







之前一直要写的遍历导出表,一直没写,最近回去复习了一下PE结构关于IAT和EAT的内容,写了个遍历导出表的程序,也算是结了之前文章里说的话吧。
源码:
// ExportTable.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include<windows.h>
using namespace std;
DWORD RVA_RAW(DWORD RVA, unsigned char * Base)
{
//定位DOS头;
PIMAGE_DOS_HEADER DosHeader = (PIMAGE_DOS_HEADER)Base;
//定位NT头;
PIMAGE_NT_HEADERS Nt_Header = (PIMAGE_NT_HEADERS)(Base + DosHeader->e_lfanew);
//获取节区数目
WORD SectionNum = Nt_Header->FileHeader.NumberOfSections;
//获取节区头的地址
PIMAGE_SECTION_HEADER SectionHeader = (PIMAGE_SECTION_HEADER)(Base+ DosHeader->e_lfanew+ 0x18 + Nt_Header->FileHeader.SizeOfOptionalHeader);
//定位目标RVA所在节区
DWORD RAW = 0;
for (int i = 0; i < SectionNum; i++)
{
DWORD SectionStart = SectionHeader[i].VirtualAddress;
DWORD SectionEnd = SectionStart+SectionHeader[i].Misc.VirtualSize;
if (RVA >= SectionStart && RVA <= SectionEnd)
{
RAW = RVA - SectionStart + SectionHeader[i].PointerToRawData;
break;
}
}
return RAW;
}
int main()
{
//HMODULE hFile = LoadLibraryA("user32.dll");
HANDLE hFile = CreateFileA(
"你的目标DLL的绝对路径(注意要打双斜杠)",
GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE | FILE_SHARE_DELETE,
NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL
, NULL
);
if (hFile == INVALID_HANDLE_VALUE)
{
int a=GetLastError();
cout << "文件打开失败" << "失败原因"<<a<<endl;
return 1;
}
DWORD FileSize = GetFileSize(hFile, NULL);
LPDWORD SizeToRead = 0;
unsigned char * pBuf = new unsigned char[FileSize];
ZeroMemory(pBuf,FileSize);
int i = ReadFile(hFile, pBuf, FileSize, SizeToRead, NULL);
if (i == 0)
{
cout << "文件读取失败" << endl;
}
cout << "文件基址是" << pBuf << endl;
//定位DOS头;
PIMAGE_DOS_HEADER DosHeader = (PIMAGE_DOS_HEADER)pBuf;
//定位NT头;
PIMAGE_NT_HEADERS Nt_Header = (PIMAGE_NT_HEADERS)(pBuf + DosHeader->e_lfanew);
//定位数据目录表
PIMAGE_OPTIONAL_HEADER32 OptionHeader = &(Nt_Header->OptionalHeader);
//定位导出表结构,获取导出表的RAW
DWORD ExportRAW = RVA_RAW(OptionHeader->DataDirectory[0].VirtualAddress, pBuf);
//定位导出表数据结构
