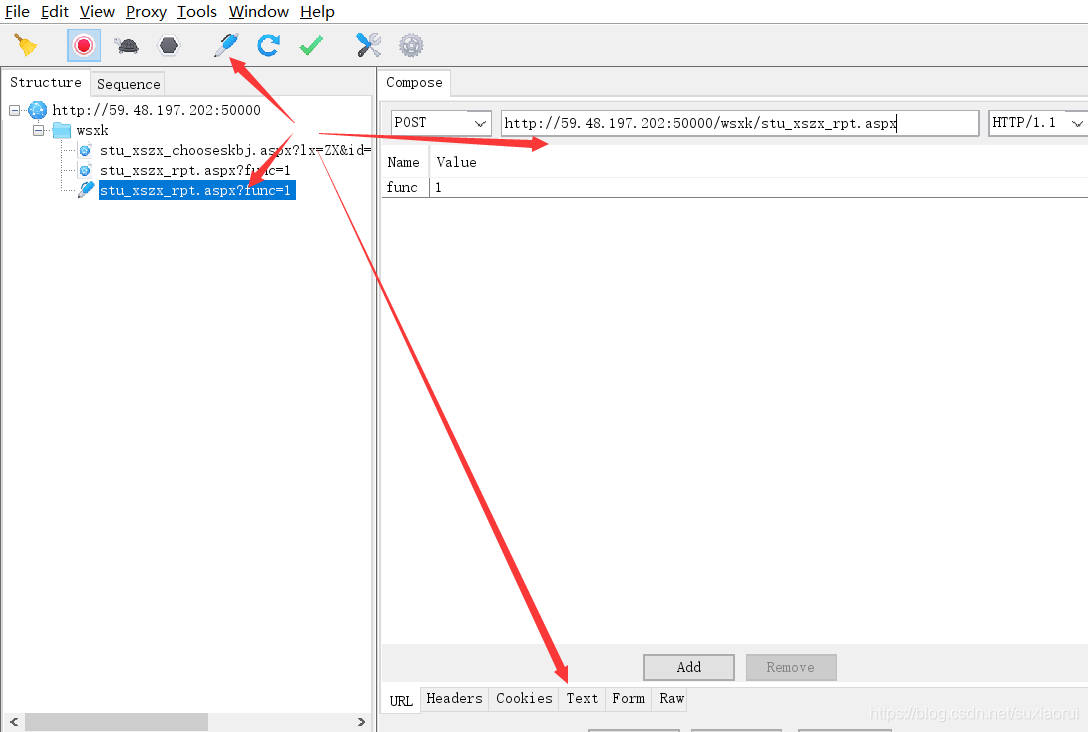
这里我们尝试删除了很多值,就剩下最后一个,发现发送求请依旧可以获得响应。
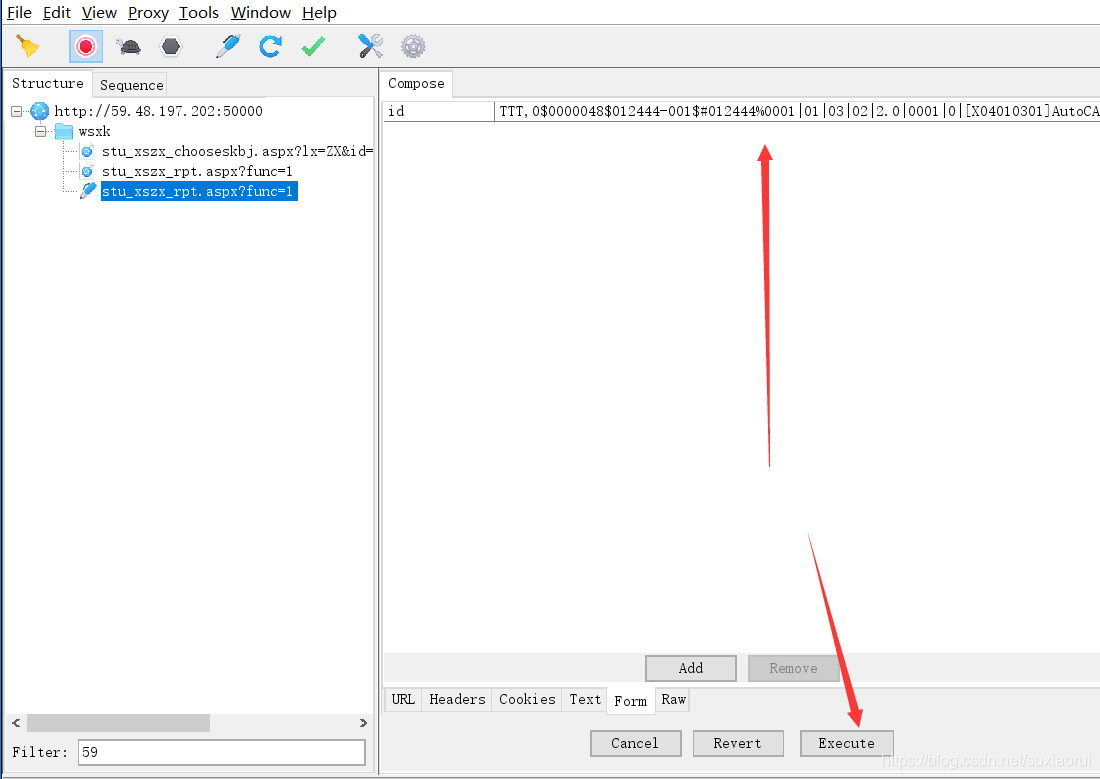
这里我们用代码实现
zx_url = "http://59.48.197.202:50000/wsxk/stu_xszx_rpt.aspx?func=1"
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; LCTE; rv:11.0) like Gecko",
"Cookie": "ASP.NET_SessionId=w1fkgc45132ox145rdlwap55"
}
data = {
"id": "TTT,0$0000048$012444-001$#012444%0001|01|03|02|2.0|0001|0|[X04010301]AutoCAD�"
}
zx_resp = requests.post(zx_url,data=data,headers=headers)这里我们打开校园官网,看到我们的正选结果就多了一个
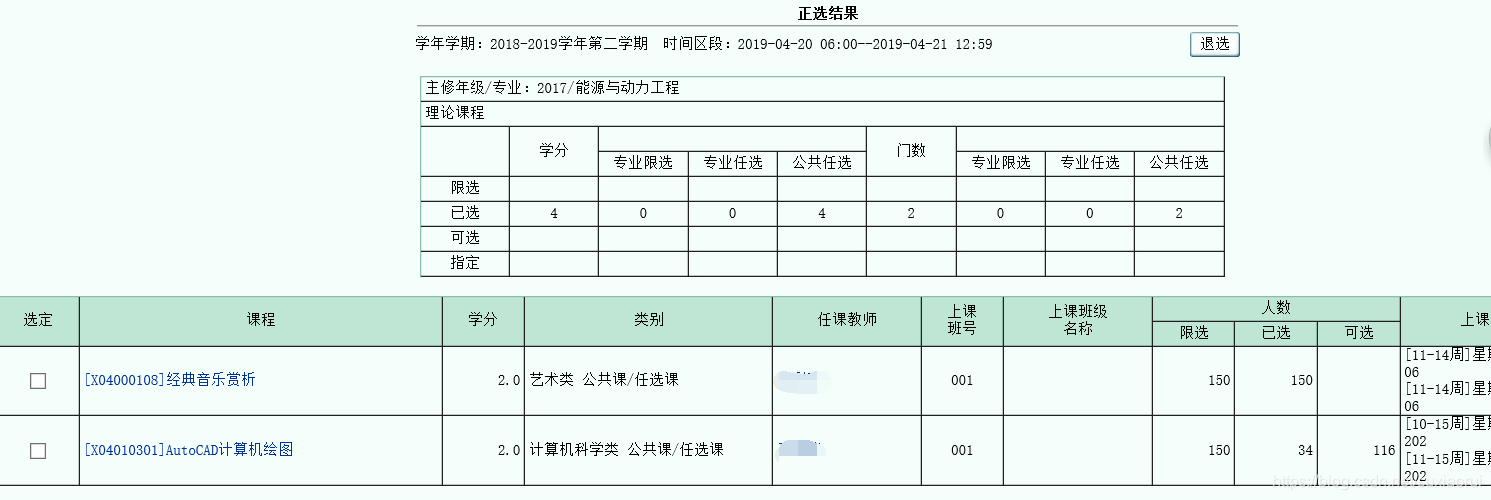
这下我们就简单的实现了我们的选课过程,我们也可以解析选课界面,将所有课程情况保存下来,包括课程号一些数据,因为最后一步提交选课需要传递课程编号。验证码再加上智能识别或者运用打码平台进行识别,那样我们就可以做一个完整的抢课
程序。还有最后附上完整代码,代码并没有优化。
import requests
from bs4 import BeautifulSoup
yzm_url = "http://59.48.197.202:50000/sys/ValidateCode.aspx?t=531"
resp = requests.get(yzm_url)
with open("xuexiao_yzm.jpg","wb")as f:
f.write(resp.content)
# 回答验证码
account = input("请输入你的账号:")
pwd = input("请输入你的密码:")
answer = input("请输入验证码答案:")
check_url = "http://59.48.197.202:50000/_data/home_login.aspx"
data = {
"pcInfo": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/73.0.3683.103 Safari/537.36undefined5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36 SN:NULL",
"typeName": "(unable to decode value)",
"Sel_Type":"STU",
"UserID": account,
"PassWord":pwd,
"cCode": answer
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
login_resp = requests.post(check_url,data=data,headers=headers)
# print(login_resp.text)
cookie = login_resp.cookies
# 选课页面
choice_url = "http://59.48.197.202:50000/wsxk/stu_xszx_rpt.aspx"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.368",
"Cookie": "ASP.NET_SessionId=w1fkgc45132ox145rdlwap55"
}
data={
"sel_lx": "2",
}
check_resp = requests.post(choice_url,data=data,headers=headers)
result = check_resp.text
# 选cad
zx_url = "http://59.48.197.202:50000/wsxk/stu_xszx_rpt.aspx?func=1"
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; LCTE; rv:11.0) like Gecko",
"Cookie": "ASP.NET_SessionId=w1fkgc45132ox145rdlwap55"
}
data = {
"id": "TTT,0$0000048$012444-001$#012444%0001|01|03|02|2.0|0001|0|[X04010301]AutoCAD�"
}
zx_resp = requests.post(zx_url,data=data,headers=headers)


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











