







 本文详细介绍了在Linux系统上安装JDK,卸载自带版本,配置环境变量,关闭防火墙,设置静态IP,克隆虚拟机,修改主机名以及配置SSH无密码登录的过程。接着,文章讲述了Hadoop的部署,包括解压安装包,配置环境变量,并进行了初步的验证。然而,Hadoop集群的后续配置并未详述。
本文详细介绍了在Linux系统上安装JDK,卸载自带版本,配置环境变量,关闭防火墙,设置静态IP,克隆虚拟机,修改主机名以及配置SSH无密码登录的过程。接着,文章讲述了Hadoop的部署,包括解压安装包,配置环境变量,并进行了初步的验证。然而,Hadoop集群的后续配置并未详述。
组件安装
安装系列组件
@[TOC]组件安装
前言
安装组件需要细心、耐心;
一、安装JDK
1、查询本机是否安装JDK:
jdk -version
如果有提示有输出,表示系统安装有JDK,这个是系统自带的;
2、卸载系统自带的jdk:
1)查询系统自带的jdk 安装包
rpm -qa|grep jdk
2)执行卸载:
yum -y remove java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
3)查询jdk是否卸载成功:
jdk -version
执行上述命令后,没有jdk的版本信息,表示卸载成功;
4)重新安装jdk:以jdk-8u40-linux-x64.tar.gz;
将jdk-8u40-linux-x64.tar.gz 拷贝到/usr/local/src/
执行解压命令:
sudo tar -zxvf jdk-8u40-linux-x64.tar.gz
得到 jdk1.8.0_40文件夹;
5)配置jdk的环境变量:
sudo gedit /etc/profile
上述目录在home下;
输入:
export JAVA_HOME=/usr/local/src/jdk/jdk1.8.0_40 #这个地方按照自己的目录修改
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
重新加载环境变量:
source /etc/profile
java -version
注意下:以上操作需要root权限;
二、关闭防火墙
1.关闭系统防火墙
代码如下(示例):
输入命令“systemctl disable firewalld.service”命令,即可永久关闭防火墙。
2.关闭内核防火墙
代码如下(示例):
/etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled **#修改成这个**
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
3.配置静态IP
sudo gedit /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #修改项
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="2293bf30-807b-448d-9918-76841b997fe5"
DEVICE="ens33"
ONBOOT="yes" #修改项,设置网卡启动方式为 开机启动 并且可以通过系统服务管理器 systemctl 控制网卡
