






一、OLAP 概念
OLAP (Online analytical processing) 联机分析处理是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有 FASMI (Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性 (Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息。
OLTP (Online transaction processing) 在线/联机事务处理,典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查。
OLAP 与 OLTP 对比:
| OLTP | OLAP | |
|---|---|---|
| 操作对象 | 数据库 | 数据仓库 |
| 数据量 | 数据量较小 | 数据量大 |
| 数据时效 | 当前数据 | 当前及历史数据 |
| 数据操作 | 支持 DML、DDL | 一般不支持更新和删除 |
| 操作粒度 | 记录级 | 涉及多表 |
| 事务性 | 强事务 | 一般不支持事务,或者支持性不好 |
| 性能要求 | 高吞吐、低延时 | 性能要求相对较低 |
| 操作目的 | 查询或改变现状 | 分析规律、预测趋势 |
| 业务类型 | 账户查询、转账等 | 统计报告、多维分析 |
一般来说,单次 OLTP 处理的数据量比较小,所涉及的表非常有限,一般仅一两张表。而 OLAP 是为了从大量的数据中找出某种规律性的东西,经常用到 count()、sum() 和 avg() 等聚合方法,用于了解现状并为将来的计划/决策提供数据支撑,所以对多张表的数据进行连接汇总非常普遍。
二、常见的 OLAP 引擎
常见的 OLAP 引擎有 Hive、Presto、Impala、Kylin、Druid、ClickHouse、Doris、StarRocks 等。
1. Hive
参考链接:
