







谨以本文记录深度学习入门过程中学习的R-CNN系列,如有错误还请朋友不吝指教!
R-CNN
原论文:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN可以说是利用深度学习进行目标检测的开山之作。相比于传统方式,R-CNN使用CNN提取图像特征,并采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题(现实任务中,带标签的数据可能很少)。
算法流程
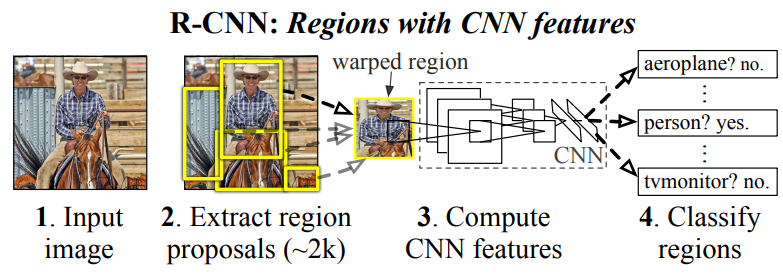
- 在一张图像上生成1k~2k个候选区域(使用Selective Search方法)
- 将每一个候选区域resize到一个固定的大小,输入到CNN深度网络中提取特征
- 将特征输入到预先训练好的SVM分类器中,判断是否属于该类别
- 使用回归器精细修正候选框位置
候选区域生成

利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体(上图中的黑框)。Selective Search算法跑在CPU上,相对来说是比较耗时的环节,这一点在Faster R-CNN中得到了优化。总的来说,R-CNN使用SS算法在每张图像上得到2000个候选框用于后续的处理。
提取候选区域特征
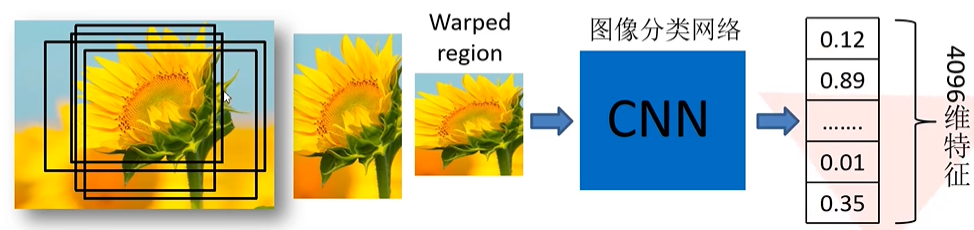
对每一个候选区域使用padding=16进行填充,忽略长宽比缩放到227×227,然后输入到预先训练好的AlexNet CNN网络(去除了最后的全连接层)中提取固定长度的图像特征向量,因为有2000个候选框,最后得到2000×4096维矩阵,,其中的每一行代表一个候选区域的特征向量。
PS:这里用于提取图像特征的深度网络使用其他的像ResNet等网络结构也是可以的。
从上图中可以看出,候选区域存在大量的重叠区域,因此在进行特征提取的时候,对相同的地方进行了大量重复的特征提取操作,这也导致了算法检测速度慢的问题。
SVM判定类别
假设有20种目标需要检测,我们将得到的2000×4096维的特征向量矩阵与20个预先训练好的SVM组成的权值矩阵4096×20相乘,获得2000×20维评分矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该类中得分最高的一些建议框。
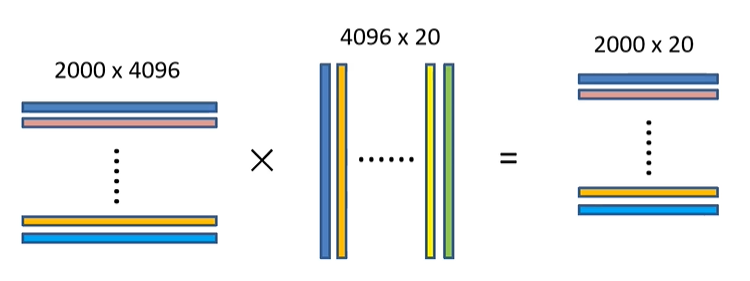
如上图所示,从左往右:
- 第一个矩阵中的每一行表示一个候选区域的特征向量,每个特征向量的长度为4096。
- 第二个矩阵中,每一列表示这一个类别的SVM的权值。
- 第三个矩阵中,每一行长度为20,,表示这个候选框属于对应20个类别的分类得分。
SVM训练:
- 使用的正样本是用CNN提取的GT的特征向量,负样本是CNN提取的IoU<0.3的候选区域的特征向量
- 因为负样本远多于正样本,正负样本不均衡;负样本太多增加内外存的压力,所以采用hard negative mining
修正候选框位置
对经过非极大值抑制处理后的建议框分别用20个回归器对上述20个类别中剩余的建议框及逆行边界框回归(即每个回归器对应一个类别),精细修正候选框的位置,具体来说就是让下图中的黄框尽可能的接近绿框。

