 神经网络深度解析:M-P模型到深度Boltzmann机
神经网络深度解析:M-P模型到深度Boltzmann机





神经网络
文章目录
参考
- 1、神经网络学习 之 M-P模型
- 2、机器学习-第五章神经网络读书笔记(周志华)
- 3、超平面是什么?——理解超平面(SVM开篇之超平面详解)
- 4、【手推机器学习】感知机与超平面
- 5、多层前馈神经网络及BP算法
- 6、周志华----第5章神经网络(误差逆传播算法)
- 7、【机器学习 面试题】为什么正则化可以防止过拟合?为什么L1正则化具有稀疏…
- 8、什么是 L1 L2 正规化 正则化 Regularization (深度学习 deep learning)
- 9、在机器学习中,L2正则化为什么能够缓过拟合?
- 10、机器学习中用来防止过拟合的方法有哪些?
- 11、模拟退火总结(模拟退火)
- 12、【优化】遗传算法介绍
- 13、【数之道14】六分钟时间,带你走近遗传算法
- 14、第42节:自适应共振理论网络(ART)——算法流程与ART I型网络的系统结构
- 15、【数之道 13】实现降维计算的另类神经网络
- 16、级联相关神经网络
- 17、什么是Jordan Elman Neural Networks?它与RNN是什么关系?
- 18、机器学习-白板推导系列(二十一)-受限玻尔兹曼机RBM(Restricted Boltzmann Machine)
- 19、【机器学习】白板推导系列(二十八) ~ 玻尔兹曼机(Boltzmann Machine)
- 20、【机器学习】白板推导系列(二十九) ~ 深度玻尔兹曼机(Deep Boltzmann Machine)
- 21、Boltzmann机详解
- 22、受限Boltzmann机详解
神经元模型
-
M-P模型( McCulloch-Pitts Model):1、神经网络学习 之 M-P模型
-
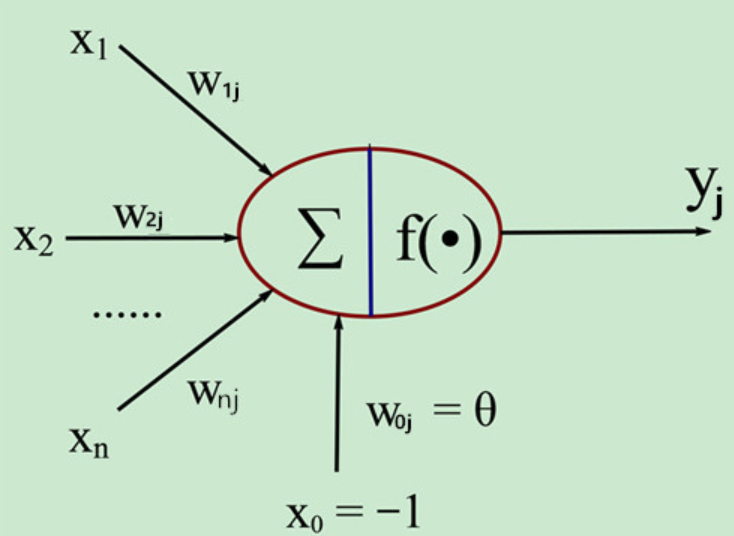
所谓M-P模型,其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型。
-
-
按照生物神经元,我们建立M-P模型,如上图所示。为了使得建模更加简单,以便于进行形式化表达,我们忽略时间整合作用、不应期等复杂因素,并把神经元的突触时延和强度当成常数。表达式为(其中f是sigmoid函数,Θ是偏差):
- y j = f ( ∑ i = 1 n W i j ∗ x i − θ ) y_j = f(\sum_{i=1}^n W_{ij}*x_i -\theta) y
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