- Apache Hive
- Home - Apache Hive - Apache Software Foundation
- Design - Apache Hive - Apache Software Foundation
- AdminManual Metastore Administration - Apache Hive - Apache Software Foundation
Apache Hive 是可实现大规模分析的分布式容错数据仓库系统。该数据仓库集中存储信息,用户可以轻松对此类信息进行分析,从而做出明智的数据驱动决策。Hive 让用户可以利用 SQL 读取、写入和管理 PB 级数据。
Hive 建立在 Apache Hadoop 基础之上,后者是一种开源框架,可被用于高效存储与处理大型数据集。因此,Hive 与 Hadoop 紧密集成,其设计可快速对 PB 级数据进行操作。Hive 的与众不同之处在于它可以利用 Apache Tez、Spark、MapReduce 通过类似于 SQL 的界面查询大型数据集。
1.1 架构图

三种启动模式
- Embedded Metastore
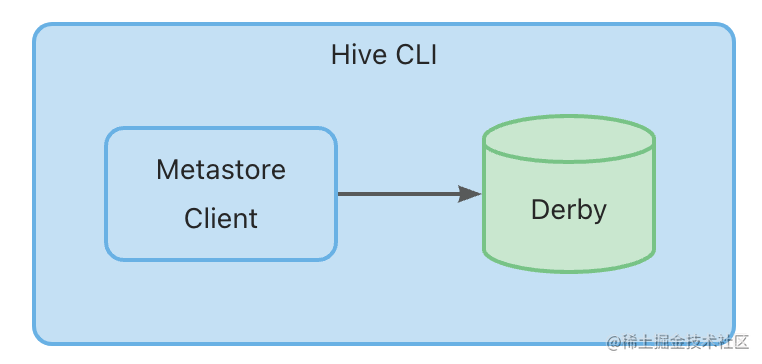
- Local Metastore
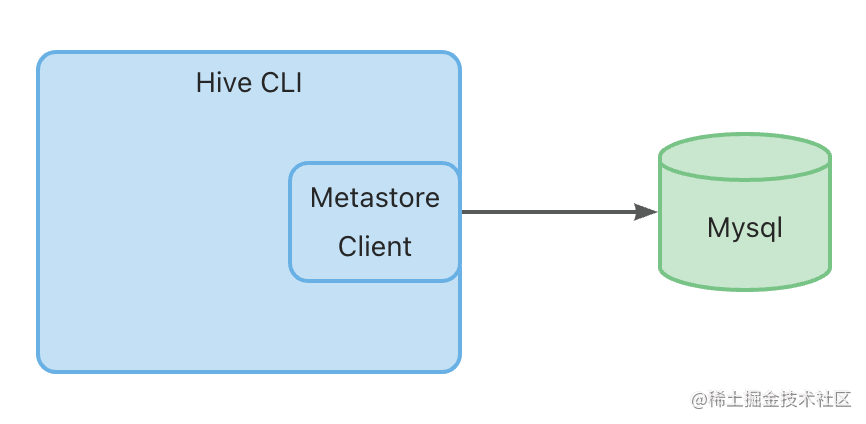
- Remote Metastore
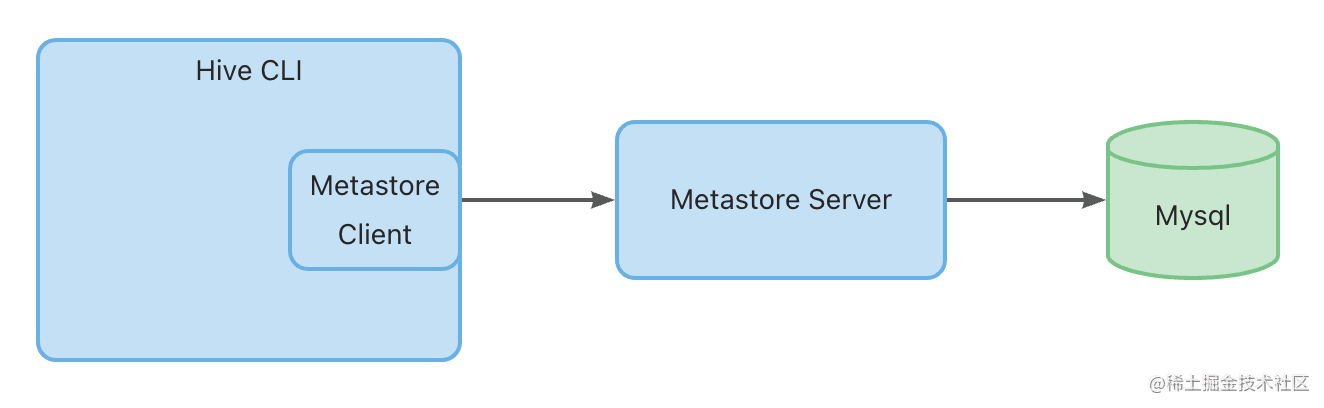
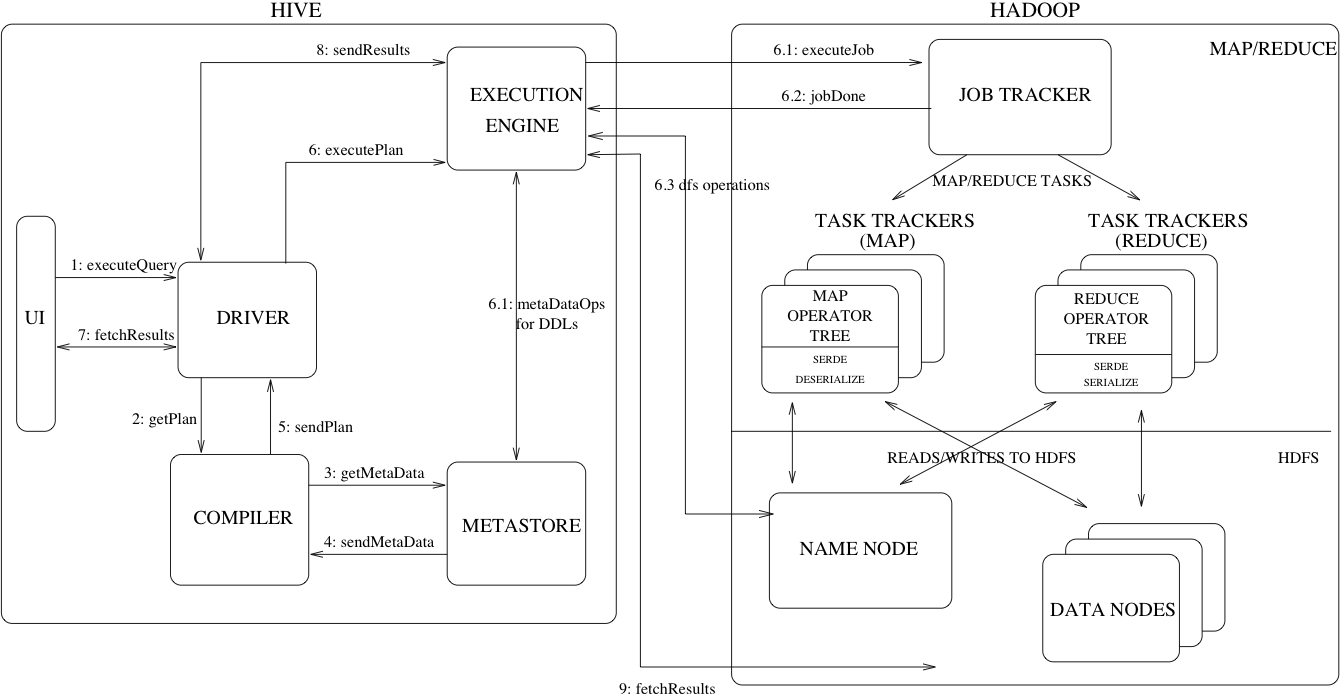
工作原理
1.2 优缺点
- 优点:
- 高可靠、高容错: HiveServer 采用集群模式(zk)、双 MetaStore 等。
- 类SQL: 类似SQL语法,内置大量函数。
- 可扩展: 自定义存储格式,自定义函数。
- 多接口: Beeline、JDBC、ODBC、Python、Thrift。
- 缺点:
- 延迟较高: 默认 MR 为执行引擎,MR 延迟较高。
