







Langchain+ChatGLM2实现本地知识问答平台
前言
最近比较流行chatgpt,刚好有资源可以测试一下,为了后续不迷路,记录一下。
准备工作
硬件:dell服务器,内存1T,显卡NVIDIA A100-SXM4-80GB * 4
软件:ubuntu 20.04,python 3.8, conda 22.9.0
搭建ChatGLM2服务
更新lfs
如果不想从互联网下载模型的话,可以不用装lfs,但是为了从0开始,还是需要安装一下,以便下载使用最新的模型。
apt update
apt install git-lfs
安装之后可能需要如下步骤才能安装git-lfs
git init
接着安装git-lfs
git lfs install
以上为常规操作,不贴图了。
创建虚拟环境
为了避免与其他python环境冲突,这里创建了一个虚拟环境p_chatglm2
conda create --name p_chatglm2 python=3.8
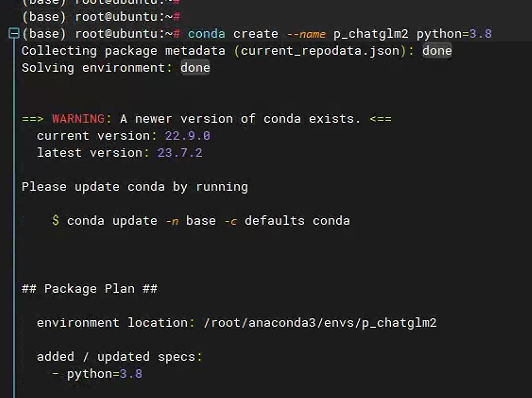
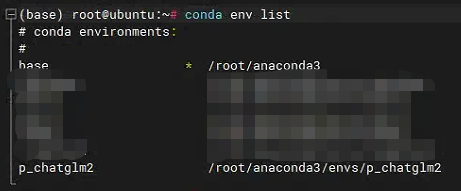
一直Y下去就可以了,创建之后检查一下是否创建成功。
conda env list
激活该虚拟环境
下载ChatGLM2
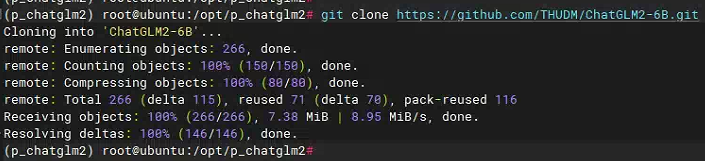
然后从github上下载最新的ChatGLM2。
git clone https://github.com/THUDM/ChatGLM2-6B.git
github的连接有些不顺畅,如果失败建议多试两次。
下载模型
接着下载模型文件,在p_chatglm2路径下创建model目录,然后把模型文件放在这个目录下。