PIMAGE_EXPORT_DIRECTORY ExportTable = (PIMAGE_EXPORT_DIRECTORY)(ExportRAW + pBuf);
//获取目标DLL的名称
char * DllName =(char *)(RVA_RAW(ExportTable->Name,pBuf)+pBuf);
printf("目标DLL的名称是%s\n",DllName);
//获取导出函数的起始序号Base
WORD Base = ExportTable->Base;
//获取导出函数的总数
DWORD NumOfFunc = ExportTable->NumberOfFunctions;
//获取以名字导出的函数的总数
DWORD NumOfName = ExportTable->NumberOfNames;
//获取导出函数地址表的RVA,并且将至转换成为RAW
PDWORD AddressOfFun =(PDWORD)(RVA_RAW(ExportTable->AddressOfFunctions, pBuf)+pBuf);
//获取函数名称地址表
PDWORD AddressOfName =(PDWORD)(RVA_RAW(ExportTable->AddressOfNames, pBuf)+pBuf);
//获取函数序号地址表
PWORD AddressOfNameOrdinals =(PWORD )(RVA_RAW(ExportTable->AddressOfNameOrdinals, pBuf)+pBuf);
//接下来开始遍历导出表
for (int i = 0; i < NumOfFunc; i++)
{
if (AddressOfFun[i] == 0)
continue;
int j = 0;
for (;j < NumOfName; j++)
{
if (AddressOfNameOrdinals[j] == i)
{
char * FuncName = (char *)((RVA_RAW(AddressOfName[j], pBuf)) + pBuf);
printf("函数序号为%x 函数地址为%x 函数名称为%s \n ",Base+j,AddressOfFun[i],FuncName);
break;
}
}
if (j == NumOfName)
{
printf("函数序号为%x 函数地址为%x 函数名称为NULL\n", Base +i, AddressOfFun[i]);
}
}
}
遍历导出表其实是一个比较细致的活(对于我自己来说),因为中间涉及到较多的RVA到RAW的数据转换的问题,而且关键是哪些数据需要转换,哪些不需要转换,说实话整的有点烦.
下边是写的过程中的一点总结
1:之前也看过网上别人写的代码中有使用CreateFileA也有使用LoadLibrary的,那么使用这两者便利的时候有什么区别呢?
本质上是没有什么区别的,所谓的区别体现在代码中就是需不需要进行地址转换的问题,在使用Load Library的时候,不需要进行RVA到RAW的转换,因为使用这个二API相当于将这个DLL加载到内存当中.而是用CreateFile打开文件之后,还需要将文件读取到内存当中,但是这个时候文件是保持它自身在磁盘里的状态的,也就是说这个时候的文件是没有展开的,需要进行RVA到RAW的地址转化的.
2:究竟哪些地址需要转换?
这个问题其实比较好理解,只要对照着导出表的数据结构进行查看就可以解决,还有一个我自己想的小方法:当你使用指向RVA的指针进行寻址的时候就需要转换.
比如说:函数地址表,也就是DWORD AddressOfFunction这个字段,这个字段里边存储着指向函数地址表的地址的RVA,如果我们要去找到对应函数的地址,就要靠这个RVA地址去索引,但是索引之前我们需要对他它进行地址转换.
3:在调试过程中的小插曲
在这次遍历导出表的编写过程中,发现了一个之前没有发现的问题,那就是
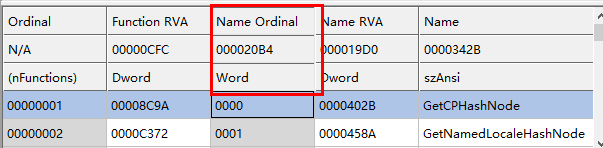
DWORD AddressOfNameOrdinals 这个字段引起的灵异事件.
下边就把我的调试过程简单的说一下:
可以看到上边的源码中,对于这个字段的定义,我定义的是PWORD 类型的
但是在数据结构里边我们可以看到这个字段是DWORD类型的,现在看一下二者的调试状况:
//获取函数序号地址表
PWORD AddressOfNameOrdinals =(PWORD )(RVA_RAW(ExportTable->AddressOfNameOrdinals, pBuf)+pBuf);

