






楔子:这是一种缺啥补啥的叙述方式.........电脑用的是windows........
首先,搜到了相关静态页面的爬虫代码,第一步import:
import requests
from bs4 import BeautifulSoup输入后提示无法从源解析导入'requests' / 'bs4':

那么就要安装requests和bs4,
pip install requests
pip install bs4发现报错:

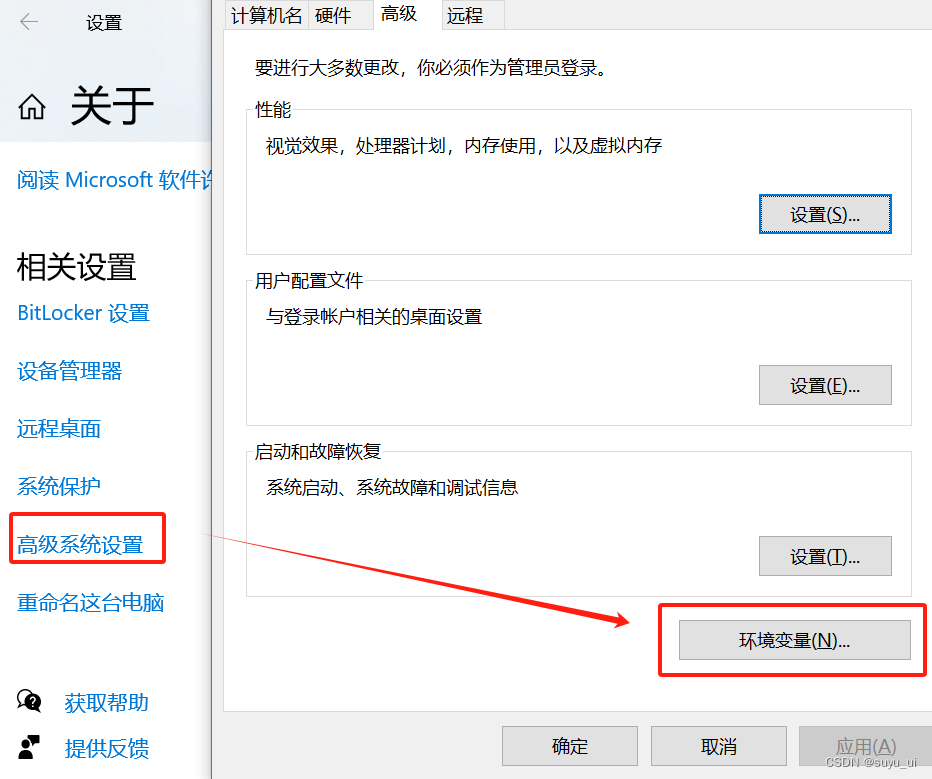
百度了一下,是需要添加环境:
把pip所在文件夹的路径,一般为: '...\AppData\Local\Programs\Python\Python39\Scripts'(不是的话也可以自己在文件夹搜索pip/python找找看)
添加到: 控制面板->系统和安全->系统->高级系统设置->环境变量->新建->输入路径(安装python的时候有个pip的选项要选的啊....)
之后再次在终端安装 pip install requests / bs4,跳出选项:
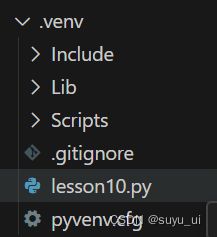
你可能已将 Python 包安装到全局环境中,这可能会导致包版本之间发生冲突。是否要创建包含这些包的虚拟环境来隔离依赖项?
选择是后,在原文件下自动生成了.venv文件夹,如图:
好了,开始爬起来:
import requests
from bs4 import BeautifulSoup
url = '要访问/爬页面的url'
headers = { 'user_agents': '如图所示拿到user_agents' }
strHtml = requests.get(url, headers = headers) # Get方式获取网页数据
soup = BeautifulSoup(strHtml.text, 'lxml')
info = soup.select('如下文所示拿到筛选所需路径') # 筛选数据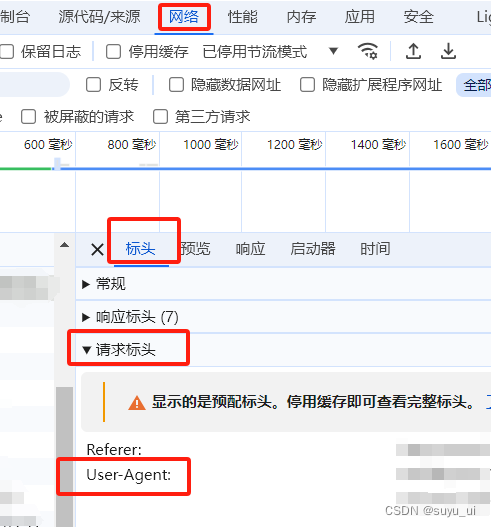
info = soup.select('') 这里需要在元素里找到目标元素的位置,右击->轻触复制->复制selector
复制这里有不同的选择,本篇选择的是复制selector(目前浅看下来,也有用到Xpath的,但貌似BeautifulSoup()这里会有不同,还不确定,后续确定了再修改)
for item in info:
input = item.get_text()题外话:这里input拿到后打印,发现有一个数据没获取到,具体是:
<tr>
<td>内容</td>
<td>
<a>要爬的文本内容</a>
<a>要爬的文本内容</a>
<a>要爬的文本内容</a>
<a>要爬的文本内容</a>
</td>
</tr>这里a标签里的文本没有获取到
后面尝试了在info = soup.select(' ') 里写入具体到这个a标签的selector,爬出来是空
索性直接info = soup.selet('a') ,得到了这个页面里除了这个td里的a标签之外的其他全部a标签文本(排除方法问题)
又在 控制台-网络-响应 查看了很久,估摸着这部分应该是动态加载的,解决方案有二:
一、直接爬它相关的请求(数据太多没耐心了没找到)
二、使用支持JavaScript动态渲染的库,后面继续研究~
---------------------------------------------------------------------------------------------------------------------------------
求助大佬,说是可以直接拿全部的数据,在script里面找到这个a标签对应的数据,然后正则匹配出来,具体代码如下:
import re
strHtml = requests.get(url, headers = headers) # url和headers请参照上文
pattern = r'' # ''里是筛选a标签数据的正则
match = re.search(pattern, strHtml.text) # re 匹配 JavaScript 代码中 a标签文本对应的变量的赋值语句
if match:
data = match.group(1) # data接收
else:
print("can not found in JavaScript code.")试了试真的取到了(引发疑问:为啥这样又能拿到呢?不都是静态方法吗?还是说之前selector的时候只取html部分的数据?这个是不是就是上述解决方法一?)
方法二还是想试试,等待研究~
最后想说,这个不是只针对a标签哈,只是我自己爬不出来的这部分刚好是a标签下的文本















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