然后下载对应的模型文件,文件比较大,需要一定的耐心。
cd model
git clone https://huggingface.co/THUDM/chatglm2-6b
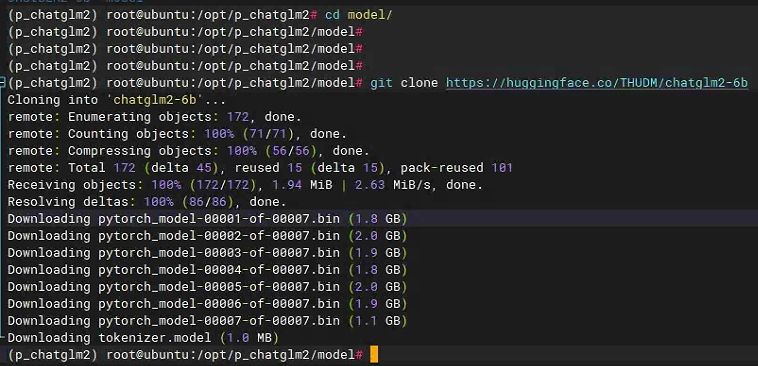
连接不稳定,需要多试几次,并保证下载成功,如果下载速度过慢,可以试试国内其他人提供的分享的网盘连接(链接:https://pan.baidu.com/s/1ovul-X2oR0BMp1uBVwDupg,提取码:kn6b)。
下载完成之后需要进入chatglm2-6b,安装依赖
pip install -r requirements.txt

修改web程序
打开web_demo.py,并修改相应的内容,找到如下内容:

把第7行中的内容修改为模型存放的位置,对于刚才的测试来说,可以修改为如下内容:
tokenizer = AutoTokenizer.from_pretrained("../model/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("../model/chatglm2-6b", trust_remote_code=True).cuda()
当修改为这个路径时,意味着执行脚本的时候需要在/opt/p_chatglm2/ChatGLM2-6B下执行,如果不是该目录,需要根据自己的路径进行修改。
另外由于我的机器有4个显卡,因此我可以根据实际状况进行如下修改。
tokenizer = AutoTokenizer.from_pretrained("../model/chatglm2-6b", trust_remote_code=True)
#model = AutoModel.from_pretrained("../model/chatglm2-6b", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