- 不支持物化视图: Hive 支持普通视图,不支持物化视图。Hive 不能在视图上更新、插入、删除数据。
- 不适用 OLTP: 暂不支持列级别的数据添加、更新、删除操作。
2. Presto
参考链接:
Presto 是 Facebook 推出的一个开源的分布式 SQL 查询引擎,数据规模可以支持 GB 到 PB 级,主要应用于处理秒级查询的场景。Presto 的设计和编写完全是为了解决像 Facebook 这样规模的商业数据仓库的交互式分析和处理速度的问题。
Presto 是一个分布式的采用 MPP 架构的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。
2.1 架构图
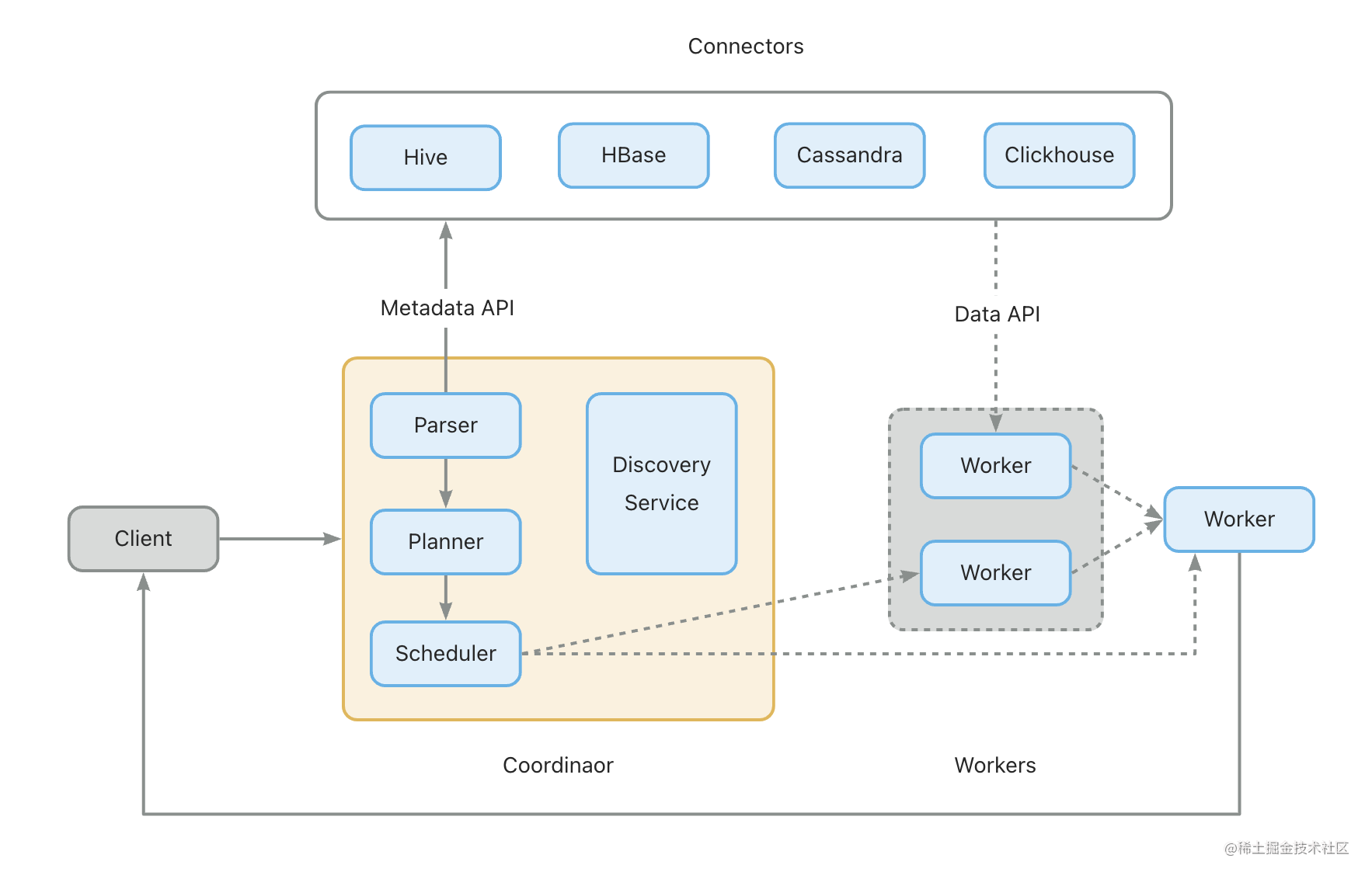
- Coordinator: 是 presto 集群的 master 节点。负责解析 SQL 语句,生成执行计划,分发执行任务给 Worker 节点执行
- Worker: 是执行任务的节点,负责实际查询任务的计算和读写,返回计算结果到 Client
- Discovery Service: 是将 Coordinator 和 Worker 结合在一起服务。Worker 节点启动后向 Discovery Service 服务注册,Coordinator 通过 Discovery Service 获取注册的 Worker 节点
- Connector: presto 以插件形式对数据存储层进行了抽象,即 Connector。可通过 Connector 连接多种数据源,查询元数据和读取数据
高可用架构
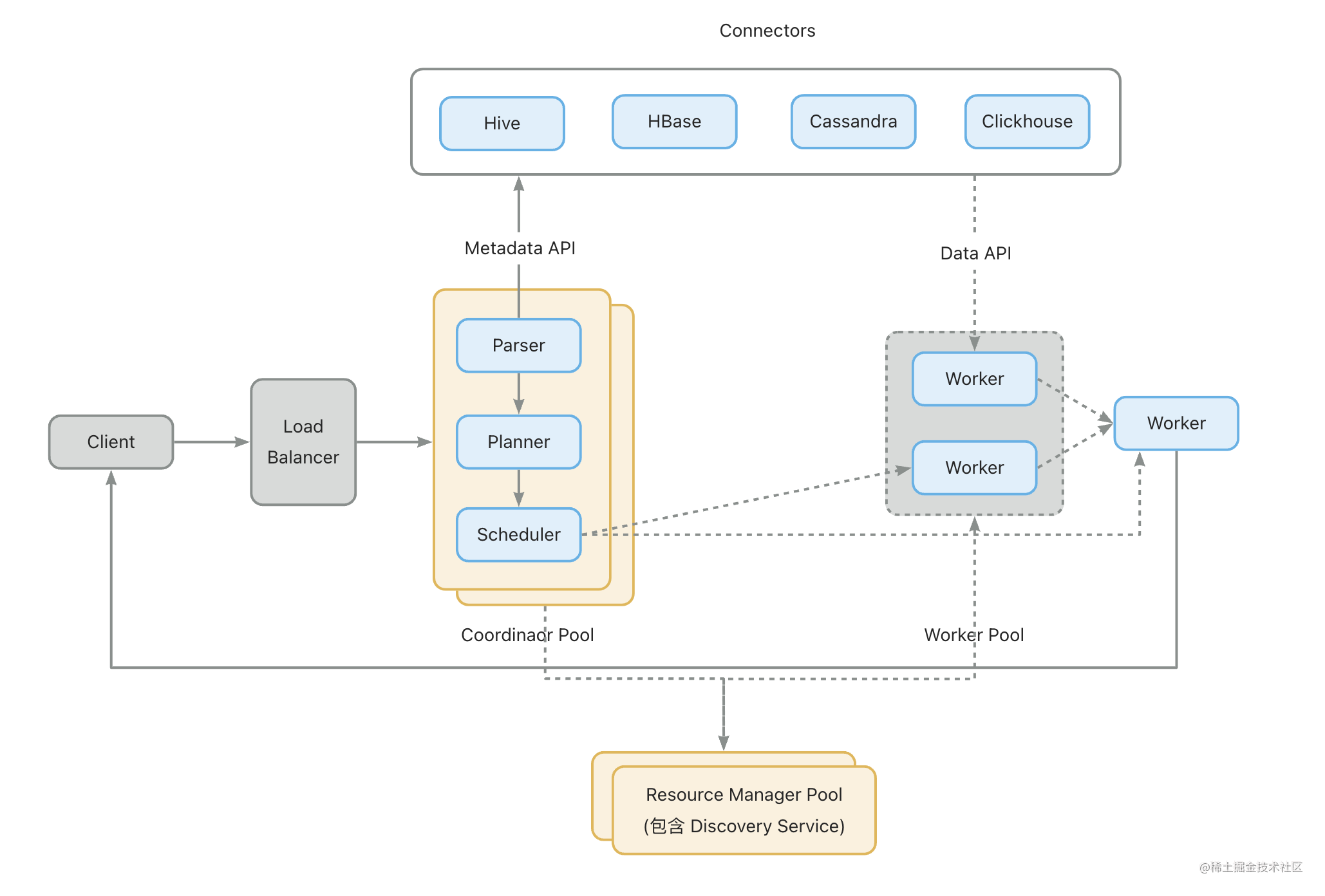
Resource Manager: Resource Manager 是聚合来自所有 Coordinator 和 Worker 的数据并构建集群全局视图的服务,使用 disaggregated coordinator 的 Presto 必须安装 Resource Manager,Resource Manager 是多主策略。Coordinator 和 Worker 通过 thrift API 来和 Resource Manager 通信。
