







VGG和AlexNet
VGG-Net不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。另外一个不同的地方是:VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
如果一个 deep architecture 只有 convolutional layer, 那么 input image 可以任意大小,可是一旦在convolutional layer 上面叠加上 fully connected layer,input image大小就需要固定了,因为Dense层规定了输入大小。
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
vgg16 的代码https://github.com/fchollet/keras/blob/master/keras/applications/vgg16.py
GoogleNet
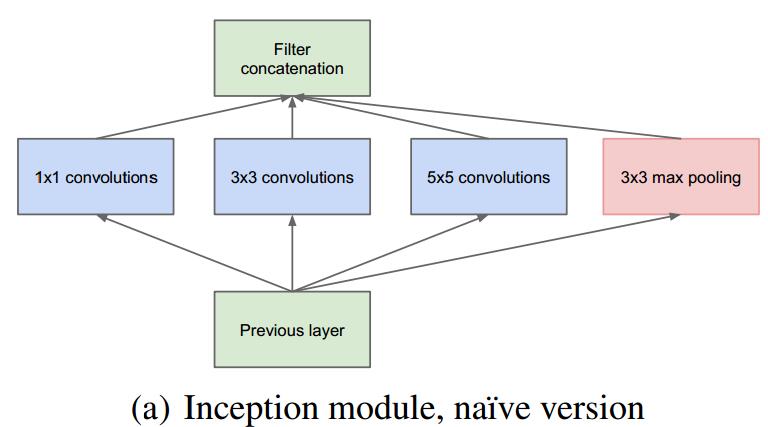
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
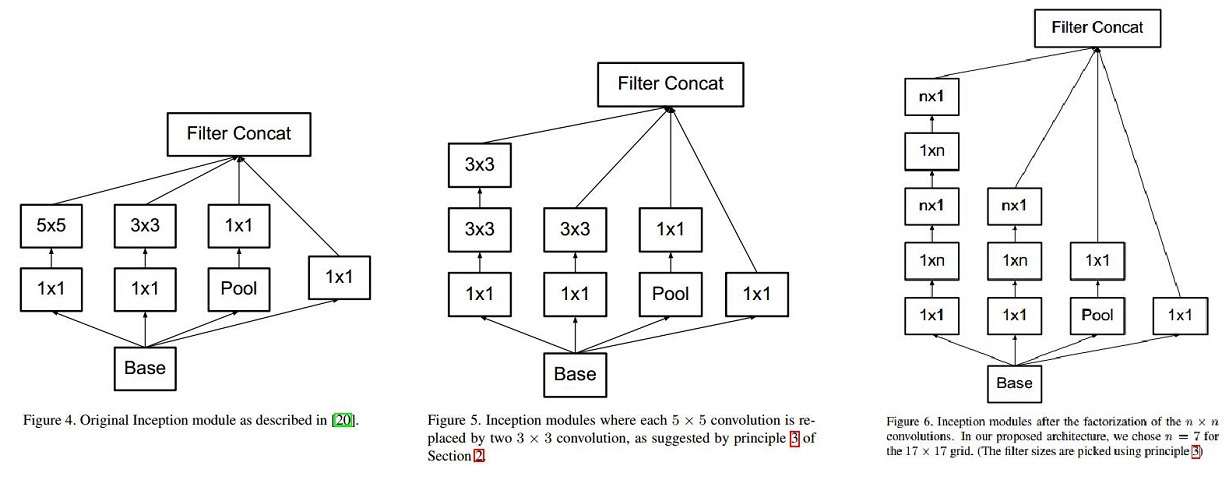
(1)googleNet V1中使用的inception结构
使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维(减少深度)。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
(2)用3x3卷积序列代替大卷积核
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,(保持感受野范围的同时又减少了参数量)如下图:
(3)googleNet V2使用nx1卷积来代替大卷积核,设定n=7来应对17x17大小的feature map
下图为整体结构图
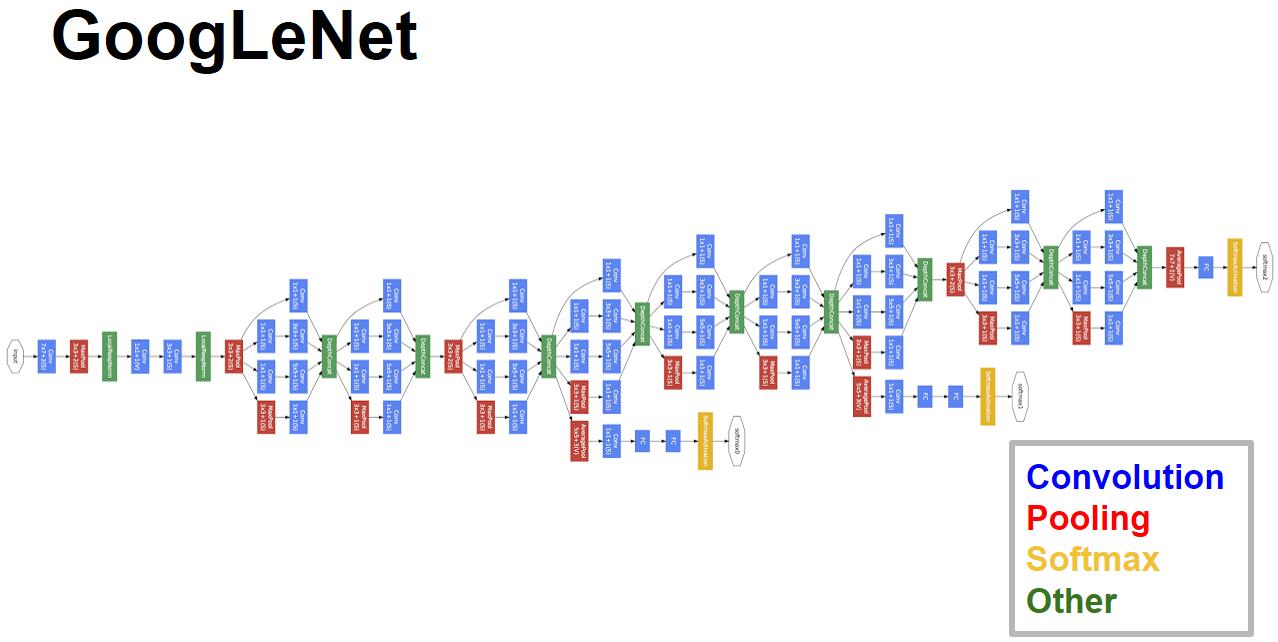
对上图做如下说明:
1 . 显然GoogLeNet采用了模块化的结构,方便增添和修改;
2 . 网络最后采用了average pooling来代替全连接层,想法来自NIN,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
代码实现https://github.com/fchollet/keras/blob/master/keras/applications/resnet50.py
参考http://blog.csdn.net/shuzfan/article/details/50738394
Resnet
resnet要解决的问题:深度学习的深度对最后的分类和识别的效果具有很大的影响,正常的想法是加深网络的深度来提高网络的准确率,但是由于深度神经网络具有梯度消失的弊端,网络的训练效果并不会比浅层的神经网络好太多。将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。右图是deeper的residual block:

以下是identity_block的代码,表示block的输入和输出直接add。为恒等映射。
x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size,
padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
x = layers.add([x, input_tensor])
x = Activation('relu')(x)以下是conv_block的代码,输出经过1x1的conv以及batchnorm之后与输出进行add计算。当输出与输入的尺寸不同时,需要用到conv_block,用来改变输入的尺寸。(途中的虚线部分)
x = Conv2D(filters1, (1, 1), strides=strides,
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same',
name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides,
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(axis=bn_axis, name=bn_name_base + '1')(shortcut)
x = layers.add([x, shortcut])
x = Activation('relu')(x)RCNN(基于区域的CNN)
RCNN 是CNN+SVM,CNN用于提取特征,SVM用于对提取的特征分类。RCNN主要用于目标的检测。(区分分类,检测,分割)
按照一定的算法(《search for object recognition》)在图片中选定一定数量的候选框,将这些大小不同的候选框尺寸resize成相同尺寸,丢入CNN网络结构中(VGG,Alxnet)进行学习,将f7、f6的提取到的特征作为SVM分类的特征,对每个候选框进行分类。
为什么不用CNN直接对候选框分类,还需要一个SVM?
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。
首先输入一张图片,我们先定位出2000个物体候选框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,接着采用svm算法对各个候选框中的物体进行分类识别。也就是总个过程分为三个程序:a、找出候选框;b、利用CNN提取特征向量;c、利用SVM进行特征向量分类。具体的流程如下图片所示:
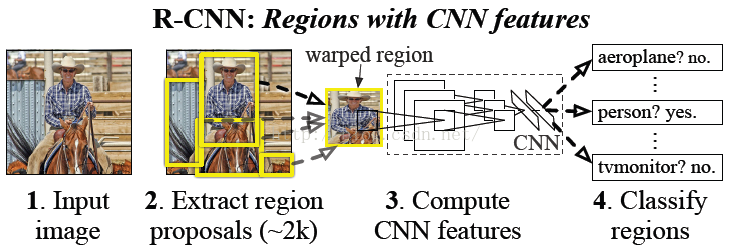
RCNN参考 http://blog.csdn.net/hjimce/article/details/50187029
SqueezeNet
网络瘦身,使网络拥有更少的参数。使用的模块为fire。

firemodel
对输入进行1x1的卷积,filter为16(squeeze),之后,又分别进行1x1的卷积,padding为valid(left);3x3的卷积,padding为same(right);filter为64(expand),对left和right进行concatenate
- s1: squeeze部分,1×1卷积层的通道数
- e1: expand部分,1×1卷积层的通道数
- e3: expand部分,3×3卷积层的通道数
x = Convolution2D(squeeze, (1, 1), padding='valid', name=s_id + sq1x1)(x)
x = Activation('relu', name=s_id + relu + sq1x1)(x)
left = Convolution2D(expand, (1, 1), padding='valid', name=s_id + exp1x1)(x)
left = Activation('relu', name=s_id + relu + exp1x1)(left)
right = Convolution2D(expand, (3, 3), padding='same', name=s_id + exp3x3)(x)
right = Activation('relu', name=s_id + relu + exp3x3)(right)
x = concatenate([left, right], axis=channel_axis, name=s_id + 'concat')net
x = Convolution2D(64, (3, 3), strides=(2, 2), padding='valid', name='conv1')(img_input)
x = Activation('relu', name='relu_conv1')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool1')(x)
x = fire_module(x, fire_id=2, squeeze=16, expand=64)
x = fire_module(x, fire_id=3, squeeze=16, expand=64)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool3')(x)
x = fire_module(x, fire_id=4, squeeze=32, expand=128)
x = fire_module(x, fire_id=5, squeeze=32, expand=128)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool5')(x)
x = fire_module(x, fire_id=6, squeeze=48, expand=192)
x = fire_module(x, fire_id=7, squeeze=48, expand=192)
x = fire_module(x, fire_id=8, squeeze=64, expand=256)
x = fire_module(x, fire_id=9, squeeze=64, expand=256)
















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