from utils import load_model_on_gpus
model = load_model_on_gpus("../model/chatglm2-6b", num_gpus=4)
model = model.eval()
同时为了实现远程访问,需要把最后一行修改如下:
demo.queue().launch(server_name="0.0.0.0", server_port=9091, share=False, inbrowser=True)
修改完成之后就可以执行
python3 web_demo.py

然后就可以通过浏览器访问该服务了。
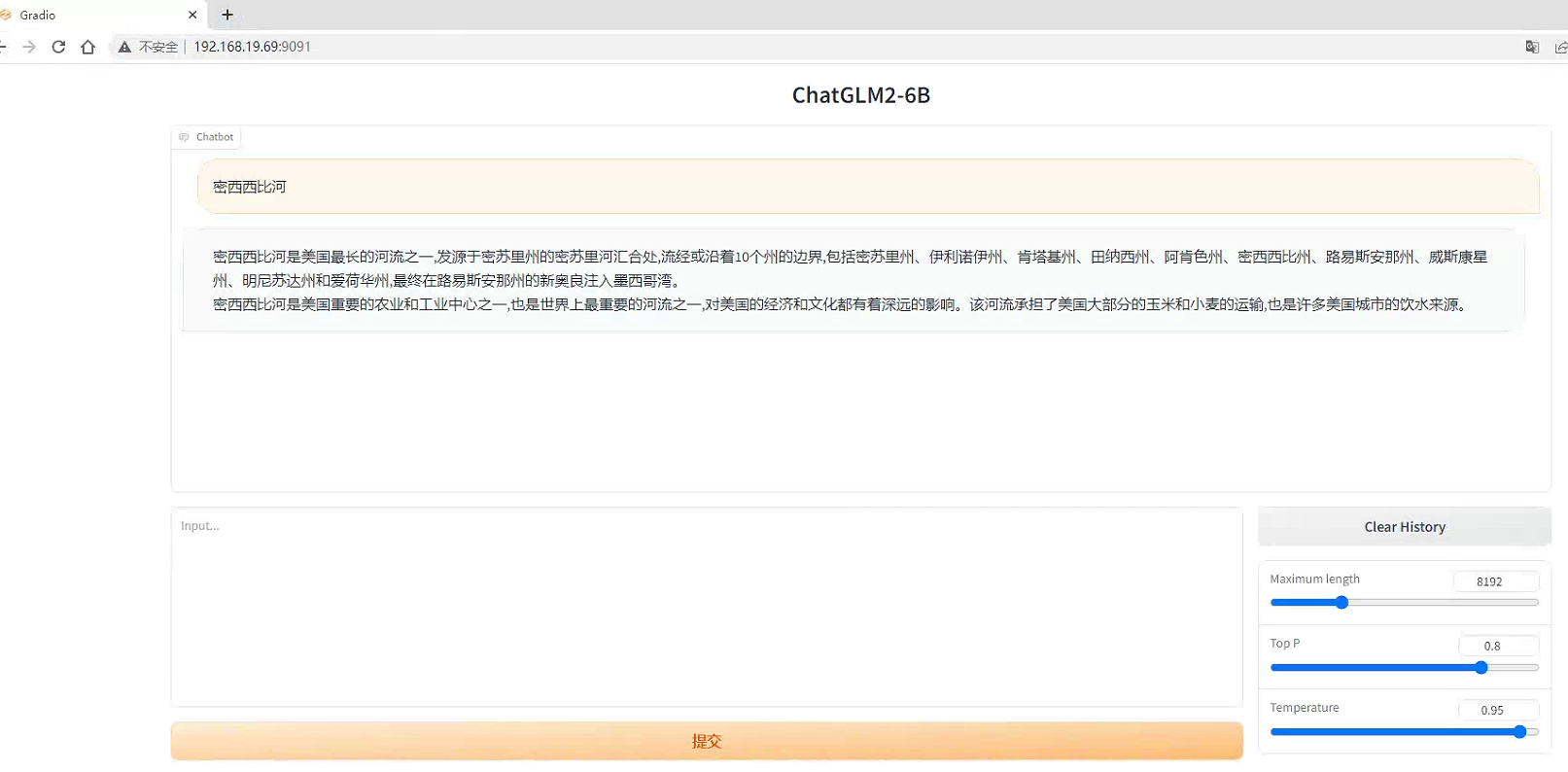
搭建Langchain+ChatGLM2服务
创建虚拟环境
创建虚拟环境p_lang
conda create --name p_lang python=3.8
激活环境
conda activate p_lang
下载模型
从GitHub上下载langchain-chatglm
git clone https://github.com/chatchat-space/langchain-ChatGLM.git
需要安装langchain所需的依赖文件
pip install -r requirements.txt
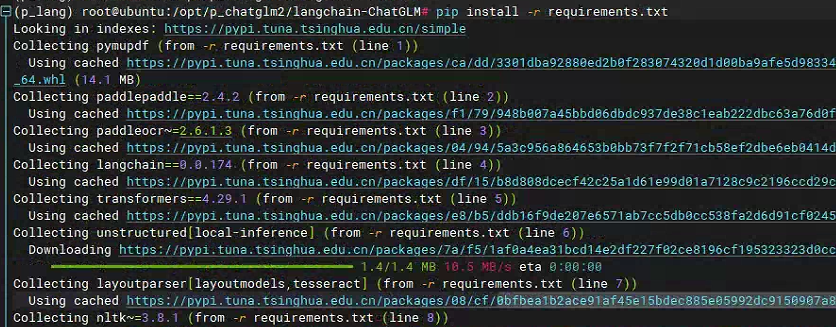
由于langchain需要执行一个embedding模型,因此需要下载对应的文档向量化模型,如configs/model_config.py文件中所示。
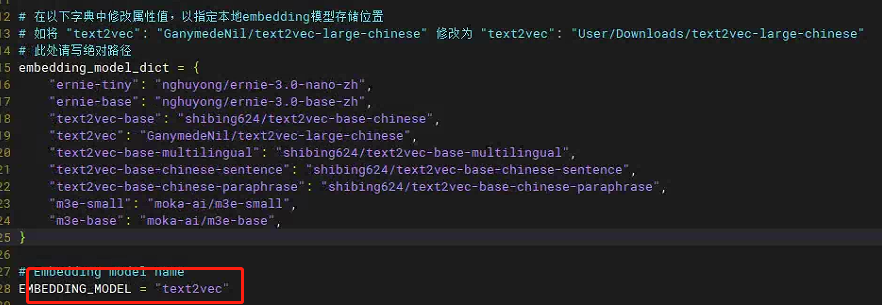