2.2 优缺点
- 优点:
- 基于内存运算,减少没必要的硬盘IO,计算速度快
- 都能够处理 PB 级别的海量数据分析(虽然能够处理 PB 级别的海量数据分析,但不是代表 Presto 把 PB 级别都放在内存中计算的。而是根据场景,如 count,avg 等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高)
- 能够连接多个数据源,跨数据源关联查询
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统,部署简单
- 缺点:
- 不适合多个大表的 join 操作,因为 Presto 是基于内存的,太多数据内存放不下的
- 如果其中一个 Presto 工作节点出现故障,大多数情况下正在进行的查询将中止并需要重新启动
3. Impala
参考链接:
- impala.apache.org
- https://impala.apache.org/docs/build/impala-4.2.pdf
Impala 是一个架构于 hadoop 之上的全新、开源 MPP 查询引擎,提供低延迟、高并发的以读为主的查询。通过Impala,你可以使用 SELECT、JOIN 和聚集函数等语法,实时地查询储存在 HDFS 或 HBase 上的数据。
3.1 架构图
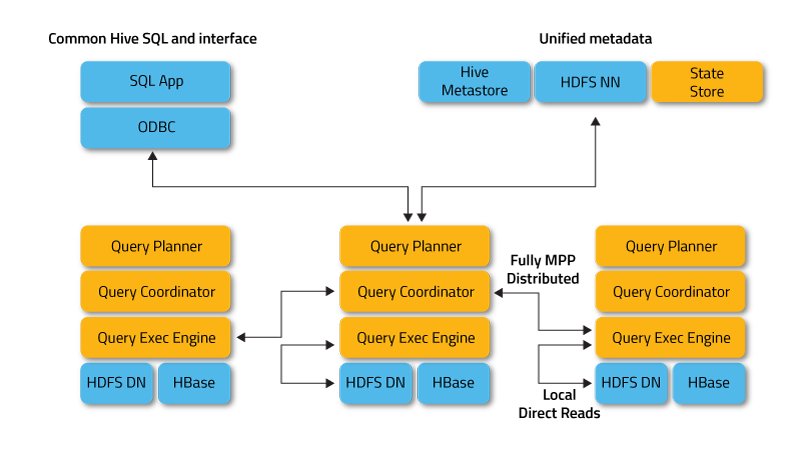
- Impala Daemon: impala 的核心组件,它负责读写数据、接收客户端命令、解析 SQL等,可以部署在 hdfs dn 节点上,使用 Local Direct Read 的方式加速读取数据
- Impala Statestore: Impala Statestore 负责检查集群所有组件的状态,提高集群可用性
