






今天遇到一个问题:正则表达式匹配错误,代码如下
import requests
import re
source = requests.get('https://www.zysj.com.cn/lilunshuji/index__2.html').content.decode()
list1=re.findall('<div id="list-content">.*?</div>',source,re.S)
indexlist=re.findall('title="《(.*?)》',list1[0],re.S)
print(list1[0])
print(re.findall('href=".*?" title="《百病自测》"',list1[0],re.S))其中前面几行获取了list1[0],值是这样:
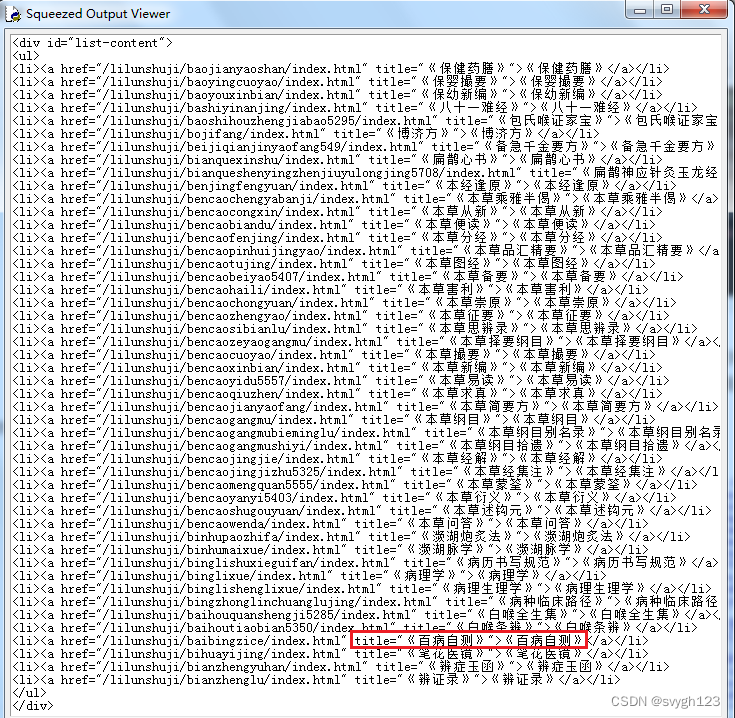
然而,我本意是匹配书名为百病自测对应的url,按理来说我使用的是非贪婪搜素,得到的结果应该是href="/lilunshuji/baibingzice/index.html" title="《百病自测》",为什么出来的结果会下面是这样?

很明显,把所有的内容都打印出来了。
为什么?
因为正则表达式获取的内容都是精确的,没有边界,导致获取的结果很广泛。
修改后
print(re.findall(r'<a\s+[^>]*title="《百病自测》"[^>]*>',list1[0],re.S))解释一下这个表达式:
-
r'... ': 前面的r表示这是一个原始字符串(raw string),它告诉Python解释器里面的反斜杠\不应该被解释为转义字符,而是当作字面意义的字符处理,这对于正则表达式非常有用,因为它里面经常包含很多反斜杠。 -
<a\s+: 这部分匹配开始的<a标签。\s+表示匹配一个或多个空白字符(包括空格、制表符、换行符等)。因此,<a\s+整体上匹配<a后面跟着一个或多个空格的情况,这是为了适应HTML中属性前可能有的不同数量的空格。 -
[^>]*: 这是一个否定字符集,表示匹配除>之外的任意字符,而且*表示前面的模式可以重复零次或多次。这部分的作用是在找到title属性之前跳过所有其他可能存在的属性(假设它们不会包含>字符)。 -
title="《百病自测》": 精确匹配包含文本title="《百病自测》"的部分,即title属性值为《百病自测》。 -
[^>]*>: 同样,这部分再次使用了[^>]*来匹配title="《百病自测》"之后直到遇到>符号之间的任何字符。这意味着它会忽略掉title属性之后直至a标签结束的所有其他属性和空白。
总结:整个正则表达式<a\s+[^>]*title="《百病自测》"[^>]*>用来查找形如<a ... title="《百病自测》" ... >的a标签,其中省略号...代表可以有任意数量的其他属性或者空白,只要title属性值为《百病自测》即可。
问题来源:
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