当定义为PDWORD的时候:
输出结果:
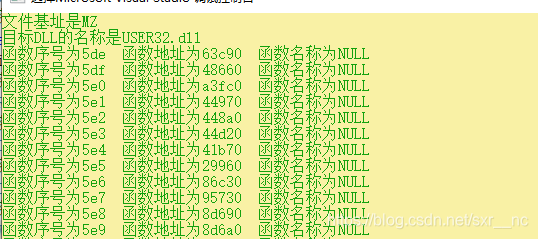
当定义为PWORD的时候,输出结果:
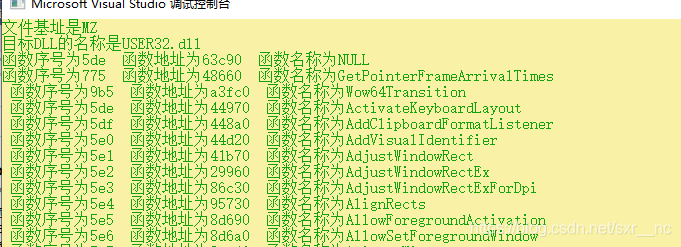
调试:
当时PDWORD的时候,我们执行获取名称序号表的操作之后,获取到的地址及该地址处的内容如下:
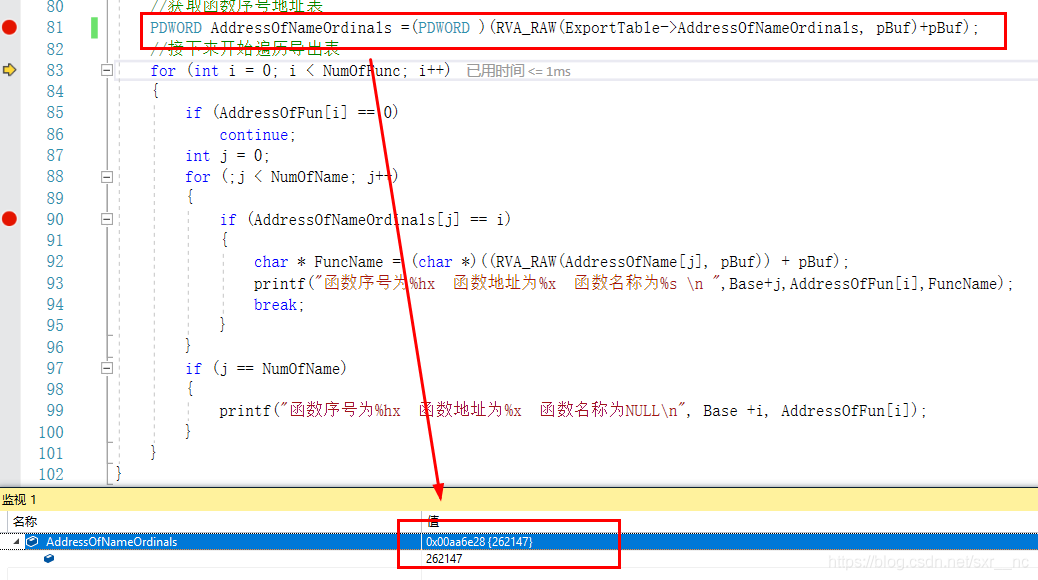
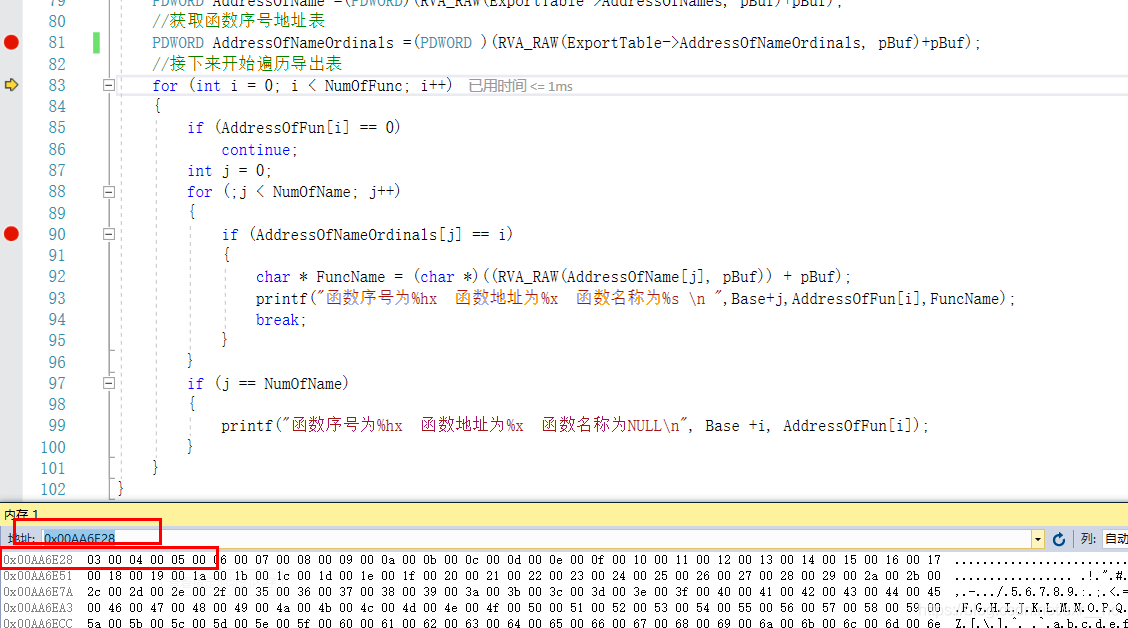
可以看到在该地址处存储的值为262147(跳转到内存地址过去,读取到的数据时4003),其实就是十进制和十六进制的转换

而问题是PDWORD时4字节的指针类型,当我们指针加1的时候其实是将指针加了4,这样的话,对应的内存处的数据变化为:

这样明显匹配不到,因此将指针类型转换为PWORD类型的时候,对应的匹配就变成如下图所示:

这个问题,之前没注意到现在注意到也为时不晚,后来用CFF软件查看了DLL的导出函数表的数据结构发现对应得该字段时WORD类型的,大概也就将这个结果作为这个事情的合理的解释吧















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