- Impala Catalog Service: 元数据服务,通常会和 Statestore 部署在一个机器上,hive 表结构、分区变更,需要手动触发更新元数据
3.2 优缺点
- 优点:
- 基于内存运算,减少没必要的硬盘IO,计算速度快
- 与 hive sql 的兼容性比 presto 要好一些
- 缺点:
- 低版本不支持 orc 格式,不支持某些 hive 的字段类型
- 不支持 namenode federation
- 安装部署成本高,官方给的安装方式是源码编译
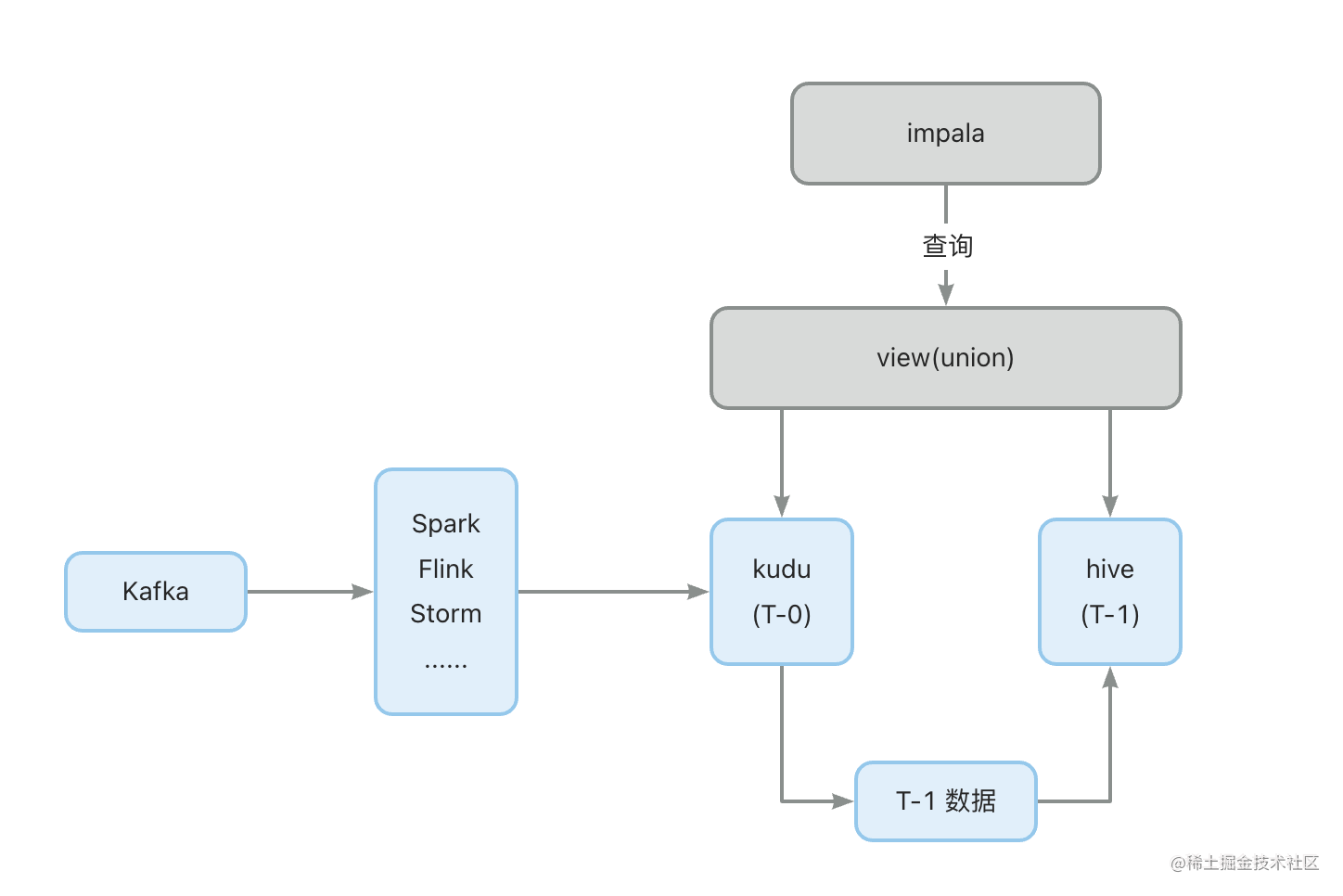
使用场景
Impala + hive + kudu 实时存储计算
4. Kylin
参考链接:
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的 Hive 表。Kylin的核心思想是预计算,理论基础是:以空间换时间。即将多维分析可能用到的度量进行预计算,将计算好的结果保存成 Cube 并存储到 HBase 中,供查询时直接访问。把高复杂度的聚合运算,多表连接等操作转换成对预计算结果的查询。
4.1 架构图
kylin4.x
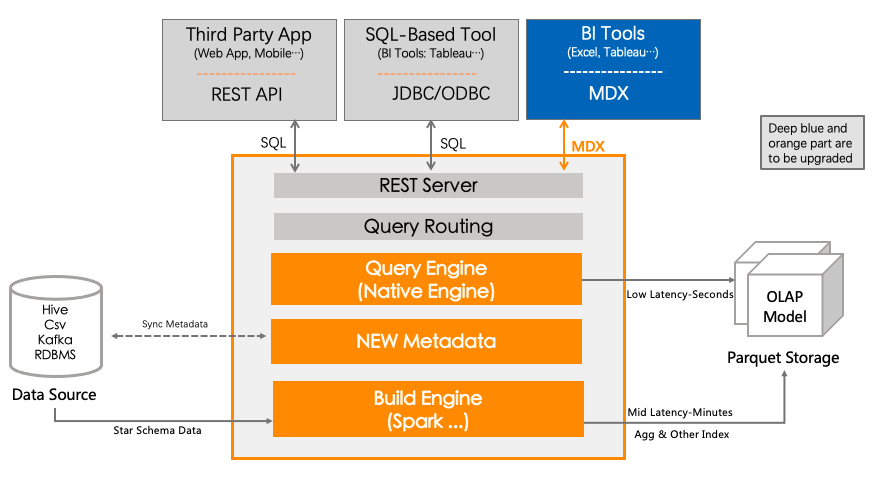
4.2 优缺点
- 优点:
- 亚秒级查询响应
- 支持百亿、千亿甚至万亿级别交互式分析
- 无缝与 BI 工具集成
- 支持增量刷新
- 缺点:
- 由于 Kylin 是一个分析引擎,只读,不支持 insert, update, delete 等 SQL 操作,用户修改数据的话需要重新批量导入(构建)
- 需要预先建立模型后加载数据到 Cube 后才可进行查询,空间换时间,可能会出现维度爆炸的问题
- 使用 Kylin 的建模人员需要了解一定的数据仓库知识
5. Druid
参考链接:
Apache Druid 是一个分布式的、支持实时多维 OLAP 分析、列式存储的数据处理系统,支持高速的实时数据读取处理、支持实时灵活的多维数据分析查询。在 Druid 数十台分布式集群中支持每秒百万条数据写入,对亿万条数据读取做到亚秒到秒级响应。此外,Druid 支持根据时间戳对数据进行预聚合摄入和聚合分析,在时序数据处理分析场景中也可以使用 Druid。
