







1、什么是JVM?
JVM本质上就是一个软件,是计算机硬件的一层软件抽象,在这之上才干够运行Java程序,JAVA在编译后会生成相似于汇编语言的JVM字节码,与C语言编译后产生的汇编语言不同的是,C编译成的汇编语言会直接在硬件上跑。但JAVA编译后生成的字节码是在JVM上跑,须要由JVM把字节码翻译成机器指令。才能使JAVA程序跑起来。
JVM运行在操作系统上,屏蔽了底层实现的差异。从而有了JAVA吹嘘的平台独立性和Write Once Run Anywhere。依据JVM规范实现的详细虚拟机有几十种,主流的JVM包括Hotspot、Jikes RVM等。都是用C/C++和汇编编写的,每一个JRE编译的时候针对每一个平台编译。因此下载JRE(JVM、Java核心类库和支持文件)的时候是分平台的,JVM的作用是把平台无关的.class里面的字节码翻译成平台相关的机器码,来实现跨平台。
2、什么是DVM,和JVM有什么不同?
JVM是Java Virtual Machine。而DVM就是Dalvik Virtual Machine,是安卓中使用的虚拟机。全部安卓程序都运行在安卓系统进程里。每一个进程相应着一个Dalvik虚拟机实例。
他们都提供了对象生命周期管理、堆栈管理、线程管理、安全和异常管理以及垃圾回收等重要功能,各自拥有一套完整的指令系统,下面简要对照两种虚拟机的不同。
①JAVA虚拟机运行的是JAVA字节码,Dalvik虚拟机运行的是Dalvik字节码
JAVA程序经过编译。生成JAVA字节码保存在class文件里,JVM通过解码class文件里的内容来运行程序。而DVM
运行的是Dalvik字节码,全部的Dalvik字节码由JAVA字节码转换而来,并被打包到一个DEX(Dalvik Executable)可运行文件里,DVM通过解释DEX文件来运行这些字节码。
②Dalvik可运行文件体积更小
下面是JVM规范中以C的数据结构表达的class文件结构,class文件被虚拟机载入到内存中后便是这样
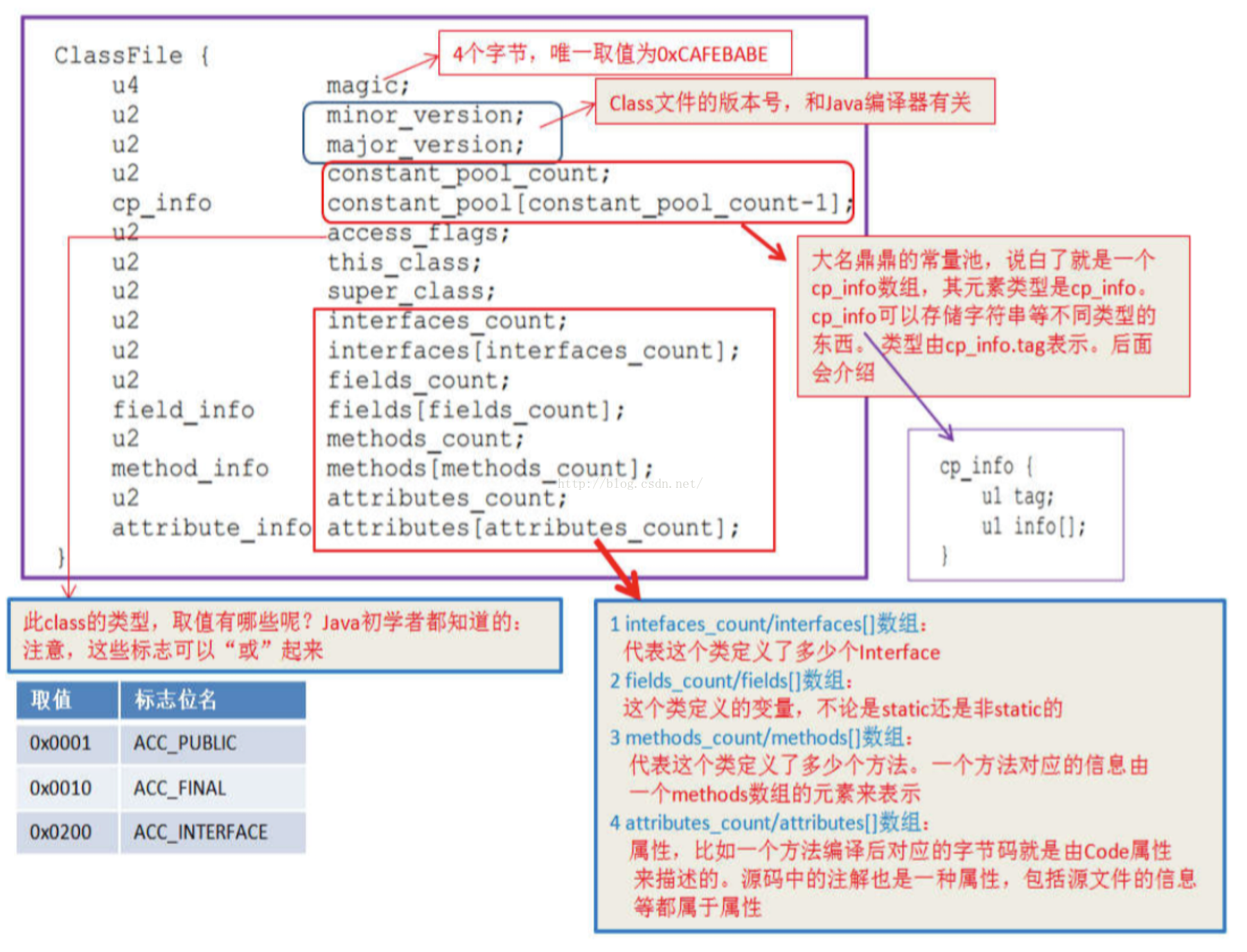