需要下载对应的模型
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese

需要修改configs/model_config.py中embedding模型的位置,由于text2vec-large-chinese模型在lanchain-ChaGLM路径下,且我们执行webui.py也是在这个目录下,因此不需要使用绝对路径。
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
# 修改下面这一行
"text2vec": "text2vec-large-chinese",
"text2vec-base-multilingual": "shibing624/text2vec-base-multilingual",
"text2vec-base-chinese-sentence": "shibing624/text2vec-base-chinese-sentence",
"text2vec-base-chinese-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
# Embedding model name
EMBEDDING_MODEL = "text2vec"
修改configs/model_config.py中LLM_MODEL模型
# LLM 名称
LLM_MODEL = "chatglm2-6b"
而模型chatglm2-6b定义在llm_model_dict中,对如下内容进行修改
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "THUDM/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLMLLMChain"
},
这里pretrained_model_name就是对应的模型,由于在ChatGLM2中已经下载了改模型,只需要找到具体的模型文件就行。相对于当前目录(/opt/p_chatglm2/langchain-ChatGLM),chatglm2-6b模型在../model中,因此修改如下:
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "../model/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLMLLMChain"
},
然后就可以执行web应用
python3 webui.py
如果执行过程中有缺什么工具,可以用pip install安装。执行结果如下:
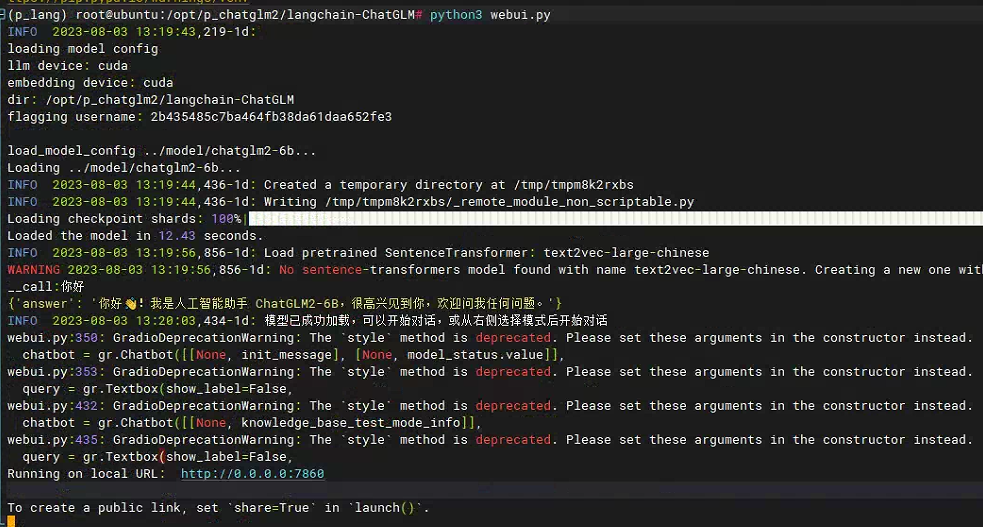
使用浏览器访问
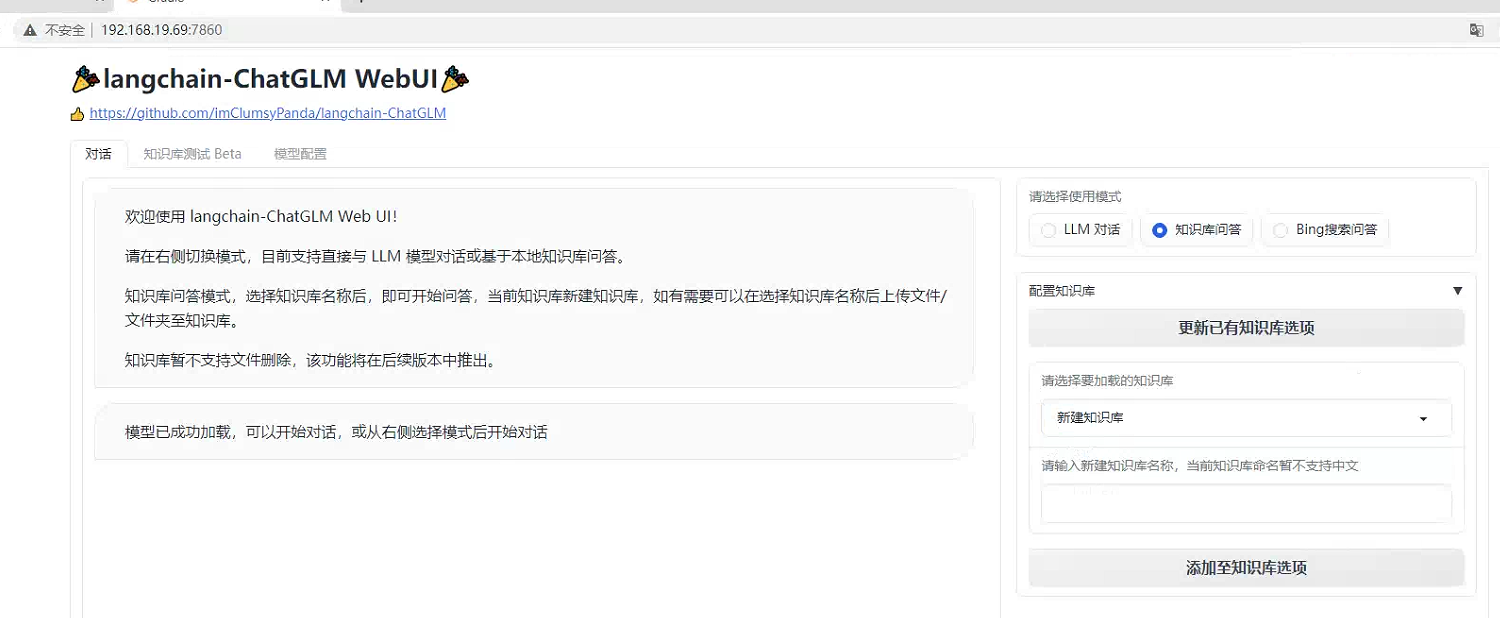
执行成功之后就可以构建本地知识库。
新建本地知识库,暂时这个名字好像只能是英文。
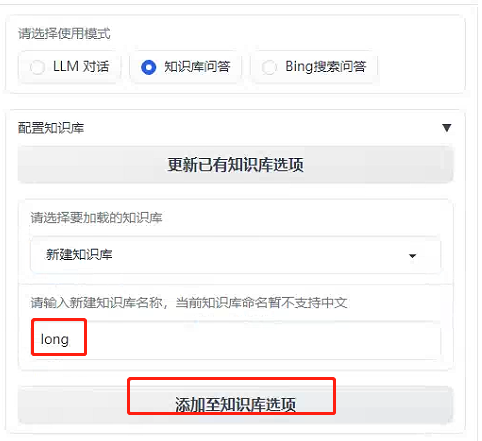
接着就需要上传文件
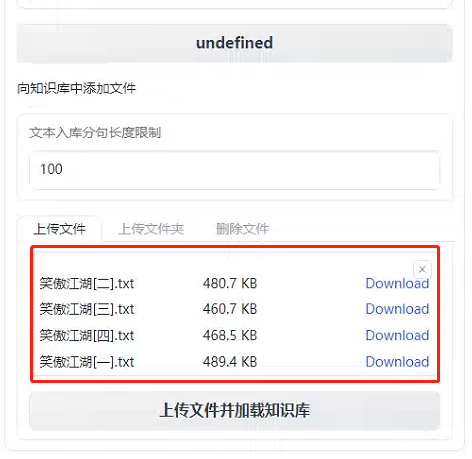
上传之后就可以加载知识库,等待模型将内容向量化,之后就可以进行测试了
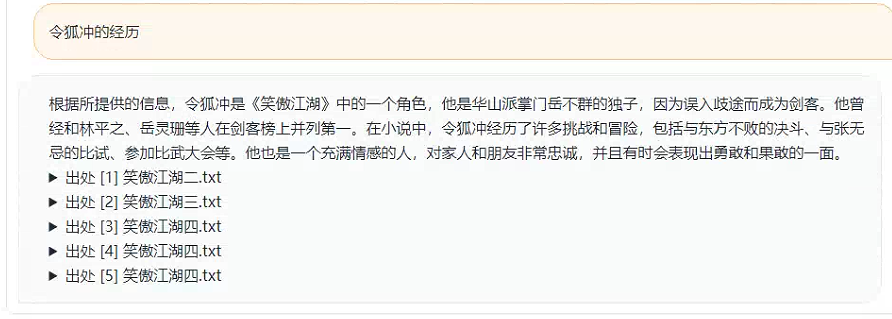
不过据我观察,这个结果实在是。。。嗯。。。一言难尽。后续我们会试一下meta的开源模型。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