5.1 架构图

- Coordinator: 协调集群工作,保障数据可用性
- Overlord: 控制数据摄取工作负载的分配
- Broker: 接收来自客户端的查询请求
- Router: 可选的,把请求路由到 Brokers、Coordinators、Overlords
- Historical: 存储数据
- MiddleManager: 摄取数据
5.2 优缺点
- 优点:
- 相较于前面几个,对于实时数据的支持比较好
- 为分析而设计: 为 OLAP 工作流的探索性分析而构建,它支持各种 filter、aggregator 和查询类型
- 交互式查询: 低延迟数据摄取架构允许事件在它们创建后毫秒内查询
- 高可用: 你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失
- 可伸缩: 每天处理数十亿事件和TB级数据
- 缺点:
- 对 sql 支持不太好,经常有 bug
- 不支持更新操作,数据不可更改
- 不支持表关联
6. ClickHouse
参考链接:
ClickHouse是一款由俄罗斯 Yandex 公司开发的用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
6.1 介绍
clickhouse 有多种表引擎,适用于不同的场景。建表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine
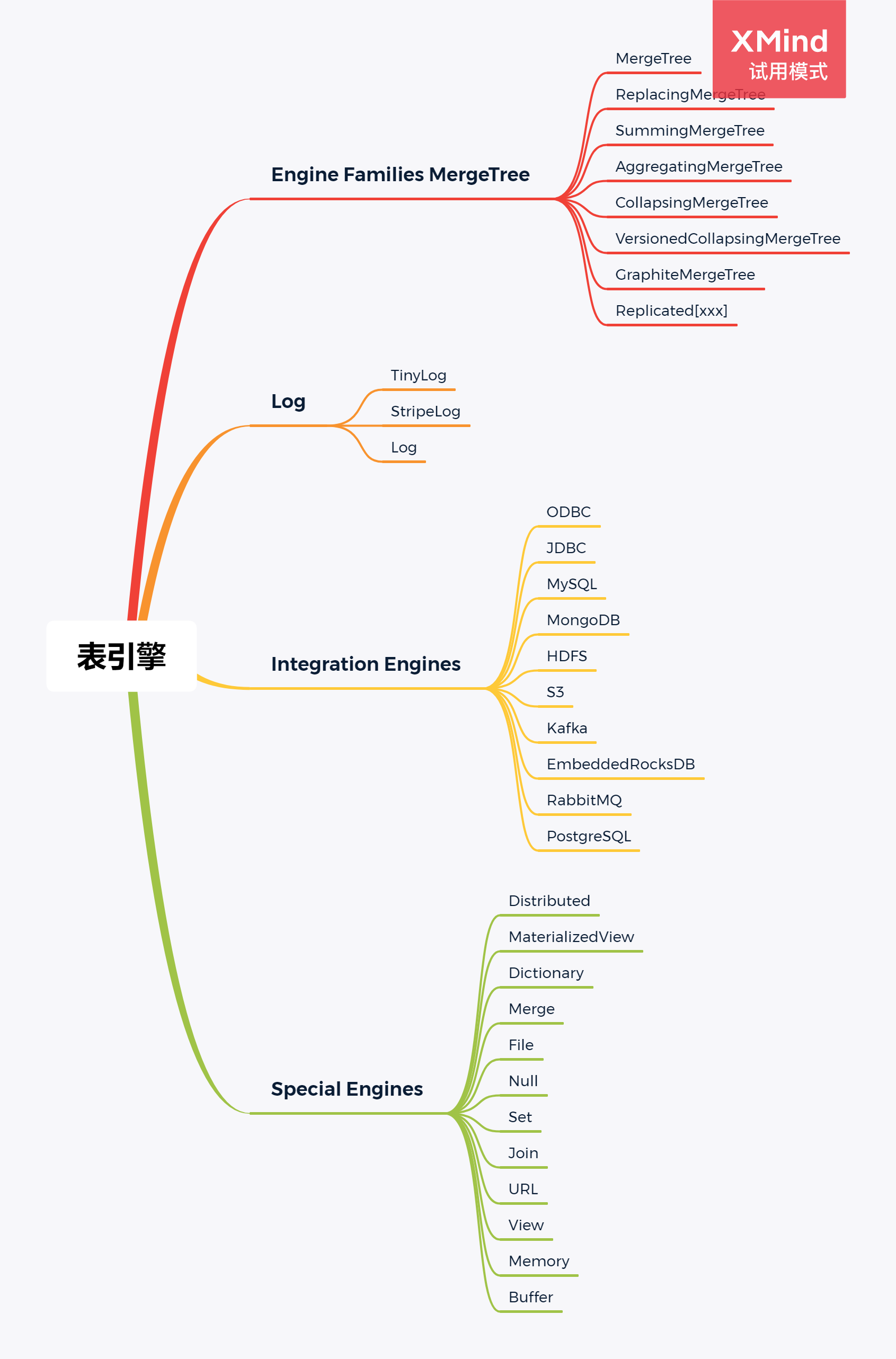
ReplicatedMergeTree 表查询流程

6.2 优缺点
- 优点:
- 支持实时和离线数据,sql 支持好
- 支持物化视图
- 真正的列式数据库管理系统
- 数据压缩