class文件里包括多个不同的方法签名,假设A类文件引用B类文件里的方法,方法签名也会被拷贝到A类文件里(在虚拟机载入类的连接阶段将会使用该签名链接到B类的相应方法),也就是说。多个不同的类会同一时候包括相同的方法签名。相同地,大量的字符串常量在多个类文件里也被反复使用,这些冗余信息会直接添加文件的体积,而JVM在把描写叙述类的数据从class文件载入到内存时,须要对数据进行校验、转换解析和初始化,终于才形成能够被虚拟机直接使用的JAVA类型,由于大量的冗余信息。会严重影响虚拟机解析文件的效率。
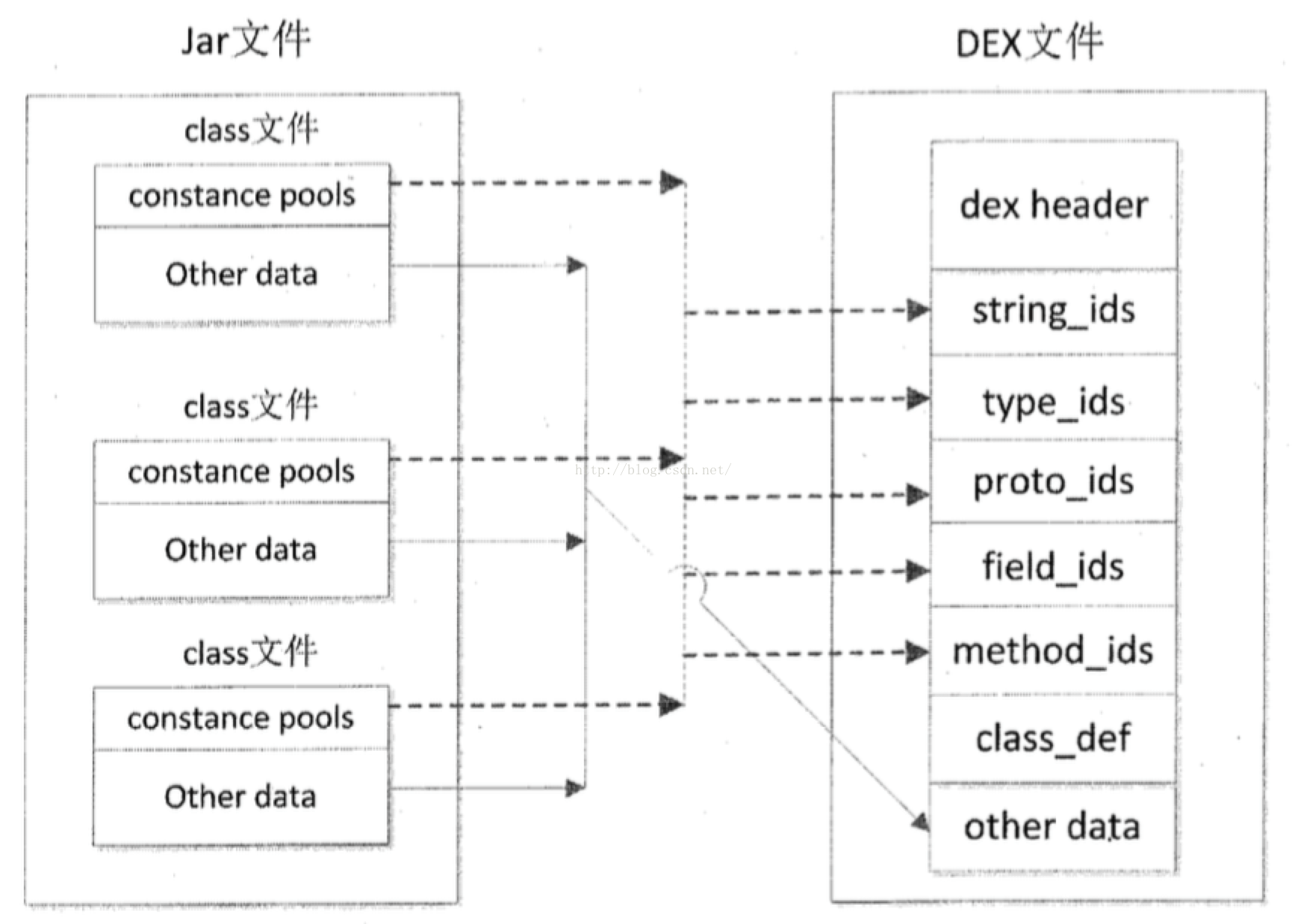
为了减小运行文件的体积,安卓使用Dalvik虚拟机,SDK中有个dx工具负责将JAVA字节码转换为Dalvik字节码。dx工具对JAVA类文件又一次排列,将全部JAVA类文件里的常量池分解,消除当中的冗余信息。又一次组合形成一个常量池。全部的类文件共享同一个常量池。使得相同的字符串、常量在DEX文件里仅仅出现一次,从而减小了文件的体积。
dx工具的转换过程和DEX文件的结构例如以下图所看到的。
③JVM基于栈。DVM基于寄存器
JAVA虚拟机基于栈结构,程序在运行时虚拟机须要频繁的从栈上读取写入数据,这个过程须要很多其它的指令分派与内存訪问次数。会耗费非常多CPU时间。
Dalvik虚拟机基于寄存器架构。数据的訪问通过寄存器间直接传递。这种訪问方式比基于栈方式要快非常多。
public class Hello {
public int foo(int a, int b) {
return (a + b) * (a - b);
}
public static void main(String[] args) {
Hello t = new Hello();
System.out.print(t.foo(5, 3));
}
}以这段代码中的foo方法为例。编译成class文件后。反编译class文件查看JAVA字节码:
Code:
0: iload_1
1: iload_2
2: iadd
3: iload_1
4: iload_2
5: isub
6: imul
7: ireturn相同代码的foo方法。编译生成dex文件后,查看Dalvik字节码:
0000: add-int v0, v3, v4
0002: sub-int v1, v3, v4
0004: mul-int/2addr v0, v1
0005: return v0
由以上字节码对照,代码指令降低了,运行速度当然也会更快。
下图为两种虚拟机分别运行自己的字节码的过程对照。