IPADDR="192.168.*.128" # 设置的静态IP地址
NETMASK="255.255.255.0" # 子网掩码
GATEWAY="192.168.*.2" # 网关地址
DNS1="0.0.0.0" # DNS服务器(此设置没有用到,所以我的里面没有添加)
service network restart
ping www.baidu.com #测试静态IP是否修改正确
4. 克隆虚拟机
选择需要克隆的虚拟机-》鼠标右键->管理->克隆:
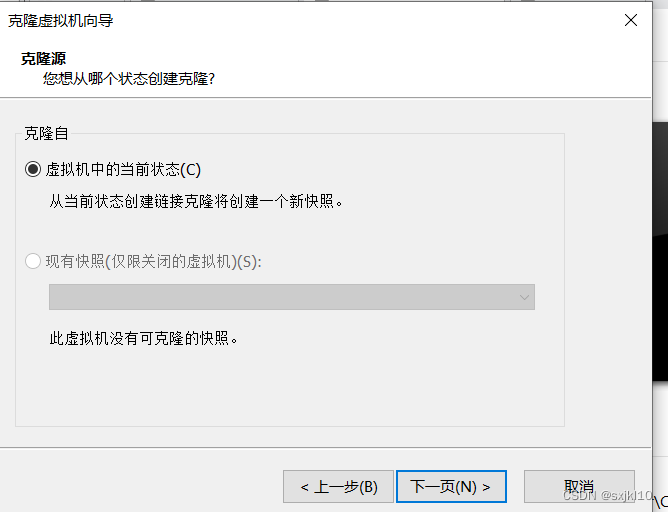
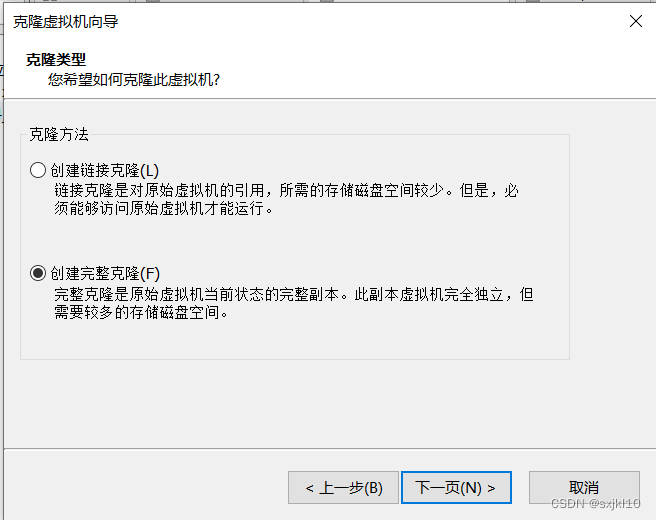
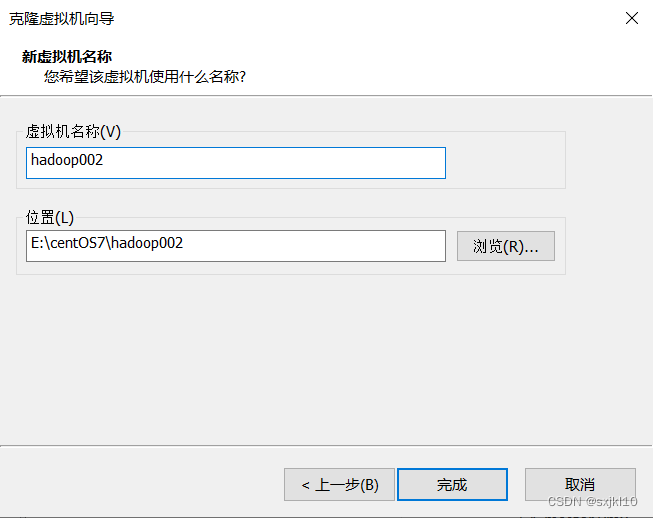
5.修改主机名和克隆机IP
hostnamectl set-hostname master
reboot //修改主机名后需重启虚拟机
hostnamectl set-hostname hadoop001
reboot //修改主机名后需重启虚拟机
hostnamectl set-hostname hadoop002
reboot //修改主机名后需重启虚拟机
配置hosts和ssh
所有的虚拟机都需要下述操作:
IP地址按照自己的IP进行修改。
sudo gedit /etc/hosts
192.168.*.130 master
192.168.*.131 hadoop001
192.168.*.132 hadoop002
1、生成ssh秘钥
ssh-keygen -t rsa
执行
ssh-copy-id master
ssh-copy-id hadoop001
ssh-copy-id hadoop002
验证:
ssh master 能切换到master主机,通过ifconfig 判断当前终端坐在的虚拟机;
注意不要添加本机。
6、hadoop集群配置
建立文件夹
sudo mkdir -p /export/data
sudo mkdir -p /export/servers
sudo mkdir -p /export/software
7、hadoop部署
每个虚拟机,将hadoop-2.6.1.tar.gz 拷贝到 /export/software。并解压到:/export/servers/:
sudo tar -zxvf hadoop-2.6.1.tar.gz -C /export/servers/
配置环境变量
sudo gedit /etc/profile
#tip:在文件末尾追加
export HADOOP_HOME=/export/servers/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
环境变量更新
source /etc/profile
验证
hadoop version
8、后面的不懂
请参照:
Hadoop搭建测试
:这篇文章很好,我的好多步骤都有借鉴,非常感谢!
总结
1、非常感谢https://blog.csdn.net/tang5615/article/details/120382513这位博主的无私奉献;
2、以上过程全部是实操结果,如有问题,欢迎交流。
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