- 数据存储在磁盘,数据存储在磁盘可以降低成本,clickhouse 即使在普通磁盘上,也可以快速的查询出结果
- 多核心并行处理
- 多服务器分布式处理,分布式表,可以利用多个服务器,并行执行查询
- 支持 SQL
- 向量引擎
- 索引
- 适合在线查询
- 支持近似计算
- 自适应 join
- 支持数据副本机制,可以设置数据存储的备份,提高可用性
- 角色控制
- 缺点:
- 没有完整的事务支持
- 不能高频、低延迟的修改或删除数据
- 不适合单行点查询
- 大表 join 性能相对较差
- 扩缩容成本高
7. Doris
参考链接:
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业数百家企业的 400 余位贡献者,并且每月活跃贡献者人数也超过 100 位。 2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。
7.1 架构图
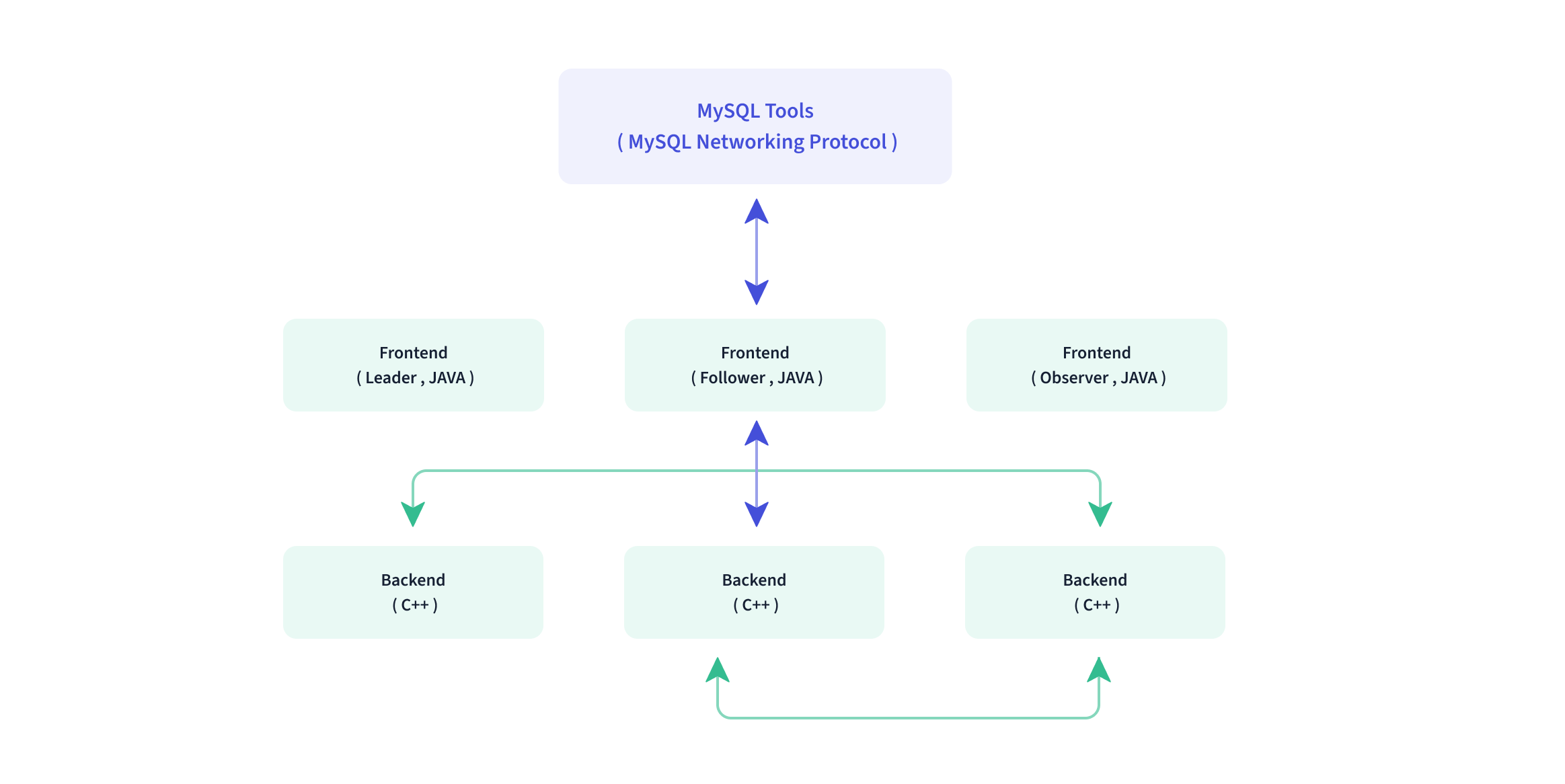
- Frontend(FE): 主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作
- Leader: 从 FE 中选取出来的,负责读写元数据
- Follower: 只能读取元数据,会把写请求路由到 leader,当 leader 不可用,会参与选举新的 Leader
- Observer: 只能读取元数据,主要用来提高集群不并发,不参与 Leader 选举
- Backend(BE): 主要负责数据存储、查询计划的执行
查询流程

7.2 优缺点
- 优点:
- 相较于 clickhouse 运维简单,易于上手
- 大表 join 性能比 clickhouse 要好一些
- 缺点:
- 单表查询性能相对于 clickhouse 差一点
8. StarRocks
参考链接:
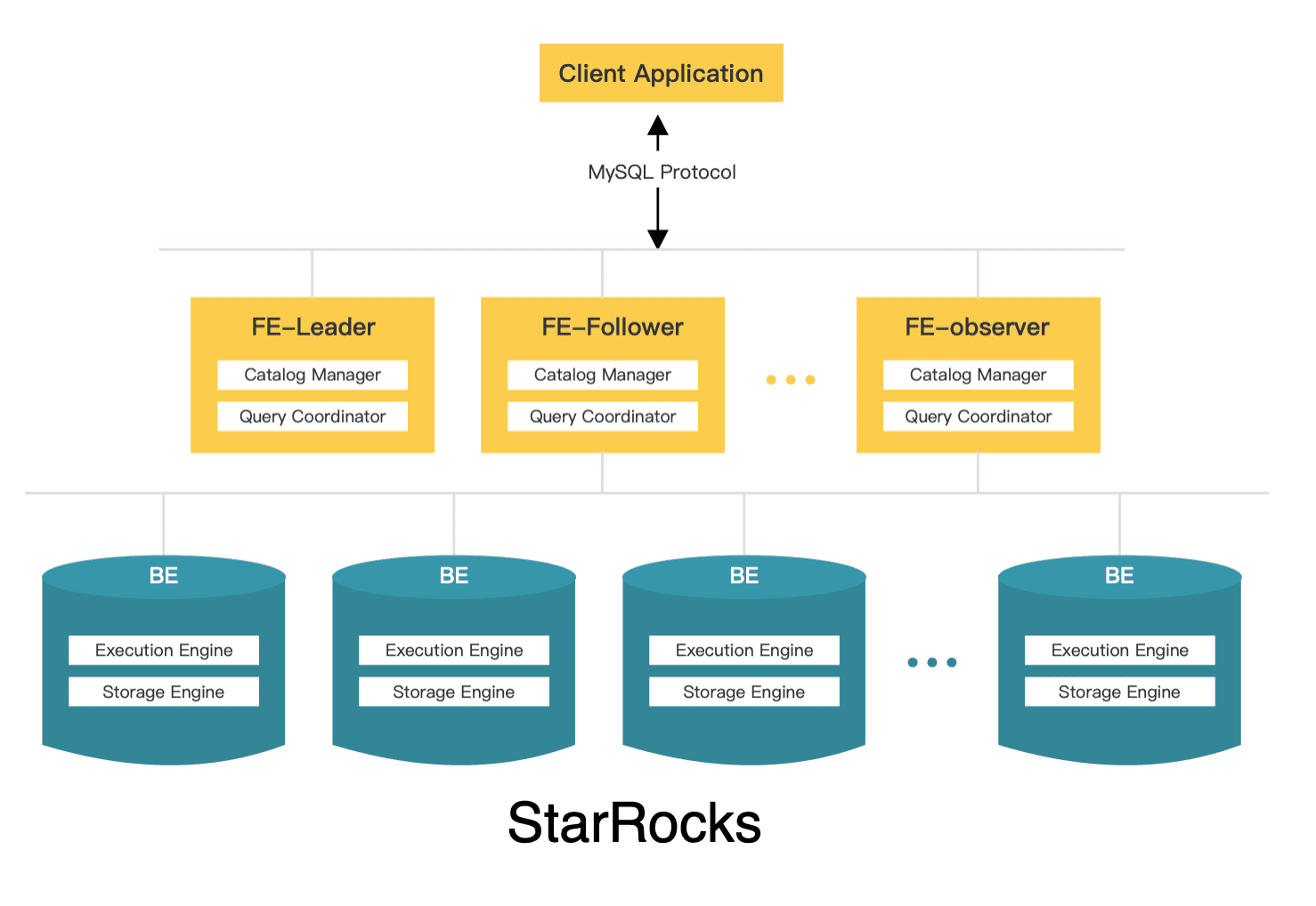
8.1 架构图
三、横向对比