3、什么是ART虚拟机,和JVM/DVM有什么不同?
首先了解JIT(Just In Time。即时编译技术)和AOT(Ahead Of Time,预编译技术)两种编译模式。
JIT以JVM为例,javac把程序源代码编译成JAVA字节码,JVM通过逐条解释字节码将其翻译成相应的机器指令。逐条读入,逐条解释翻译,运行速度必定比C/C++编译后的可运行二进制字节码程序慢,为了提高运行速度,就引入了JIT技术。JIT会在运行时分析应用程序的代码。识别哪些方法能够归类为热方法。这些方法会被JIT编译器编译成相应的汇编代码。然后存储到代码缓存中。以后调用这些方法时就不用解释运行了。能够直接使用代码缓存中已编译好的汇编代码。
这能显著提升应用程序的运行效率。(安卓Dalvik虚拟机在2.2中添加了JIT)
相对的AOT就是指C/C++这类语言。编译器在编译时直接将程序源代码编译成目标机器码,运行时直接运行机器码。
Dalvik虚拟机运行的是dex字节码,ART虚拟机运行的是本地机器码
Dalvik运行的是dex字节码,依靠JIT编译器去解释运行。运行时动态地将运行频率非常高的dex字节码翻译成本地机器码,然后在运行,可是将dex字节码翻译成本地机器码是发生在应用程序的运行过程中,而且应用程序每一次又一次运行的时候,都要又一次做这个翻译工作,因此,及时採用了JIT,Dalvik虚拟机的整体性能还是不能与直接运行本地机器码的ART虚拟机相比。
安卓运行时从Dalvik虚拟机替换成ART虚拟机。并不要求开发人员又一次将自己的应用直接编译成目标机器码,也就是说,应用程序仍然是一个包括dex字节码的apk文件。
所以在安装应用的时候。dex中的字节码将被编译成本地机器码,之后每次打开应用,运行的都是本地机器码。移除了运行时的解释运行。效率更高,启动更快。(安卓在4.4中公布了ART运行时)
ART长处:
①系统性能显著提升
②应用启动更快、运行更快、体验更流畅、触感反馈更及时
③续航能力提升
④支持更低的硬件
ART缺点
①更大的存储空间占用。可能添加10%-20%
②更长的应用安装时间
总的来说ART就是“空间换时间”















 2542
2542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