下图中红框是算法生成的建议框,绿框是真实标记框,蓝色是红框经过边界框回归之后得到的预测框。每个框用 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)表示中心点坐标、宽和高。
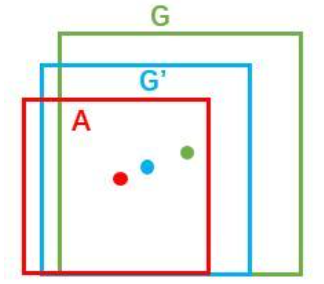
要将红框转换为绿框,有平移和缩放两种转换方式。这里用 ( x a , y a , w a , h a ) (x_a, y_a, w_a, h_a) (xa,ya,wa,ha)表示红色框,用 ( x , y , w , h ) (x, y, w, h) (x,y,w,h)表示真实框,那么从红框到绿框的真实的平移和缩放变换用公式表示如下所示:
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t w = l o g ( w / w a ) , t h = l o g ( h / h a ) \begin{aligned} & t_x= (x-x_a)/w_a , \quad t_y = (y-y_a)/h_a \\ & t_w = log(w/w_a) , \quad t_h = log(h/h_a) \\ \end{aligned} tx=(x−xa)/wa,ty=(y−ya)/hatw=log(w/wa),th=log(h/ha)
使用回归器对4个回归参数进行学习预测,对红框进行预测得到输出结果 ( d x , d y , d w , d h ) (d_x, d_y, d_w, d_h) (dx,dy,dw,dh),并通过对上述公式的反向计算得到蓝框(即精细修正后的预测框坐标):
x ′ = d x ⋅ w a + x a , y ′ = d y ⋅ h a + y a w ′ = e x p ( d w ) ⋅ w a , h ′ = e x p ( d h ) ⋅ h a \begin{aligned} & x'=d_x \cdot w_a+x_a, \quad y'=d_y \cdot h_a + y_a \\ & w'=exp(d_w)\cdot w_a, \quad h'=exp(d_h) \cdot h_a \\ \end{aligned} x′=dx⋅wa+xa,y′=dy⋅ha+yaw′=exp(dw)⋅wa,h′=exp(dh)⋅ha
在候选框与真实标记框相差很小时,
d
∗
d_*
d∗可以视为一种线性变化:
d
∗
=
w
∗
⊤
ϕ
(
A
)
d_*=w_*^{\top} \phi(A)
d∗=w∗⊤ϕ(A)
其中
ϕ
(
A
)
\phi(A)
ϕ(A)表示红色框提取的特征向量,从这里可以看出边界框回归的输入其实是候选框的特征,并不是候选框的中心点坐标以及宽和高。边界框回归的损失如下,用于衡量
t
∗
t_*
t∗和
d
∗
d_*
d∗之间的差距:
L
o
s
s
=
∑
i
N
(
t
∗
i
−
w
∗
⊤
⋅
ϕ
(
A
i
)
)
2
Loss=\sum^{N}_i(t^i_*-w_*^{\top} \cdot \phi(A^i))^2
Loss=i∑N(t∗i−w∗⊤⋅ϕ(Ai))2
R-CNN框架和流程

- 输入一张多目标图像,采用selective search算法提取约2000个候选框;
- 先在每个候选框周围加上16个像素值(为候选框的平均值,倾向于这个)的边框,再直接变形为227×227的大小(AlexNet的输入大小);
- 先将所有变换后的候选框减去自身平均值后,再依次将每个227×227的候选框输入AlexNet CNN网络获取4096维的特征,2000个候选框的CNN特征组合成2000×4096维矩阵;
- 将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个候选框是某个物体类别的得分;
- 分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠候选框,得到该列即该类中得分最高的一些候选框;
- 分别用20个回归器对上述20个类别中剩余的候选框进行回归操作,最终得到每个类别的修正后得分最高的检测框。
存在的问题
- 测试速度慢:测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时2s,而且在对候选框提取特征时存在大量的重复冗余操作。
- 训练速度慢:算法过程及其繁琐。
- 训练所需空间大:对于SVM和边界框回归,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。
能力有限,如有错误请各位朋友指正。本文内容从如下资料学习整理,感谢两位大佬的分享:
B站视频:视频传送门
https://zhuanlan.zhihu.com/p/30316608















 2164
2164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