| OLAP引擎 | 优点 | 缺点 | 自身存储 | 备注 |
|---|---|---|---|---|
| Hive | 1. 相对于 mr 提供了 sql 方式处理海量数据 2. 高可靠、高容错 | 查询效率相对较低 | 否 | |
| Presto | 1. 基于内存,节省大量io 2. 支持多种数据源,可以跨数据源连表查询 3. ANSI标准SQL | 1. 不支持UDF 2. 对内存要求高 | 否 | |
| Impala | 与 hive sql 的兼容性比 presto 要好一些 | 1. 低版本不支持 orc 格式,不支持某些 hive 的字段类型 2. 不支持 namenode federation 3. 安装部署成本高,官方给的安装方式是源码编译 | 否 | |
| Apache Kylin | 1. 与hadoop生态兼容最好固定模式查询,数据越多,性能越好 2. 只要命中cube,就可以亚秒级别返回 3. 社区活跃,且有商用版本 | 1. 不支持明细查询 2. 查询场景单一 3. 存储空间占用大 | 否 | |
| Druid | 1. 实时数据摄入 2. 列式存储+位图索引 3. 多租户+高并发 | 1. 使用门槛高 2. OLAP分场景性能差异大 3. 非标协议接口 | 是 | |
| Clickhouse | 1. 列式存储 2. 向量化引擎 3. CPU 利用率高,单机性能彪悍 | 1. 分布式集群在线扩展不佳 2. 运维成本高 3. 并发性能一般 | 是 | |
| Apache Doris | 1. Google Mesa+Apache Impala+Apache ORCFile 2. 支持主键更新 3. 高并发和高吞吐的ad-hoc查询 | 1. 成熟度不足 2. 应用不广泛 | 是 | |
| StarRocks | 同时拥有 ck 和 doris 的优点 | 实际性能待验证 | 是 |















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









